Hay varias formas de atacar el entreno de NPC usando inteligencia artificial mediante MLAgents. La mas sencilla, la que más funciona y la que más se usa es la de entrenar su comportamiento, pero siguiendo las normas de desarrollo de UNITY.
Es decir, si tenemos que mover el agente usamos cualquiera de las técnicas de movimiento que hem os venido usando hasta ahora. Con lo que la maquina controla las acciones del carácter, pero no como este las realiza. Si le dice qué gire, nosotros somos los responsables de usar la función Rotate. Qué queremos avanzar, pues llamamos a MoveTo. Es unity el que se encarga de mover el personaje y el motor de MLAgent decide cuándo avanzar o que acción tiene que realizar.

Pero hay otro enfoque! Creamos un personaje y el motor de MLAgents es el responsable de mover las piezas del personaje para crear las diferentes acciones. Vamos a ver si lo puedo explicar. En este caso el motor no decide qué acción tomar, sino que decide qué acción realizara cada uno de los miembros de nuestro personaje. Vamos un paso más lejos.
Pensemos en nosotros mismos, cuando nos ponemos a andar, no pensamos en levantar la pierna, doblar la rodilla, apoyar el pie. Tan solo pensamos la dirección, nos giramos y nos dirigimos hacia donde sea que queramos ir.
Bien, pues el segundo enfoque, el que intenta darle al motor de MLAgents el control de las articulaciones, que podríamos llamar nivel de Inteligencia Artificial Inconsciente, ya que simula las acciones que tomamos de forma inconsciente. Requiere de un enfoque totalmente diferente al primero. Necesitamos definir el entorno de otra manera….. y este ha sido mi fallo.
Concretemos mas, respuesta directa a la pregunta: ¿Cual crees que ha sido el error en la definición del entorno del agente, que le ha impedido aprender?
Los premios! Principalmente, y entre otros, pero principalmente ha sido la escasa definición de premios, ninguno de ellos con una relación directa a las acciones que podia tomar el agente.
No ha sido hasta que ya he completado unos 20 o 30 procesos de aprendizaje infructuosos que no he pensado…. le doy premios cuando llega a destino, y no sabe ni andar, tendría que premiar aquellas acciones que le ayuden a andar. Es decir, se deben decidir unos premios que tengan que ver con el modo de uso de las articulaciones de los miembros del agente. Unos pequeños premios para cuando consiga un resultado. Pero no cuando llegue a destino, ni cuando se desplace hacia él. El mero hecho de que el agente consiga desplazarse ya tendría que generarle un premio. Por que recordemos. que nuestro motor de inteligencia artificial nace siendo completamente estupido. No parte de nuestros miles de años de evolución. Cuando un niño tiene que coger algo, ya lo intenta con la mano, no lo intenta con la oreja. Nuestros agentes no saben nada del mundo, no tienen historia. Se dedican a mover a lo loco lo que nosotros como dioses de pega, o diseñadores de pacotilla, les damos.
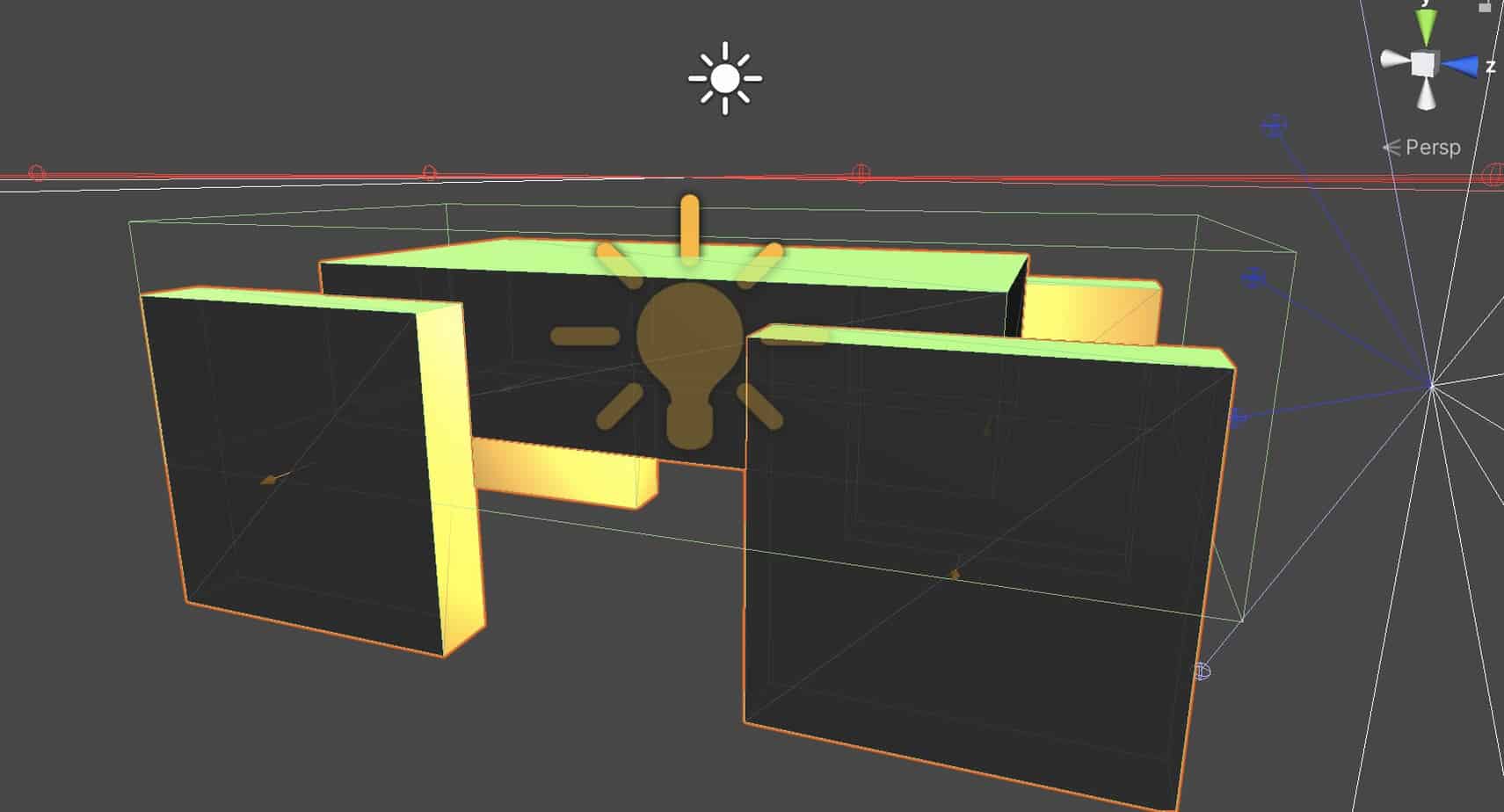
Resumiendo. Es un agente sencillo, compuesto por un rectángulo, unido a cuatro cuadrados mediante sus respectivos hinge joint, y con una suspensión. La forma de avanzar es aplicando fuerza con los cuadrados, o haciéndolos girar. A mi me ha resultado mas o menos sencillo controlar el agente de forma heuristica, es decir, dando yo las ordenes mediante entradas. Pero al motor de MLAgent, le ha sido totalmente imposible. Lo ha intentado, en lugar de avanzar, se ponía de pie y se dejaba caer en un intento de alcanzar el target… pero el resultado ha sido pauperrimo.
No hace falta mirar el fichero .yaml, ni el entorno. Solo diré que ha faltado la definición de los premios… y la observación de donde están los miembros del agente respecto a su cuerpo.
O eso creo 🙂
Comments