
En el artículo anterior, aprendimos a montar un prompt que era capaz de generar órdenes SQL desde peticiones realizadas en lenguaje natural por parte del Usuario.
Ahora veremos como utilizar Azure OpenAI Studio para crear un punto de inferencia al que podamos llamar y crear las órdenes SQL.
Aunque posiblemente si estáis leyendo estas líneas ya cumpláis los requisitos, os recuerdo que es necesario disponer de:
- Una suscripción a Azure. Es gratuita y si la dais de alta por primera vez vendrá con unos créditos gratuitos. Crear subscripción Azure.
- Acceso a los recursos de OpenAI. Por ahora Microsoft aún los mantiene bajo petición. Pero se han rebajado mucho los requisitos y el tiempo de espera. El formulario da más miedo de lo que debería. Yo pedi acceso usando el mail de un dominio que tengo registrado, he indicado que quería información para hacer un curso. Me dieron acceso casi de inmediato. Pedir acceso a Azure OpenAI Studio.
Lo más posible es que en breve desaparezca la necesidad de pedir acceso, así que, yo probaría igualmente, aunque no hayáis tramitado el permiso.
Configurando Azure OpenAI Studio.
Podemos acceder directamente desde el portal de azure: https://portal.azure.com/#home

Una vez dentro en servicios tenemos que seleccionar Azure AI Services.
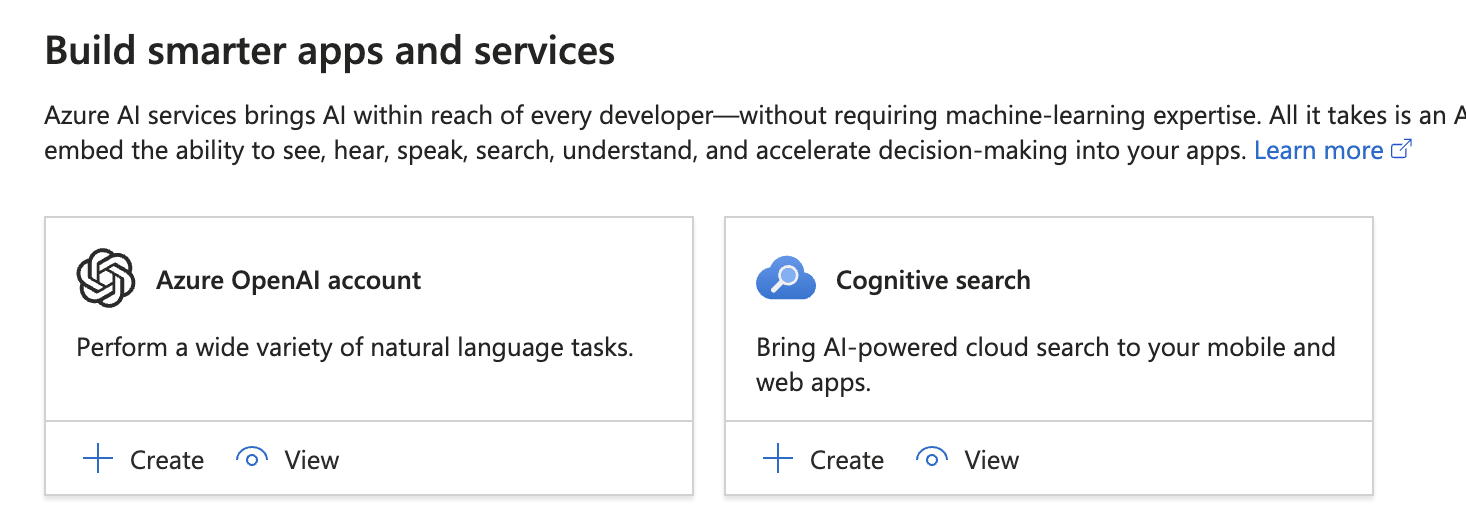
Entramos en Azure OpenAI Account.
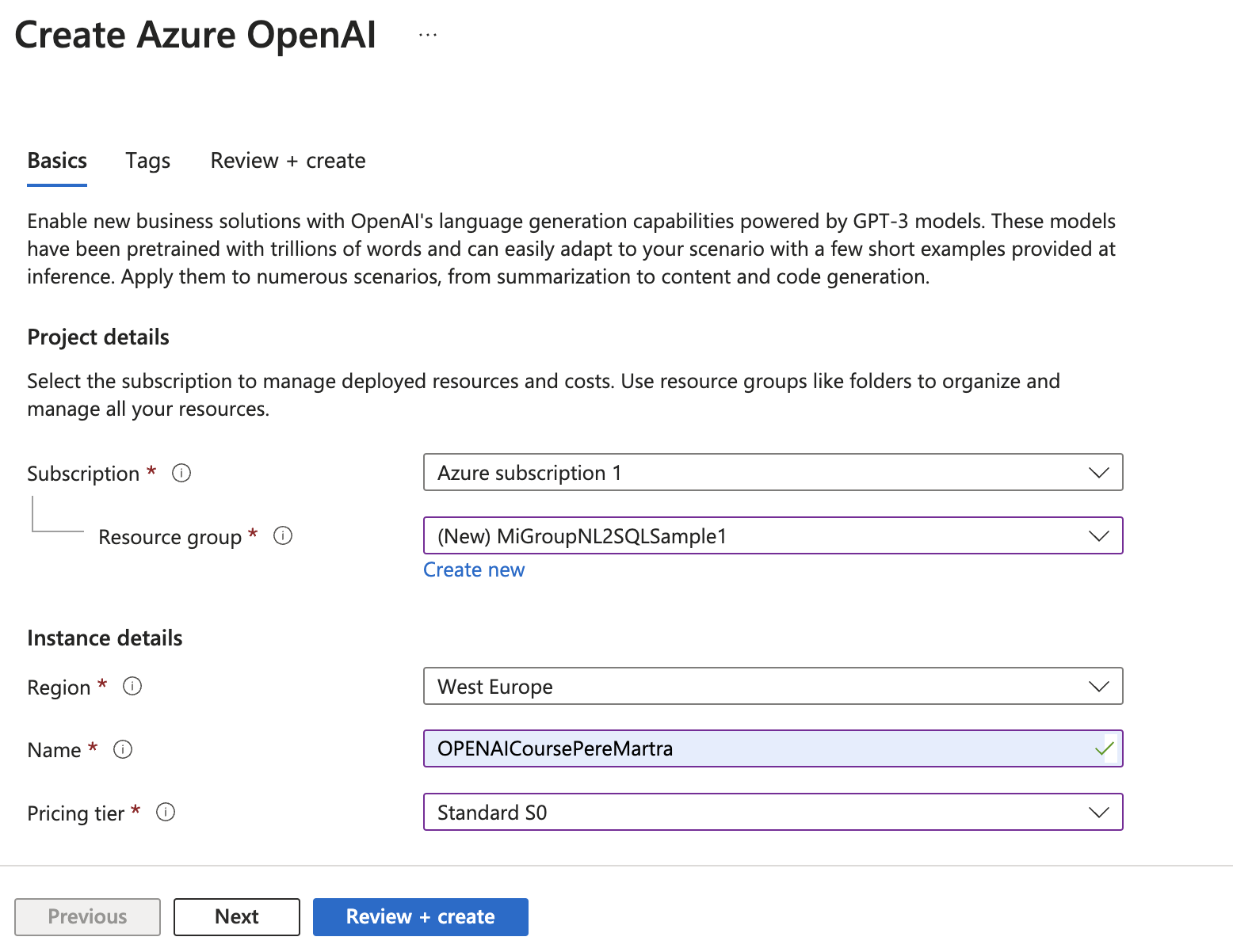
En esta pantalla tenemos que escoger la Suscripción. Si tenéis una de estudiante, lo más posible es que no funcione. Cread otra.
Como resource-group, yo crearía uno nuevo. Ponedle el nombre que queráis. Es tan solo una agrupación lógica que mantendrá todos los recursos bajo un mismo grupo. De esta forma eliminando el grupo elimináis todos los recursos creados, sin afectar a ningún otro recurso. Ya que se trata de tan solo un proyecto temporal, es bueno eliminarlo para que no conlleve ningún coste.
En Region, yo escogería la más cercana a vuestra zona. Azure tan solo os muestra las regiones que tienen los OpenAI Services disponibles.
En Name un nombre único para el proyecto.
En Pricing Tier, escoged Standard S0. Posiblemente, sea la única opción que tengáis.
Con esto ya podemos pulsar el botón Review+Create, os mostrará los datos, los validáis, y ya podemos empezar a disfrutar.
La configuración tarda unos pocos minutos, al finalizar no saldrá una pantalla parecida a esta:
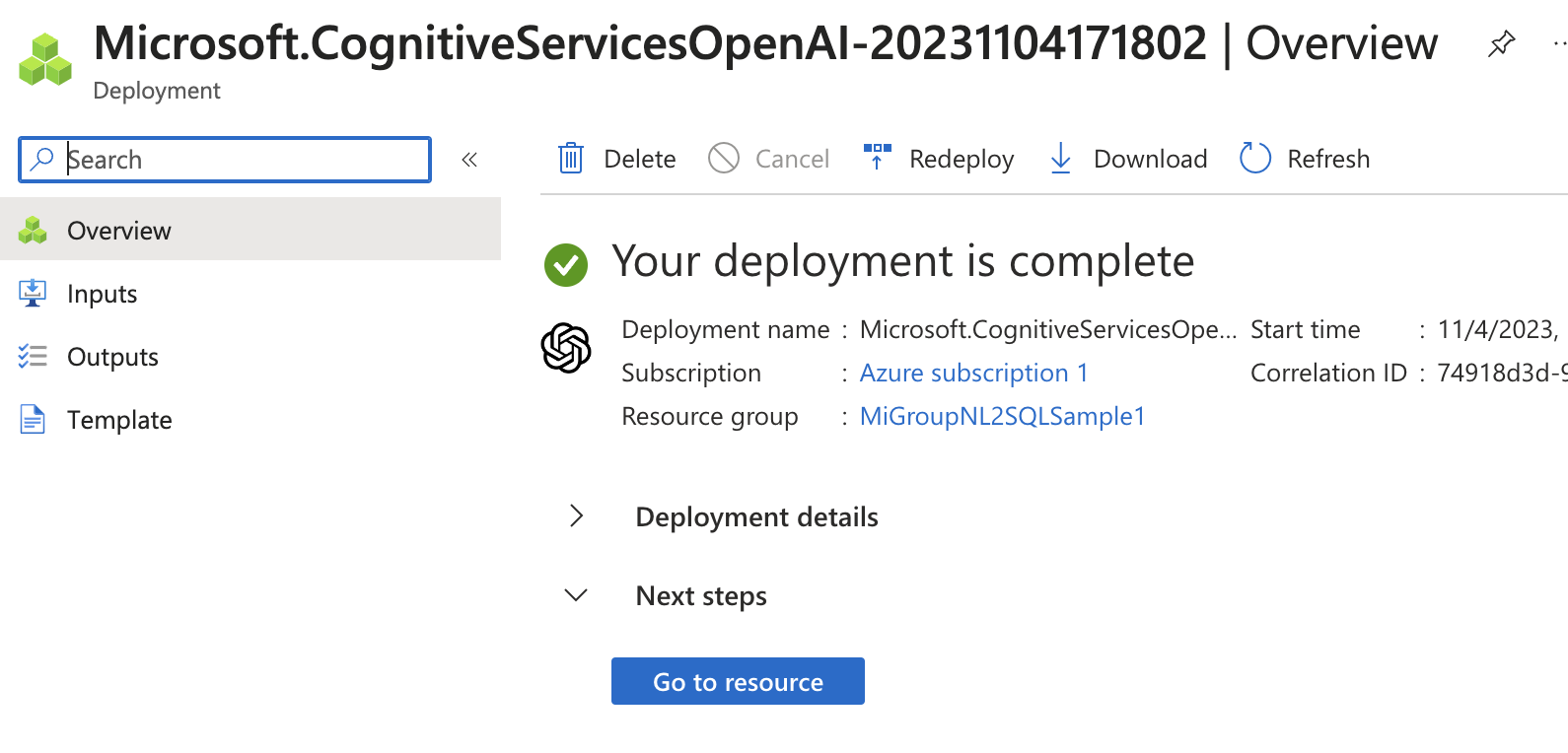
Pulsamos sobre Go to Resource.
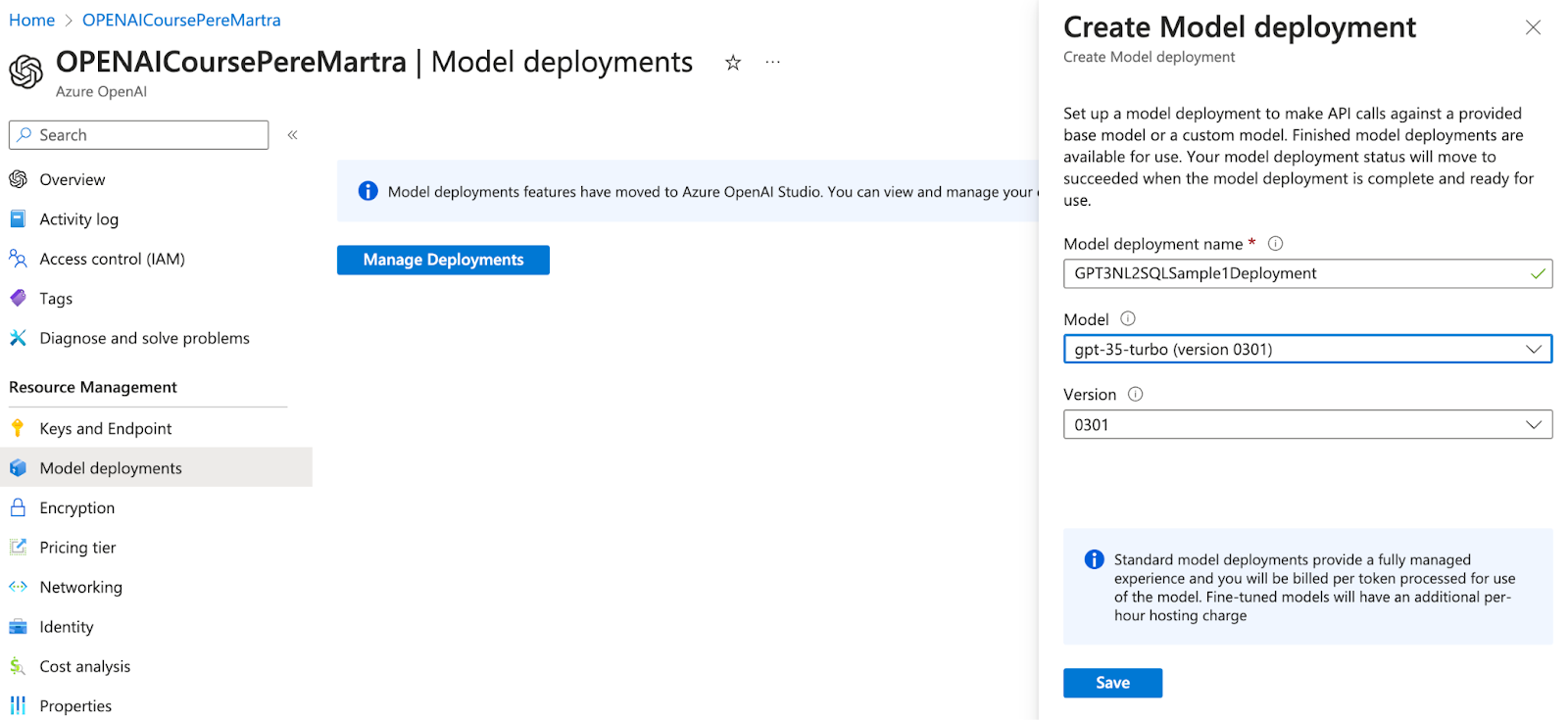
Ahora ya podemos crear un nuevo despliegue de un modelo desde la sección Model Deployments. Tan solo tenemos que darle un nombre y escoger el modelo: GTP-3.5-Turbo.
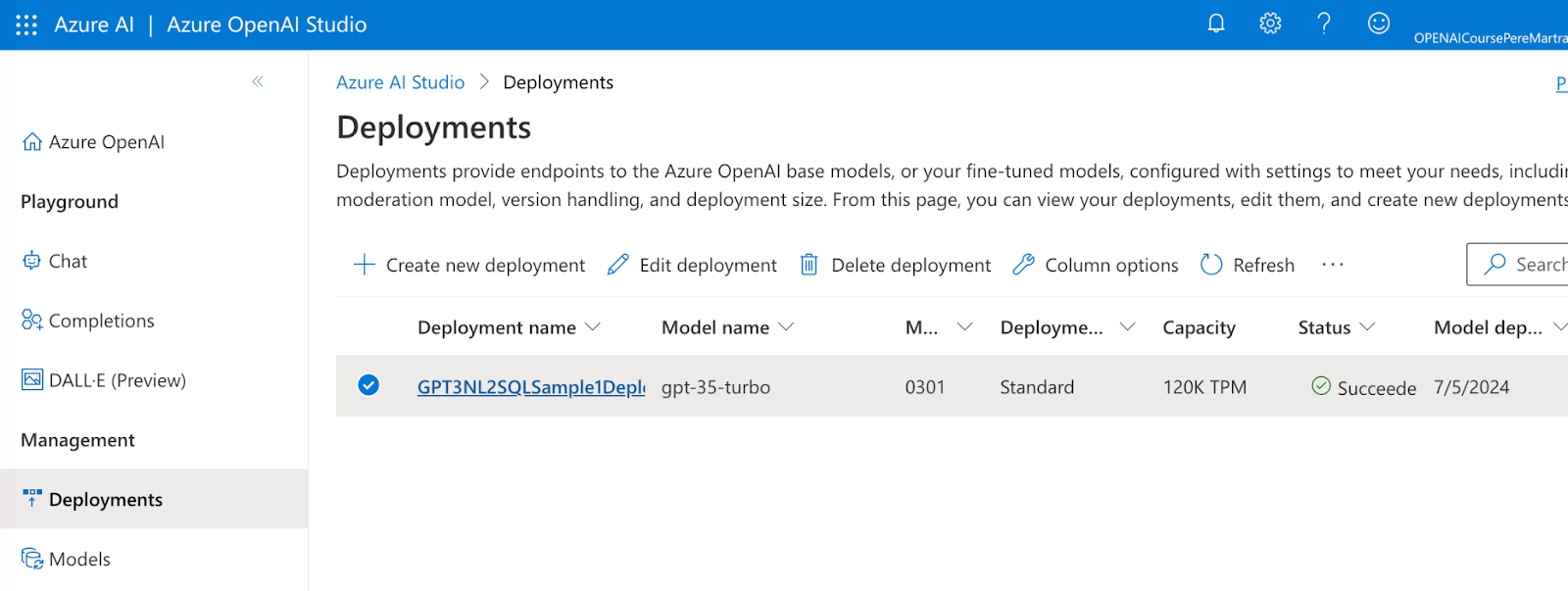
En unos pocos segundos Azure OpenAI Studio preparará el despliegue del modelo.
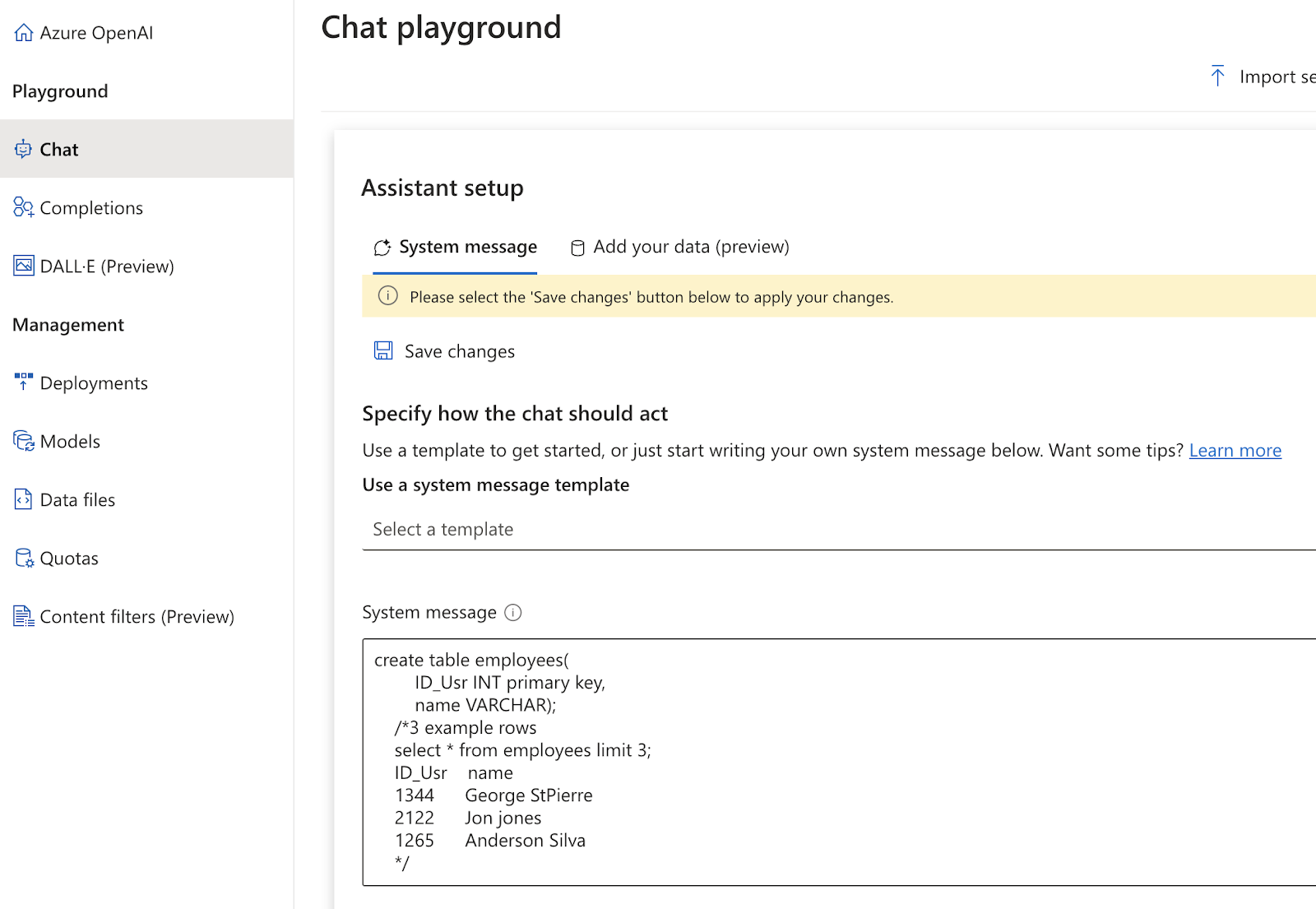
En el apartado de PlayGround, seleccionamos Chat, y ya podemos empezar a informar nuestro prompt.
El prompt lo hemos creado siguiendo el paper ‘How to Prompt LLMs for Text-to-SQL: A Study in Zero-shot, Single-domain, and Cross-domain Settings.
create table employees(
ID_Usr INT primary key,
name VARCHAR);
/*3 example rows
select * from employees limit 3;
ID_Usr name
1344 George StPierre
2122 Jon jones
1265 Anderson Silva
*/
create table salary(
ID_Usr INT,
year DATE,
salary FLOAT,
foreign key (ID_Usr) references employees(ID_Usr));
/*3 example rows
select * from salary limit 3
ID_Usr date salary
1344 01/01/2023 61000
1344 01/01/2022 60000
1265 01/01/2023 55000
*/
create table studies(
ID_study INT,
ID_Usr INT,
educational_level INT, /* 5=phd, 4=Master, 3=Bachelor */
Institution VARCHAR,
Years DATE,
Speciality VARCHAR,
primary key (ID_study, ID_Usr),
foreign key(ID_Usr) references employees (ID_Usr));
/*3 example rows
select * from studies limit 3
ID_Study ID_Usr educational_level Institution Years Speciality
2782 1344 3 UC San Diego 01/01/2010 Bachelor of Science in Marketing
2334 1344 5 MIT 01/01/2023 Phd. Data Science.
2782 2122 3 UC San Diego 01/01/2010 Bachelor of Science in Marketing
*/
-Maintain the SQL order simple and efficient as you can, using valid SQL Lite, answer the following questions for the table provided above.
Question: How Many employes we have with a salary bigger than 50000?
SELECT COUNT(*) AS total_employees
FROM employees e
INNER JOIN salary s ON e.ID_Usr = s.ID_Usr
WHERE s.salary > 50000;
Question: Return the names of the three people who have had the highest salary increase in the last three years.
SELECT e.name
FROM employees e
JOIN salary s ON e.ID_usr = s.ID_usr
WHERE s.year >= DATE_SUB(CURDATE(), INTERVAL 3 YEAR)
GROUP BY e.name
ORDER BY (MAX(s.salary) - MIN(s.salary)) DESC
LIMIT 3;
Question: The name of the best paid employee.
Este es nuestro prompt completo, vamos a tener que dividirlo en partes para situar cada parte en su correspondiente casilla.
En la casilla system Message Pondremos el prompt entero a execpcion de los ejemplos:
create table employees(
ID_Usr INT primary key,
name VARCHAR);
/*3 example rows
select * from employees limit 3;
ID_Usr name
1344 George StPierre
2122 Jon jones
1265 Anderson Silva
*/
create table salary(
ID_Usr INT,
year DATE,
salary FLOAT,
foreign key (ID_Usr) references employees(ID_Usr));
/*3 example rows
select * from salary limit 3
ID_Usr date salary
1344 01/01/2023 61000
1344 01/01/2022 60000
1265 01/01/2023 55000
*/
create table studies(
ID_study INT,
ID_Usr INT,
educational_level INT, /* 5=phd, 4=Master, 3=Bachelor */
Institution VARCHAR,
Years DATE,
Speciality VARCHAR,
primary key (ID_study, ID_Usr),
foreign key(ID_Usr) references employees (ID_Usr));
/*3 example rows
select * from studies limit 3
ID_Study ID_Usr educational_level Institution Years Speciality
2782 1344 3 UC San Diego 01/01/2010 Bachelor of Science in Marketing
2334 1344 5 MIT 01/01/2023 Phd. Data Science.
2782 2122 3 UC San Diego 01/01/2010 Bachelor of Science in Marketing
*/
-Maintain the SQL order simple and efficient as you can, using valid SQL Lite, answer the following questions for the table provided above.
En esta sección le damos la estructura de la base de datos, unos ejemplos de su contenido y las instrucciones para que el modelo genere las ordenes SQL.
Ahora tocaría rellenar la sección Examples con los los ejemplos de nuestro prompy. En el prompt original tenemos dos ejemplos:
Question: How Many employes we have with a salary bigger than 50000? SELECT COUNT(*) AS total_employees FROM employees e INNER JOIN salary s ON e.ID_Usr = s.ID_Usr WHERE s.salary > 50000; Question: Return the names of the three people who have had the highest salary increase in the last three years. SELECT e.name FROM employees e JOIN salary s ON e.ID_usr = s.ID_usr WHERE s.year >= DATE_SUB(CURDATE(), INTERVAL 3 YEAR) GROUP BY e.name ORDER BY (MAX(s.salary) - MIN(s.salary)) DESC LIMIT 3; Question: The name of the best paid employee.
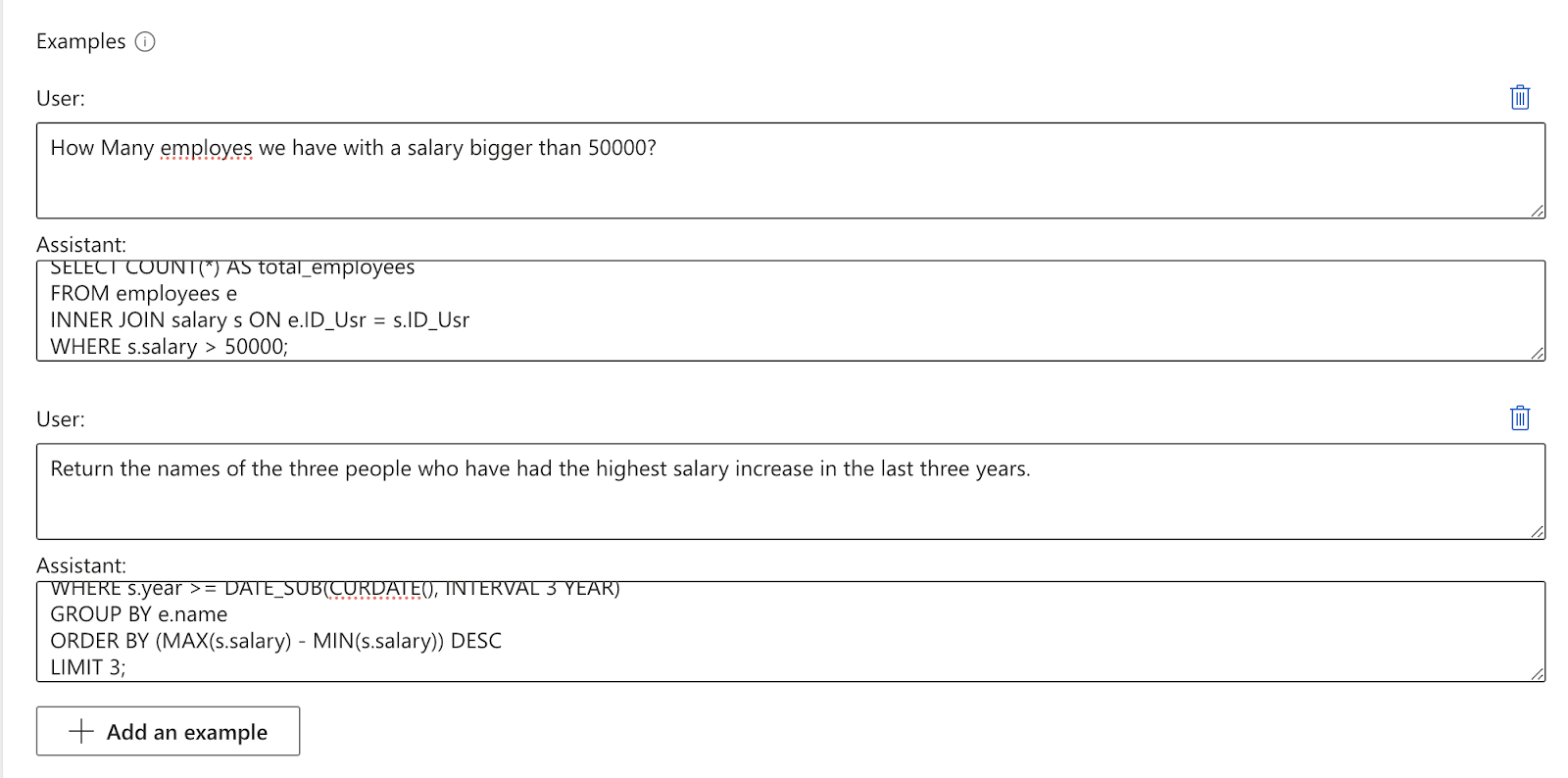
Como veis hemos creado un ejemplo por cada orden. Esta técnica es conocida como few shot sample y le permite al modelo hacerse una idea de cómo debe responder a las peticiones del usuario. Un número de ejemplos correcto suele estar entre uno y seis, más no tienen un efecto positivo en la respuesta que ofrece el modelo.
Ahora ya podemos empezar a realizar pruebas.
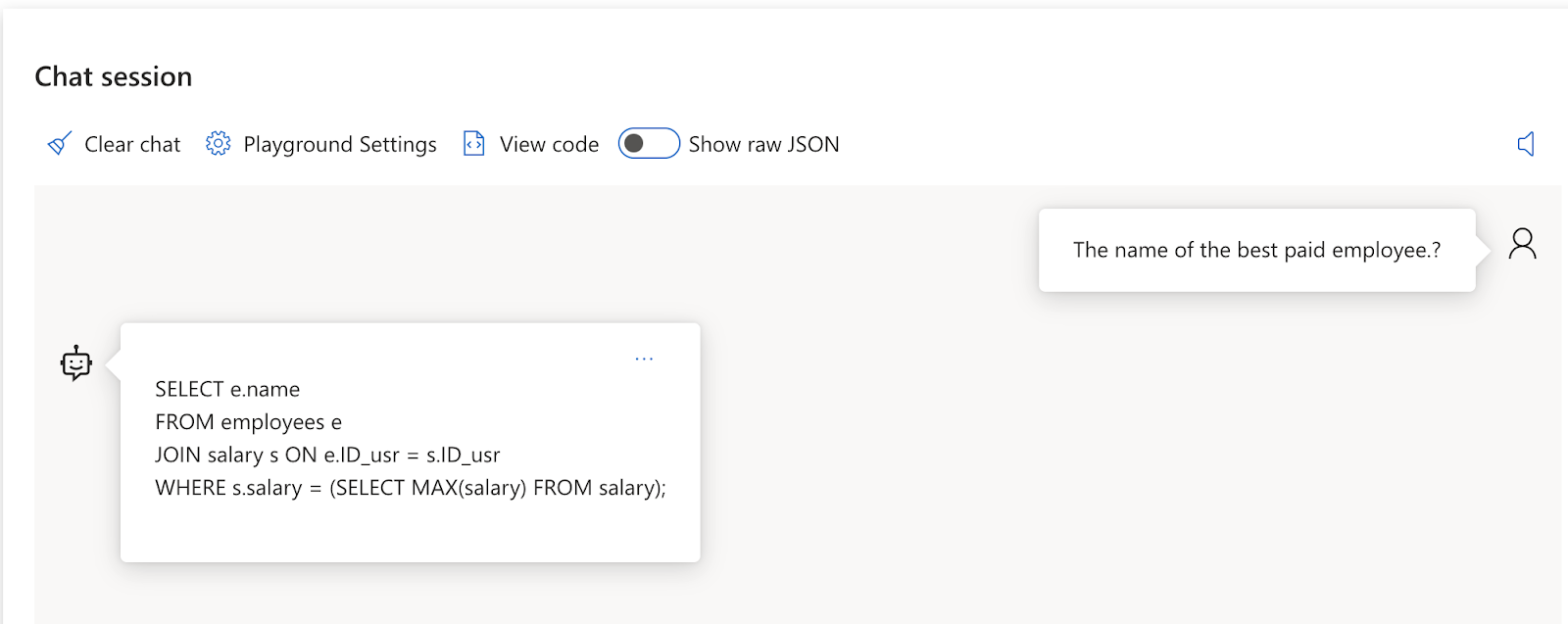
También podemos modificar la configuración de los hyperparametros.

Para generación de código recomiendo usar una Temperature de 0. No hace falta que el modelo sea muy imaginativo con sus respuestas.
A partir de aquí, si las respuestas nos gustan, podemos hacer dos cosas:
- Exportar la configuración. Nos guardará un fichero que podemos usar para volver a configurar el Playground.
- Pulsar en Ver Código, donde nos dará un código de ejemplo para llamar a nuestro Modelo.
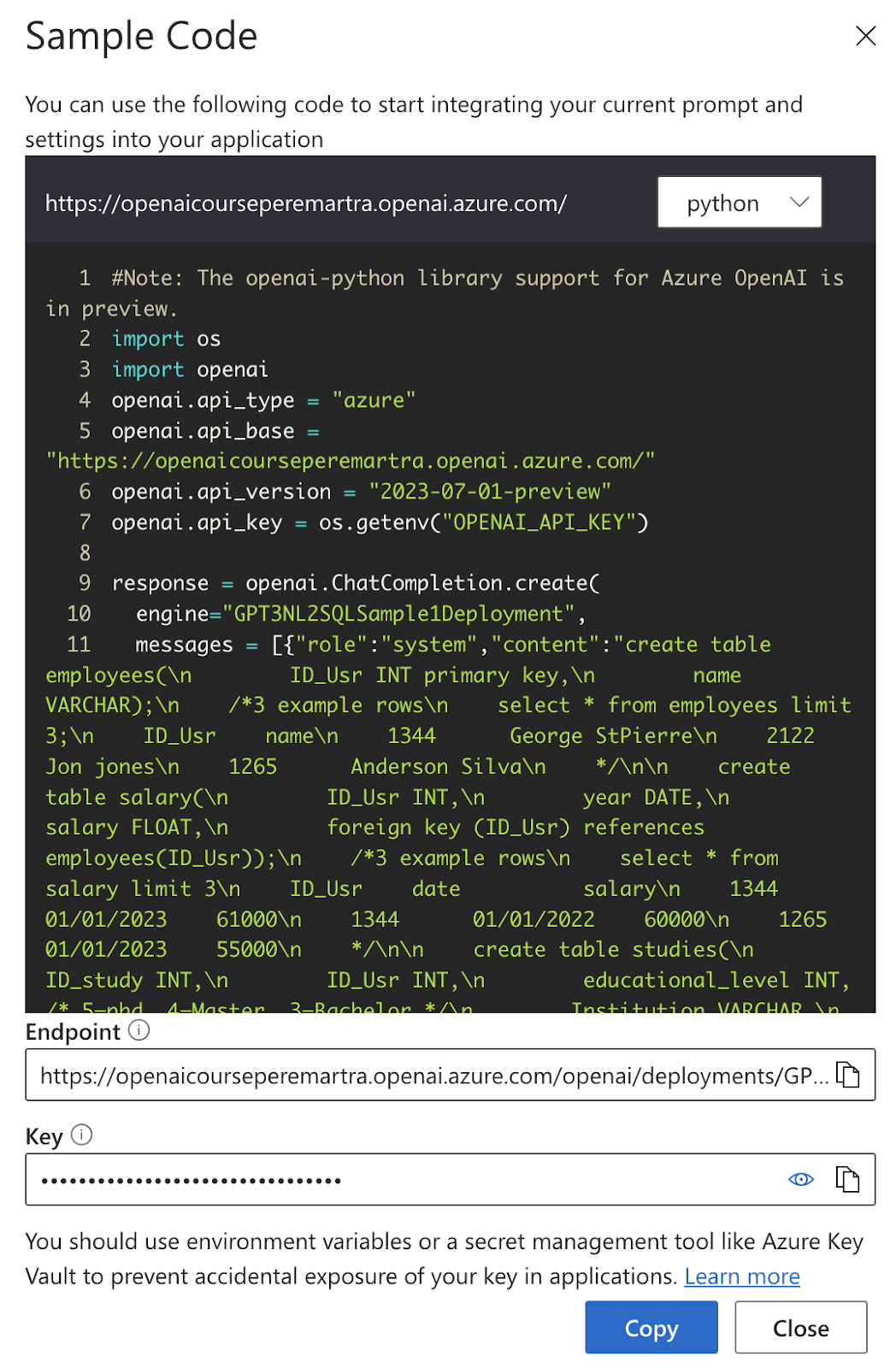
El Notebook usando el Modelo.
El Notebook lo tenéis disponible en el repositorio del curso de Grandes Modelos de Lenguaje.
Empezamos instalado e importando la librería de OpenAI.
#Install openai !pip install -q "openai<1.0.0" import os import openai
Ahora tenemos que configurar nuestro Acceso a Azure.
#Azure configuration openai.api_type = "azure" #Here the inference point that you can get from Azure openai.api_base = "https://openaicourseperemartra.openai.azure.com/" openai.api_version = "2023-07-01-preview" openai.api_key = "your-azure-openai-key"
Informamos del prompt:
context = [ {'role':'system', 'content':"""
create table employees(
ID_Usr INT primary key,
name VARCHAR
);
/* 3 example rows
select * from employees limit 3;
ID_Usr name
1344 George StPierre
2122 Jon jones
1265 Anderson Silva
*/
create table salary(
ID_Usr INT,
year DATE,
salary FLOAT,
foreign key (ID_Usr) references employees(ID_Usr)
);
/* 3 example rows
select * from salary limit 3
ID_Usr date salary
1344 01/01/2023 61000
1344 01/01/2022 60000
1265 01/01/2023 55000
*/
create table studies(
ID_study INT,
ID_Usr INT,
educational_level INT, /* 5=phd, 4=Master, 3=Bachelor */
Institution VARCHAR,
Years DATE,
Speciality VARCHAR,
primary key (ID_study, ID_Usr),
foreign key(ID_Usr) references employees (ID_Usr)
);
/* 3 example rows
select * from studies limit 3
ID_Study ID_Usr educational_level Institution Years Speciality
2782 1344 3 UC San Diego 01/01/2010 Bachelor of Science in Marketing
2334 1344 5 MIT 01/01/2023 Phd. Data Science.
2782 2122 3 UC San Diego 01/01/2010 Bachelor of Science in Marketing
*/
-Maintain the SQL order simple and efficient as you can, using valid SQL Lite, answer the following questions for the table provided above.
Question: How Many employees do we have with a salary bigger than 50000?
SELECT COUNT(*) AS total_employees
FROM employees e
INNER JOIN salary s ON e.ID_Usr = s.ID_Usr
WHERE s.salary > 50000;
Question: Return the names of the three people who have had the highest salary increase in the last three years.
SELECT e.name
FROM employees e
JOIN salary s ON e.ID_Usr = s.ID_Usr
WHERE s.year >= DATE_SUB(CURDATE(), INTERVAL 3 YEAR)
GROUP BY e.name
ORDER BY (MAX(s.salary) - MIN(s.salary)) DESC
LIMIT 3;
"""} ]
Creo una función para encapsular la llamada al modelo.
#Functio to call the model.
def return_CCRMSQL(user_message, context):
newcontext = context.copy()
newcontext.append({'role':'user', 'content':"question: " + user_message})
response = openai.ChatCompletion.create(
engine="GPT3NL2SQLSample1Deployment", #Our deployment
messages = newcontext,
temperature=0,
max_tokens=800)
return (response.choices[0].message["content"])
Ahora ya podemos hacer las pruebas pertinentes y obtener el código SQL para interrogar nuestra base de datos:
context_user = context.copy()
print(return_CCRMSQL("The name of the employee best paid", context_user))
SELECT e.name FROM employees e JOIN salary s ON e.ID_usr = s.ID_usr WHERE s.salary = (SELECT MAX(salary) FROM salary); This query will return the name of the employee with the highest salary.
print(return_CCRMSQL("Return the Institution with a higher average salary", context_user))
SELECT st.Institution, AVG(sa.salary) AS avg_salary FROM studies st JOIN employees e ON st.ID_Usr = e.ID_Usr JOIN salary sa ON e.ID_Usr = sa.ID_Usr GROUP BY st.Institution ORDER BY avg_salary DESC LIMIT 1;
Conclusiones
Cuando ya tenemos claro que prompt utilizar, configurar Azure OpenAI Services y usar los modelos de OpenAI residentes en Azure en lugar del API de OpenAI es una tarea sencilla.
La decisión de usar uno u otro dependerá de las decisiones de nuestra empresa. Los Modelos de OpenAI que se usan a través de Azure Open Services no residen en OpenAI. Es decir, que los datos que les pasamos no salen nunca de nuestra suscripción de Azure, y nunca serán usados para entrenar modelos futuros de OpenAI.
Técnicamente, las diferencias son mínimas y la complejidad es inexistente.