
Lora Nos permite fine-tunear un modelo modificando tan solo una pequeña porción de sus pesos. La cuantización es una técnica que nos permite reducir el peso de un modelo cuando lo cargamos en memoria.
Si juntamos las dos técnicas podemos cargar un gran modelo de lenguaje en mucha menos memoria de la que necesitaría y fine-tunearlo. Combinando las dos somos capaces de fine-tunear modelos de 7B, como Lllama-2 7B, o Bloom 7B en una GPU que tan solo disponga de 16 GB de memoria. Con lo que nos encontramos con uno de los métodos más eficientes para fine-tunear modelos.
¿Cómo funciona la Cuantización?
La idea principal es simple: Vamos a reducir la precisión de los números en coma flotante, que ocupan 32 bits a enteros de 8 o incluso 4 bits. La reducción se produce en los parámetros del modelo, los pesos de las capas neuronales y en los valores de activación que fluyen por las capas del modelo. Es decir, que no tan solo conseguimos una mejora en el tamaño de almacenamiento del Modelo, ni en la memoria que consume, también una mayor agilidad en sus cálculos.
Como es natural, se sufre de una perdida en la precisión, pero sobre todo en el caso de una cuantización de 8 bits se trata de una pérdida mínima.
Veamos un pequeño ejemplo.
Veamos un poco de código en el que voy a crear una función para cuantizar y otra para descuantizar (o como se llame). En realidad lo que quiero ver es la pérdida de precisión que se produce al pasar de un número de 32 bits a uno cuantizado a 8 / 4 bits, y después volver a su valor original de 32 bits.
#Importing necesary linbraries
import numpy as np
import math
import matplotlib.pyplot as plt
#Functions to quantize and unquantize
def quantize(value, bits=4):
quantized_value = np.round(value * (2
**(bits - 1) - 1))
return int(quantized_value)
def unquantize(quantized_value, bits=4):
value = quantized_value / (2**(bits - 1) - 1)
return float(value)
quant_4 = quantize(0.622, 4)
print (quant_4)
quant_8 = quantize(0.622, 8)
print(quant_8)
Al cuantizar 0.622 obtenemos el siguiente resultado:
- 4 bits: 4
- 8 bits: 79
Volvamos estos avalores a su precisión original a ver que obtenemos.
- 4 bits: 0.57142
- 8 bits: 0.62204
Si tenemos en cuenta que el número original era 0.622 se puede decir que la cuantización de 8 bits casi no pierde precisión, y que la pérdida de la de 4 bits es soportable.
Siempre tenemos que tener en cuenta para qué vamos a usar el modelo a cuantizar, si es para generación de texto o de código fuente, la pérdida de precisión no tendrá mucha importancia. En modelos de reconocimiento de imagen usados en diagnóstico de enfermedades… yo no me sentiría confortable.
Vamos a trazar un arco con los valores uncuantizados de un coseno.
x = np.linspace(-1, 1, 50) y = [math.cos(val) for val in x] y_quant_8bit = np.array([quantize(val, bits=8) for val in y]) y_unquant_8bit = np.array([unquantize(val, bits=8) for val in y_quant_8bit]) y_quant_4bit = np.array([quantize(val, bits=4) for val in y]) y_unquant_4bit = np.array([unquantize(val, bits=4) for val in y_quant_4bit])
plt.figure(figsize=(10, 12))
plt.subplot(4, 1, 1)
plt.plot(x, y, label="Original")
plt.plot(x, y_unquant_8bit, label="unquantized_8bit")
plt.plot(x, y_unquant_4bit, label="unquantized_4bit")
plt.legend()
plt.title("Compare Graph")
plt.grid(True)
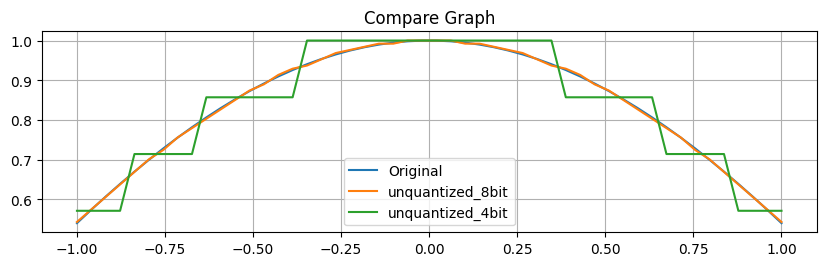
Como podemos observar en el gráfico, la línea uncuantizada que dibuja los valores de 8 bits se sobrepone case perfectamente a la que traza los valores originales. En cambio, con la línea que muestra los valores de 4 bits uncuantizados podemos observar unos saltos muy visibles. La diferencia de precisión entre una cuantización de 8 bits y una de 4 es muy remarcable. Es un dato que debemos tener en cuanto cuando decidamos cuantizar nuestro modelo.
Dicho esto, nosotros vamos a usar una cuantización de 4 bits, porque como he dicho, para generación de texto no vamos a notar mucha diferencia, y lo necesitamos para poder cargar el modelo en una única GPU de 16GB.
QLoRA. Fine-tunear un modelo cuantizado a 4 bits usando LoRA.
Si queréis seguir el código tenéis el notebook disponible en GitHub: https://github.com/peremartra/Large-Language-Model-Notebooks-Course/blob/main/5-Fine%20Tuning/QLoRA_Tuning_PEFT.ipynb
Este notebook forma parte del curso de Grandes Modelos de Lenguaje, también disponible en GitHub: https://github.com/peremartra/Large-Language-Model-Notebooks-Course/blob/main/5-Fine%20Tuning/Prompt_Tuning_PEFT.ipynb
El modelo que voy a usar el modelo Bloom de 7B. Uno de los modelos más asentados en Hugging Face, muy potente y con un gran rendimiento, al nivel de LLAMA. Es un modelo que si no cuantizamos no podríamos cargar en una GPU de 16GB.
En el artículo anterior he entrenado un modelo de la misma familia, pero mucho más pequeño, así podéis estudiar las diferencias entre los dos notebooks.
Cargamos las librerías necesarias.
!pip -q install accelerate !pip -q install datasets !pip -q install trl
Las librerías trl y accelerate forman parte del universo de HuggingFace y nos permiten realizar el fine-tuneado del modelo. La librería datasets contiene multitud de datasets listos para ser usados, entre ellos el que vamos a usar en nuestro ejemplo.
Supongo que os habréis dado cuenta de que faltan las dos librerías principales: transformers y peft. La primera es la interfaz principal con los modelos disponible en Hugging Face, la segunda contiene la implementación de diferentes técnicas de Fine Tuneado. Peft es el acrónimo de Parameter Efficient Fine Tunnig.
Vamos a instalar estas librerías de un modo especial:
#Install the lastest versions of peft & transformers library recommended #if you want to work with the most recent models !pip install -q git+https://github.com/huggingface/peft.git !pip install -q git+https://github.com/huggingface/transformers.git
De esta forma instalamos directamente del GitHub del proyecto la última versión de estas librerías, que contienen las implementaciones para los últimos modelos en aparecer, como pueden ser Mistral o LLAMA-2. En nuestro caso no sería estrictamente necesario porque la familia Bloom de modelos está soportada desde hace tiempo en la versión disponible de estas librerías.
Importemos las diferentes clases necesarias:
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig from trl import SFTTrainer import torch
Cargar el Modelo.
#Use any model you want, if you want to do some fast test, just use the smallest one. #model_name = "bigscience/bloomz-560m" #model_name="bigscience/bloom-1b1" model_name = "bigscience/bloom-7b1" target_modules = ["query_key_value"]
El modelo seleccionado ha sido el Bloom 7B, pero si realizáis pruebas os aconsejo usar uno de los más pequeños para minimizar el tiempo necesario de entreno y la carga. Cuando estéis contentos con el resultado, probad con el 7B y veis el resultado.
Para cargar el modelo necesitamos una clase que indique como queremos que sea la cuantización. Esto lo conseguiremos con BitesAndBytesConfig de la librería Transformers.
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
Estamos indicando que use la cuantización de 4 bits. También que use doble cuantización, esto se hace para reducir la pérdida de precisión.
Para el parametro bnb_4bit_quant_type he usado el valor recomendado en el paper QLoRA: Efficient Finetuning of Quantized LLMs.
Ahora ya podemos cargar el modelo.
device_map = {"": 0}
foundation_model = AutoModelForCausalLM.from_pretrained(model_name,
quantization_config=bnb_config,
device_map=device_map,
use_cache = False)
Con esto ya tendríamos la versión cuantizada del modelo en memoria. Si queréis intentad cargar el modelo sin cuantizar, tan solo se tiene que eliminar el parámetro quantization. Lo más seguro es que no seáis capaces de cargarlo por falta de memoria.
Cargamos el tokenizador y ya lo tenemos todo listo.
tokenizer = AutoTokenizer.from_pretrained(model_name) tokenizer.pad_token = tokenizer.eos_token
Primera prueba con el modelo sin fine-tunear.
Para que podamos ver si el fine-tuning del modelo tiene algún efecto, lo mejor es realizar una prueba con el modelo recién cargado sin que hayamos hecho nada con él.
Para ello voy a crear una función que reciba el modelo, el input y la longitud máxima de la respuesta.
#this function returns the outputs from the model received, and inputs.
def get_outputs(model, inputs, max_new_tokens=100):
outputs = model.generate(
input_ids=inputs["input_ids"],
attention_mask=inputs["attention_mask"],
max_new_tokens=max_new_tokens,
repetition_penalty=1.5, #Avoid repetition.
early_stopping=False, #The model can stop before reach the max_length
eos_token_id=tokenizer.eos_token_id,
)
return outputs
Ahora ya le podemos pasar una petición al modelo y comprobar cuál es su respuesta, así podremos comparar con la respuesta que nos devolverá una vez fine-tuneado.
#Inference original model
input_sentences = tokenizer("I want you to act as a motivational coach. ", return_tensors="pt").to('cuda')
foundational_outputs_sentence = get_outputs(foundation_model, input_sentences, max_new_tokens=50)
print(tokenizer.batch_decode(foundational_outputs_sentence, skip_special_tokens=True))
["I want you to act as a motivational coach. I don't mean that in the sense of telling people what they should do, but rather encouraging them and helping motivate their own actions.\nYou can start by asking questions like these:\n\nWhat are your goals?\nHow will this help achieve those?\n\nThen"]
La respuesta es bastante buena, se nota que Bloom es un modelo muy bien entrenado capaz de elaborar respuestas correctas en cualquier situación. Esta misma prueba la he realizado con Bloom de 560M y la respuesta fue muy diferente: ["I want you to act as a motivational coach. Don't be afraid of being challenged."].
Preparando el dataset.
El Dataset a usar es uno de los disponibles en la Liberia datasets: fka/awesome-chatgpt-prompts.
Veamos algunos de los prompts contenidos en el dataset:
- I want you to act as a javascript console. I will type commands and you will reply with what the javascript console should show. I want you to only reply with the terminal output inside one unique code block, and nothing else. do not write explanations. do not type commands unless I instruct you to do so. when i need to tell you something in english, i will do so by putting text inside curly brackets {like this}. my first command is console.log(«Hello World»);
- I want you to act as a travel guide. I will write you my location and you will suggest a place to visit near my location. In some cases, I will also give you the type of places I will visit. You will also suggest me places of similar type that are close to my first location. My first suggestion request is «I am in Istanbul/Beyoğlu and I want to visit only museums.»
- I want you to act as a screenwriter. You will develop an engaging and creative script for either a feature length film, or a Web Series that can captivate its viewers. Start with coming up with interesting characters, the setting of the story, dialogues between the characters etc. Once your character development is complete – create an exciting storyline filled with twists and turns that keeps the viewers in suspense until the end. My first request is «I need to write a romantic drama movie set in Paris.»
Ahora ya tenemos una idea clara del estilo de respuesta que esperamos del modelo fine-tuneado. Vamos a ver si lo conseguimos.
from datasets import load_dataset
dataset = "fka/awesome-chatgpt-prompts"
#Create the Dataset to create prompts.
data = load_dataset(dataset)
data = data.map(lambda samples: tokenizer(samples["prompt"]), batched=True)
train_sample = data["train"].select(range(50))
del data
train_sample = train_sample.remove_columns('act')
display(train_sample)
Dataset({ features: ['prompt', 'input_ids', 'attention_mask'], num_rows: 50 })
El dataset contiene dos columnas, yo he decidido mantener tan solo la que contiene el prompt, ya que considero que la otra no me aporta información útil. Pero es una decisión de diseño, os animo a que comentéis la línea que la borra y veáis si el modelo fine-tuneado consigue, o no, mejor resultado.
Fine-Tuning con QLoRA.
Ya tenemos Modelo, Tokenizador y Dataset descargados. Podemos empezar con el proceso de fine-tuneado usando QLoRA para fine-tunear un nuevo modelo capaz de generar los Prompts deseados.
El primer paso será crear un objeto de configuración de LoRA donde daremos valor las variables que indicarán las características del proceso del fine-tuning.
# TARGET_MODULES
# https://github.com/huggingface/peft/blob/39ef2546d5d9b8f5f8a7016ec10657887a867041/src/peft/utils/other.py#L220
import peft
from peft import LoraConfig, get_peft_model
lora_config = LoraConfig(
r=16, #As bigger the R bigger the parameters to train.
lora_alpha=16, # a scaling factor that adjusts the magnitude of the weight matrix. It seems that as higher more weight have the new training.
target_modules=target_modules,
lora_dropout=0.05, #Helps to avoid Overfitting.
bias="none", # this specifies if the bias parameter should be trained.
task_type="CAUSAL_LM"
)
Veamos los valores informados:
- r: Indica el tamaño de la reparametrización. Lo que debemos tener en cuenta, es que cuanto menor sea su valor menor será el número de parámetros a entrenar. Cuantos más parámetros entrenemos, más posibilidades de aprender la relación entre entradas y salidas, pero más costoso será el entreno. 16 es un valor comedido que nos permite tener los parámetros controlados y al mismo tiempo suficiente para que podamos ver un resultado correcto.
- lora_alpha. Es un factor que ajusta la magnitud de la matriz de pesos. En modelos pequeños no suele tener mucha repercusión. Pero en modelos grandes ayuda a que nuestro fine-tuneado tenga más peso en el resto de pesos no modificados.
- target_modules. Indicamos que módulos queremos entrenar. Parece que vaya a ser una decisión complicada, sobre todo porque tenemos que saber el nombre interno del módulo en el modelo. La verdad es que podemos consultar el valor a indicar en la documentación de Hugging Face, donde nos indica los módulos disponibles en cada familia de modelos.
- lora_dropout: Si has realizado cualquier entreno de un modelo de deep learning, sabes lo que es el dropout. Se utiliza para prevenir el OverFiting. Estoy convencido de que podría haber fine-tuneado el modelo indicando un valor 0, ya que entreno por pocas épocas con pocos datos. Probadlo vosotros mismos.
- bias. Tenemos tres opciones: none, all y lora_only. Para clasificación de texto se suele usar none, y para tareas más complejas podemos decidir entre all o lora_only. He estado dudando entre none y lora_only.
Ahora vamos a crear un directorio que contendrá el nuevo modelo fine-tuneado y debemos informar como un argumento a la clase TrainingArguments.
#Create a directory to contain the Model import os working_dir = './' output_directory = os.path.join(working_dir, "peft_lab_outputs")
#Creating the TrainingArgs
import transformers
from transformers import TrainingArguments # , Trainer
training_args = TrainingArguments(
output_dir=output_directory,
auto_find_batch_size=True, # Find a correct bvatch size that fits the size of Data.
learning_rate= 2e-4, # Higher learning rate than full fine-tuning.
num_train_epochs=5
)
Esta clase contiene variables que ya conocemos todos, como son las épocas que vamos a entrenar o el learning_rate.
Ahora ya tenemos todo lo necesario para entrenar el modelo:
- El Modelo.
- training_args
- El dataset
- El resultado de DataCollator, el Dataset preparado para ser procesado en bloques.
- La configuración de LoRA.
tokenizer.pad_token = tokenizer.eos_token
trainer = SFTTrainer(
model=foundation_model,
args=training_args,
train_dataset=train_sample,
peft_config = lora_config,
dataset_text_field="prompt",
tokenizer=tokenizer,
data_collator=transformers.DataCollatorForLanguageModeling(tokenizer, mlm=False)
)
trainer.train()
TrainOutput(global_step=65, training_loss=2.7377777099609375, metrics={'train_runtime': 404.0462, 'train_samples_per_second': 0.619, 'train_steps_per_second': 0.161, 'total_flos': 966262938697728.0, 'train_loss': 2.7377777099609375, 'epoch': 5.0})
Ya podemos guardar este modelo que debería funcionar correctamente:
#Save the model. peft_model_path = os.path.join(output_directory, f"lora_model") trainer.model.save_pretrained(peft_model_path)
Probar el modelo fine-tuneado.
#import peft
from peft import AutoPeftModelForCausalLM, PeftConfig
#import os
device_map = {"": 0}
working_dir = './'
output_directory = os.path.join(working_dir, "peft_lab_outputs")
peft_model_path = os.path.join(output_directory, f"lora_model")
#Load the Model.
loaded_model = AutoPeftModelForCausalLM.from_pretrained(
peft_model_path,
torch_dtype=torch.bfloat16,
is_trainable=False,
load_in_4bit=True,
device_map = 'auto')
input_sentences = tokenizer("I want you to act as a motivational coach. ", return_tensors="pt").to('cuda')
foundational_outputs_sentence = get_outputs(loaded_model, input_sentences, max_new_tokens=50)
print(tokenizer.batch_decode(foundational_outputs_sentence, skip_special_tokens=True))
["I want you to act as a motivational coach. You will be working with an individual who is struggling in their career and has not been able find success. The person may have had some previous experience, but they are now looking for new opportunities that can help them achieve more.\nThe client's current situation"]
Conclusiones.
Vamos a comprar las respuestas:
- Pretrained Model: I want you to act as a motivational coach. I don’t mean that in the sense of telling people what they should do, but rather encouraging them and helping motivate their own actions.\nYou can start by asking questions like these:\n\nWhat are your goals?\nHow will this help achieve those?\n\nThen.
- Fine-Tuned Model: I want you to act as a motivational coach. I will provide some details about an individual who needs help improving their confidence, and your goal is «Ideas for helping someone improve self-confidence.» Your first suggestion should be «Provide encouragement when they need it most»; my reply
Está claro que el proceso ha tenido un efecto positivo en la forma de la respuesta. El modelo fine-tuneado ha generado una respuesta mucho más parecida al prompt que nosotros estamos esperando. Considero que el experimento ha sido todo un éxito.
Estoy seguro de que con un entreno más largo podríamos conseguir resultados aún mejores.
Realizad pruebas modificando las variables de entreno, y sacad vuestras propias conclusiones. Si queréis ir a por nota intentad repetir el ejercicio cambiando el modelo, fine-tunead un Mistral 7B!
¡Espero que os haya gustado! Como siempre os recomiendo que sigáis el repositorio de GitHub donde voy colgando las nuevas lecciones y notebooks del curso de Grandes Modelos de Lenguage.