Una GAN, como ya sabemos, nos permite generar imágenes similares a las del Dataset con el que ha sido entrenada. Una GAN condicional nos permite indicar que tipo de imágenes de las que tenemos en el dataset original son las que queremos generar.
Para ello debemos modificar la estructura de los modelos que conforman la GAN para que acepten como entrada la etiqueta que marca el tipo de imagen a generar.
En el artículo voy a usar el dataset MNIST, en él encontramos 10 categorías, que corresponden a los números del 0 al 9, y es un Dataset que ya he usado anteriormente. Por lo que se puede comparar fácilmente los cambios introducidos en la GAN para transformarla en una GAN condicional.
La serie sobre GANs ya consta, con este, de cuatro artículos, en el primero de ellos podemos encontrar una GAN que funciona con el Dataset MNIST, no es mala idea comparar la estructura de las GANs de los dos artículos.
El código del notebook completo de este artículo puede encontrarse en
GitHub: https://github.com/oopere/GANs/blob/main/C4_COND_GAN_MNIST.ipynb
Estructura general de una GAN condicional.
La estructura es mayoritariamente la misma que para una GAN normal. Es decir, tenemos un Generador, responsable de crear las imágenes, y un Discriminador, que debe decidir si las imágenes son reales, pertenecientes al Dataset, o provienen del Generador.
La principal diferencia es que el Generador y el Discriminador ahora deben recibir la clase a la que pertenecen las imágenes, ya que se debe tener en cuenta tanto para generarlas, como para que el Discriminador pueda identificar a que clase pertenecen.
Como se puede ver tanto Generador como Discriminador van a ser modelos Multi path, con lo que ya no vamos a poder usar el Sequential API y usaremos el Functional API.
El Generador de nuestra GAN condicional.
Cualquier Generador de una GAN recibe ruido, datos aleatorios en forma gaussiana, como dato de entrada, para transformarlos en una imagen del tamaño deseado.
El tamaño del ruido, o también conocido como espacio latente, que he escogido para este Generador, es de 50. Este ruido debe convertirse en una imagen de 28x28x1. Para ello empezaremos transformándolo en una imagen más pequeña de 7x7x1 que alcanzara su tamaño objetivo mediante upsamplings.
En el caso de una GAN condicional, el ruido, será acompañado por un indicador de la clase a la que debe pertenecer la imagen generada, es decir, la información condicional.
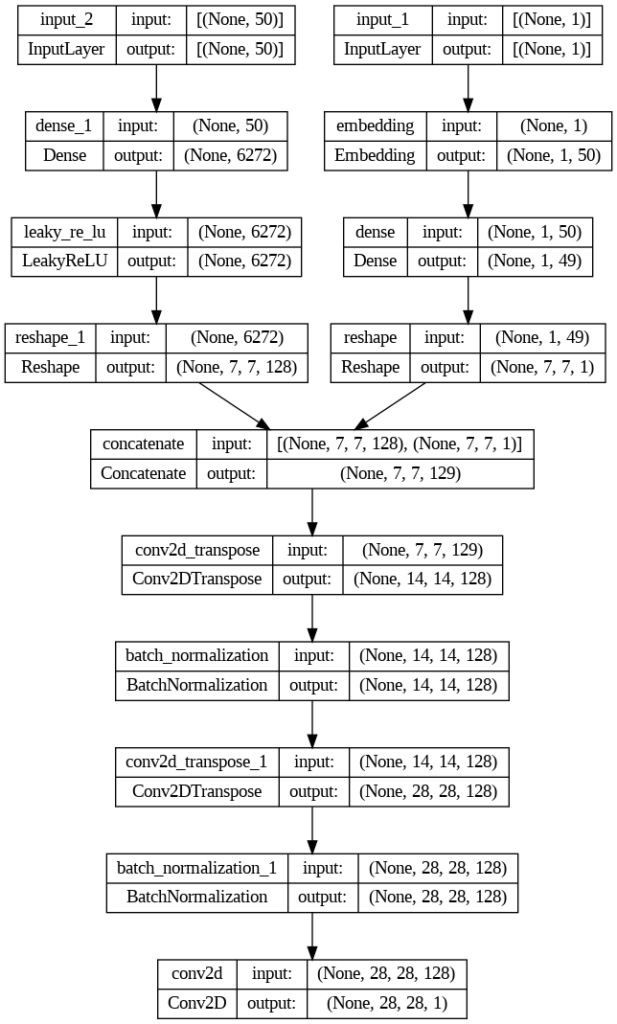
En la rama de la derecha podemos ver cómo el indicador condicional pasa a tener un shape de 7x7x1 para adaptarse al tamaño de la imagen origen. En la rama de la izquierda el ruido se transforma a 7x7x128. Lo que representa nuestra imagen origen de 7×7 con 128 nodos. Estas dos capas se unen con una, Concatenate. Con lo que se transforma en un canal más y pasamos a tener una imagen de 7x7x129 donde uno de los canales tiene la información de la clase a la que pertenece.
Veamos la definición del bloque que recibe el dato indicador de clase:
# label input in_label = keras.layers.Input(shape=(1,)) # embedding for categorical input li = keras.layers.Embedding(n_classes, 50)(in_label) # linear multiplication n_nodes = 7 * 7 li = keras.layers.Dense(n_nodes)(li) # reshape to additional channel li = keras.layers.Reshape((7, 7, 1))(li)
Primero se define una capa de entrada, para recibir el indicador, con una sola variable Input(shape=(1,)).
Este valor se pasa por la capa de Embedding donde se transforma en un vector de números reales. El vector tiene un tamaño de 50. n_clases indica el número de clases existentes en el dataset.
La siguiente capa Dense, multiplica linealmente el vector obtenido de la capa Embedding.
Finalmente, le aplicamos un Reshape a los datos devueltos por la capa Dense. Así tenemos el formato de 7x7x1 deseado.
Veamos ahora la rama que transforma el ruido hasta una imagen de 7×7.
# image generator input in_lat = keras.layers.Input(shape=(latent_dim,)) # foundation for 7x7 image n_nodes = 128 * 7 * 7 gen = keras.layers.Dense(n_nodes)(in_lat) gen = keras.layers.LeakyReLU(alpha=0.2)(gen) gen = keras.layers.Reshape((7, 7, 128))(gen)
En la primera línea definimos la capa Input para el ruido.
Después se define una capa Dense, que procesa el ruido, para generar una salida con los nodos indicados. Queremos que sea 7 * 7 con una profundidad de 128. Es decir, serán 6272 nodos.
Pasamos por una capa de activación LeakyReLU para permitir unos valores negativos, aunque como máximo con un valor de -0.2. Usar una activación LeakyReLU en lugar de ReLU es una de las recomendaciones de las GAN Hacks.
Finalizamos con un Reshape que nos deja los datos en la forma que deseamos.
Veamos ahora la fusión y la parte común del modelo:
#merge image gen and label input
merge = keras.layers.Concatenate()([gen, li])
# upsample to 14x14
gen = keras.layers.Conv2DTranspose(128, (4,4), strides=(2,2), padding='same',
activation=keras.layers.LeakyReLU(alpha=0.2))(merge)
gen = keras.layers.BatchNormalization()(gen)
# upsample to 28x28
gen = keras.layers.Conv2DTranspose(128, (4,4), strides=(2,2), padding='same',
activation=keras.layers.LeakyReLU(alpha=0.2))(gen)
gen = keras.layers.BatchNormalization()(gen)
# output
out_layer = keras.layers.Conv2D(1, (7,7), activation='tanh', padding='same')(gen)
# define model
model = keras.Model([in_lat, in_label], out_layer)
Empezamos con una capa Concatenate que combina las dos ramas, y nos devuelve los datos fusionados en 7x7x129, donde uno de los nodos contiene la información condicional.
A posteriori empezamos con el proceso de upsampling normal en cualquier GAN. En este caso se usan dos capas Conv2DTranspose para pasar primero de 7×7 a 14×14 y finalmente a 28×28. A destacar el uso del activador LeakyReLU y de la capa de BatchNormalization después de cada upsampling.
Podéis encontrar más información del proceso de upsampling en el primer artículo del tutorial de GANS.: https://martra.uadla.com/como-crear-una-gan-para-generar-pequenas-imagenes/
Finalmente, se define el modelo usando las dos capas de entrada y la capa de salida. La capa de salida contiene todas las capas que hemos guardado en gen, que realmente abarca todas las capas del modelo, ya que ha incorporado merge, que es la fusión de las dos ramas definidas previamente.
Veamos todo el código de creación del Generador junto:
# define the standalone generator model
def define_generator(latent_dim, n_classes=10):
# label input
in_label = keras.layers.Input(shape=(1,))
# embedding for categorical input
li = keras.layers.Embedding(n_classes, 50)(in_label)
# linear multiplication
n_nodes = 7 * 7
li = keras.layers.Dense(n_nodes)(li)
# reshape to additional channel
li = keras.layers.Reshape((7, 7, 1))(li)
# image generator input
in_lat = keras.layers.Input(shape=(latent_dim,))
# foundation for 7x7 image
n_nodes = 128 * 7 * 7
gen = keras.layers.Dense(n_nodes)(in_lat)
gen = keras.layers.LeakyReLU(alpha=0.2)(gen)
gen = keras.layers.Reshape((7, 7, 128))(gen)
# merge image gen and label input
merge = keras.layers.Concatenate()([gen, li])
# upsample to 14x14
gen = keras.layers.Conv2DTranspose(128, (4,4), strides=(2,2), padding='same',
activation=keras.layers.LeakyReLU(alpha=0.2))(merge)
gen = keras.layers.BatchNormalization()(gen)
# upsample to 28x28
gen = keras.layers.Conv2DTranspose(128, (4,4), strides=(2,2), padding='same',
activation=keras.layers.LeakyReLU(alpha=0.2))(gen)
gen = keras.layers.BatchNormalization()(gen)
# output
out_layer = keras.layers.Conv2D(1, (7,7), activation='tanh', padding='same')(gen)
# define model
model = keras.Model([in_lat, in_label], out_layer)
return model
noise_size = 50
generator = define_generator(noise_size)
generator.summary()
Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_2 (InputLayer) [(None, 50)] 0 []
input_1 (InputLayer) [(None, 1)] 0 []
dense_1 (Dense) (None, 6272) 319872 ['input_2[0][0]']
embedding (Embedding) (None, 1, 50) 500 ['input_1[0][0]']
leaky_re_lu (LeakyReLU) (None, 6272) 0 ['dense_1[0][0]']
dense (Dense) (None, 1, 49) 2499 ['embedding[0][0]']
reshape_1 (Reshape) (None, 7, 7, 128) 0 ['leaky_re_lu[0][0]']
reshape (Reshape) (None, 7, 7, 1) 0 ['dense[0][0]']
concatenate (Concatenate) (None, 7, 7, 129) 0 ['reshape_1[0][0]',
'reshape[0][0]']
conv2d_transpose (Conv2DTransp (None, 14, 14, 128) 264320 ['concatenate[0][0]']
ose)
batch_normalization (BatchNorm (None, 14, 14, 128) 512 ['conv2d_transpose[0][0]']
alization)
conv2d_transpose_1 (Conv2DTran (None, 28, 28, 128) 262272 ['batch_normalization[0][0]']
spose)
batch_normalization_1 (BatchNo (None, 28, 28, 128) 512 ['conv2d_transpose_1[0][0]']
rmalization)
conv2d (Conv2D) (None, 28, 28, 1) 6273 ['batch_normalization_1[0][0]']
==================================================================================================
Total params: 856,760
Trainable params: 856,248
Non-trainable params: 512
Ahora que ya hemos visto cómo se ha creado el generador de nuestra GAN, toca ver el discriminador.
El discriminador de nuestra GAN condicional.
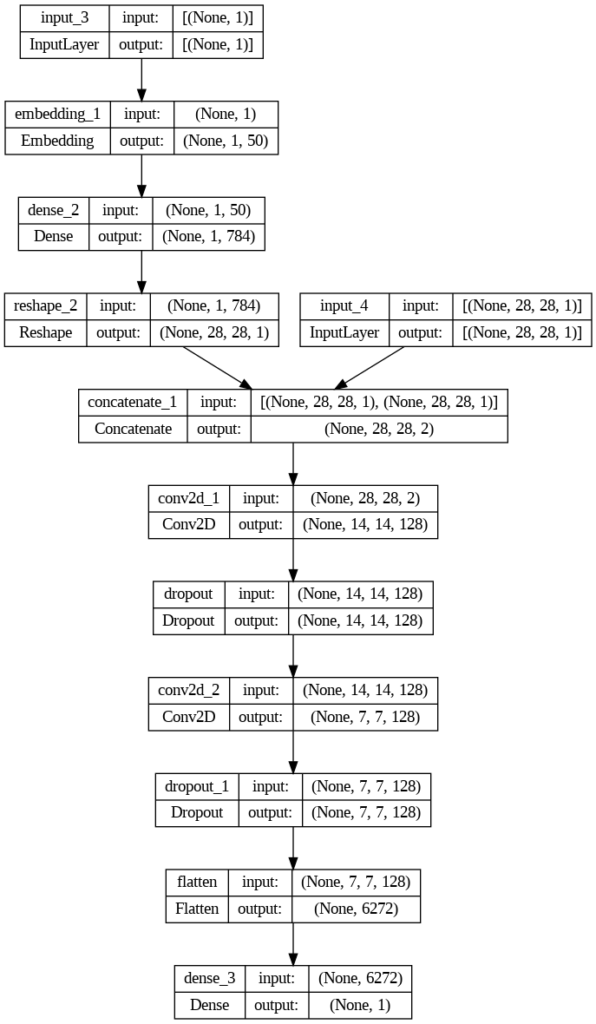
El discriminado será el responsable de decidir si una imagen es del Dataset original, o si ha sido creada por el Generador. Aparte de la imagen en este caso, al tratarse de una GAN condiciona, también se recibe la información condicional que le indica a que clase pertenece.
Veamos el código de creación de las dos ramas y su merge:
in_label = keras.layers.Input(shape=(1,)) li = keras.layers.Embedding(n_classes, noise_size)(in_label) n_nodes = in_shape[0] * in_shape[1] li=keras.layers.Dense(n_nodes)(li) li=keras.layers.Reshape((in_shape[0], in_shape[1], 1))(li) in_image = keras.layers.Input(shape=in_shape) merge = keras.layers.Concatenate()([in_image, li])
Las dos primeras líneas definen el Input y lo pasan por un Embedding, igual que con el generador.
Después procesamos la salida en una capa Dense que nos devuelve el vector del ancho y alto de la imagen, con la información procesada.
Con la capa Reshape dejamos el vector con el mismo tamaño y forma que la imagen de entrada.
Finalmente, combinamos las dos ramas con la capa Concatenate, que nos devuelve la información de la imagen más un canal para la información condicional.
Para finalizar el discriminador faltaría el proceso de downsample. Como en cualquier otra GAN, para llegar de la imagen de 28×28 a una conclusión binaria que indique si es o no una imagen creada por el Generador.
def define_discriminator(in_shape=(28, 28, 1), n_classes=10):
in_label = keras.layers.Input(shape=(1,))
li = keras.layers.Embedding(n_classes, 50)(in_label)
n_nodes = in_shape[0] * in_shape[1]
li=keras.layers.Dense(n_nodes)(li)
li=keras.layers.Reshape((in_shape[0], in_shape[1], 1))(li)
in_image = keras.layers.Input(shape=in_shape)
merge = keras.layers.Concatenate()([in_image, li])
#downsample
fe=keras.layers.Conv2D(128, (3, 3), strides=(2, 2), padding='same',
activation=keras.layers.LeakyReLU(alpha=0.2))(merge)
fe=keras.layers.Dropout(0.4)(fe)
#downsample
fe=keras.layers.Conv2D(128, (3, 3), strides=(2, 2), padding='same',
activation=keras.layers.LeakyReLU(alpha=0.2))(fe)
fe=keras.layers.Dropout(0.4)(fe)
fe = keras.layers.Flatten()(fe)
out_layer = keras.layers.Dense(1, activation='sigmoid')(fe)
model = keras.Model([in_image, in_label], out_layer)
opt = keras.optimizers.Adam(learning_rate=0.0002, beta_1=0.5)
model.compile(loss='binary_crossentropy', optimizer=opt, metrics=['accuracy'])
return model
discriminator = define_discriminator()
discriminator.summary()
Model: "model_1"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_3 (InputLayer) [(None, 1)] 0 []
embedding_1 (Embedding) (None, 1, 50) 500 ['input_3[0][0]']
dense_2 (Dense) (None, 1, 784) 39984 ['embedding_1[0][0]']
input_4 (InputLayer) [(None, 28, 28, 1)] 0 []
reshape_2 (Reshape) (None, 28, 28, 1) 0 ['dense_2[0][0]']
concatenate_1 (Concatenate) (None, 28, 28, 2) 0 ['input_4[0][0]',
'reshape_2[0][0]']
conv2d_1 (Conv2D) (None, 14, 14, 128) 2432 ['concatenate_1[0][0]']
dropout (Dropout) (None, 14, 14, 128) 0 ['conv2d_1[0][0]']
conv2d_2 (Conv2D) (None, 7, 7, 128) 147584 ['dropout[0][0]']
dropout_1 (Dropout) (None, 7, 7, 128) 0 ['conv2d_2[0][0]']
flatten (Flatten) (None, 6272) 0 ['dropout_1[0][0]']
dense_3 (Dense) (None, 1) 6273 ['flatten[0][0]']
==================================================================================================
Total params: 196,773
Trainable params: 196,773
Non-trainable params: 0
__________________________________________________________________________________________________
Con esto ya tendríamos los dos modelos que conforman nuestra GAN condicional, ahora deberíamos juntarlos.
La estructura de la GAN.
Para juntar los modelos usaré una función que recibe el generador y el discriminador y nos devuelve el modelo completo ya montado y compilado.
#define the Conditional GAN def define_gan(generator, discriminator): #make discriminator non trainable discriminator.trainable = False #get noise and label from generator gen_noise, gen_label = generator.input #get output from generator gen_output = generator.output #connect image and label input from generator as inputs to discriminator gan_output = discriminator([gen_output, gen_label]) #define the GAN model. model= keras.Model([gen_noise, gen_label], gan_output) #compile model opt = keras.optimizers.Adam(learning_rate=0.0002, beta_1=0.5) model.compile(loss='binary_crossentropy', optimizer=opt) return model
Lo más importante de este código es que usamos la imagen y la información condicional creadas por el generador como entradas del discriminador.
Por lo demás es bastante autoexplicativo. Se marcan las capas del discriminador como no entrenables. Recuperamos la entrada de ruido y de la etiqueta del Generador, así como su output. Creamos gan_output, llamando al discriminador con la salida del generador, y la etiqueta condicional.
El modelo lo creamos usando la clase Model de Keras. Como primer parámetro recibe los inputs, y como segundo la salida.
Finalizamos compilando el modelo.
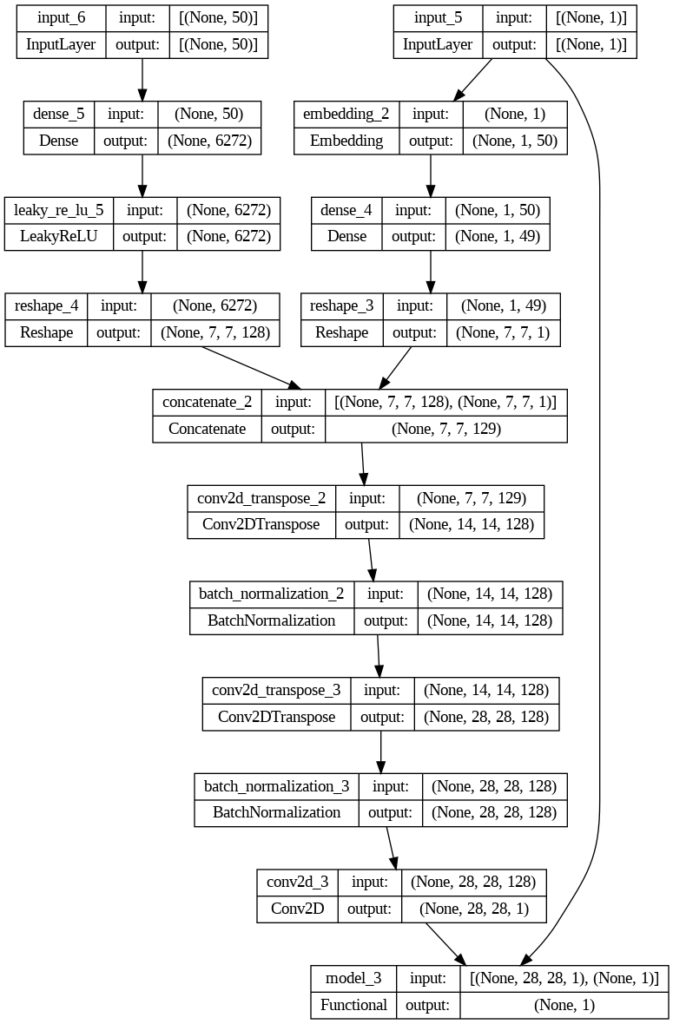
Aunque la estructura parece muy compleja, es básicamente una suma de los dos modelos.
Entreno de la GAN.
Con los modelos ya creados ahora toca entrenar la GAN. El proceso es simple. Se debe decidir cuantas épocas queremos entrenar, cada época debe usar todos los datos del dataset.
El dataset suele dividirse en batches, para realizar el entreno con varias imágenes a la vez. Dentro de cada época tendremos tantos pasos como dataset / batches. Así, al acabar los pasos habremos usado todos los datos disponibles.
Un paso debe contener las siguientes acciones:
- Entrenar el Discriminador. Se hace en dos bloques.
- Cogemos imágenes reales y se las pasamos con la etiqueta de imágenes reales.
- Generamos imágenes falsas con el generador y las pasamos al discriminador, con la etiqueta de imágenes falsas
- Entrenamos el Generador.
- Le pasamos a la GAN ruido marcado con etiquetas de imágenes verdaderas. Dentro de la GAN este ruido y etiquetas se usan pasa generar imágenes que son pasadas al discriminador, y el generador va modificando sus pesos para poder reducir la pérdida. Dentro de la GAN el discriminador tiene marcados sus capas como no entrenable, por lo que solo se pueden modificar los pesos del generador.
Para realizar estas acciones voy a crear varias funciones auxiliares, para que la función principal de entreno sea fácil de leer y mantener.
Funciones de soporte.
def load_dataset(): # download the training images (X_train, y_train), (_, _) = keras.datasets.mnist.load_data() # normalize pixel values X_train = X_train.astype(np.float32) / 255 # reshape and rescale X_train = X_train.reshape(-1, 28, 28, 1) * 2. - 1. return [X_train, y_train]
Esta función carga el Dataset desde Keras, y normaliza el valor de los píxeles de las imágenes, para que estén en valores comprendidos entre -1 y 1.
La función nos devuelve tanto las imágenes como la clase a la que pertenecen.
def get_dataset_samples(dataset, n_samples): images, labels = dataset ix = np.random.randint(0, images.shape[0], n_samples) X, labels = images[ix], labels[ix] y = np.ones((n_samples, 1)) return [X, labels], y
La función recibe un Dataset, del que nos devuelve el número de elementos indicado en n_samples. El primer elemento se decide mediante un número al azar, lo que da una cierta aleatoriedad a los datos.
Aparte de devolver las imágenes y la categoría a la que pertenecen, también nos devuelve una etiqueta indicando que las imágenes son verdaderas.
def generate_noise(noise_size, n_samples, n_classes=10): #generate noise x_input = np.random.randn(noise_size * n_samples) #shape to adjust to batch size z_input = x_input.reshape(n_samples, noise_size) #generate labels labels = np.random.randint(0, n_classes, n_samples) return [z_input, labels]
Esta función es la responsable de crear el ruido que recibe el Generador como entrada. Nos devuelve tanto el ruido como unos indicadores de clase generados de forma aleatoria, que indican a qué clase deberá pertenecer la imagen generada por el ruido que acompaña a la etiqueta.
def generate_fake_samples(generator, latent_dim, n_samples): #get the noise calling the function z_input, labels_input = generate_noise(latent_dim, n_samples) images = generator.predict([z_input, labels_input]) #create class labes y = np.zeros((n_samples, 1)) return [images, labels_input], y
La función de arriba crea números usando el Generador. Para ello primero llama la función generate_noise, para conseguir la entrada para el Generador, y después lo llama para obtener las imágenes.
Nos devuelve unas imágenes acompañadas de su indicador de clase y una lista de etiquetas indicando que son imágenes generadas.
La función de entreno.
Vamos a usar las funciones auxiliares para construir la función de entreno. Esta tiene dos partes principales: primero se entrena el Discriminador y después el Generador.
El discriminador se entrena en dos lotes. En el primero le pasamos imágenes reales del Dataset, recuperadas con la función get_dataset_samples. En el segundo bloque le pasamos imágenes falsas creadas con el Generador.
La razón de utilizar dos lotes de entreno en lugar de uno es que se ha demostrado que es más eficiente. Es una de las recomendaciones de las GAN Hacks.
#TRAIN THE DISCRIMINATOR
# get randomly selected 'real' samples
[X_real, labels_real], y_real = get_dataset_samples(dataset, half_batch)
# update discriminator model weights
d_loss1, _ = discriminator.train_on_batch([X_real, labels_real], y_real)
# generate 'fake' examples
[X_fake, labels], y_fake = generate_fake_samples(generator, noise_size, half_batch)
# update discriminator model weights
d_loss2, _ = discriminator.train_on_batch([X_fake, labels], y_fake)
El bloque que entrena al Generador utiliza la función generate_noise, para obtener los datos de entrada necesarios, los acompaña de una etiqueta indicando que son datos verdaderos, en lugar de generados, y se los pasa a la función train_on_batch del modelo completo de GAN.
#TRAIN THE GENERATOR
# prepare points in latent space as input for the generator
[z_input, labels_input] = generate_noise(noise_size, n_batch)
# create inverted labels for the fake samples
y_gan = np.ones((n_batch, 1))
# update the generator via the discriminator's error
g_loss = GAN.train_on_batch([z_input, labels_input], y_gan)
Todo el código junto crea la siguiente función:
def train_gan(generator, discriminator, GAN, dataset, noise_size=100, n_epochs=30, n_batch=512):
steps = int(dataset[0].shape[0] / n_batch)
half_batch = int(n_batch / 2)
# manually enumerate epochs
for e in range(n_epochs):
# enumerate batches over the training set
for s in range(steps):
#TRAIN THE DISCRIMINATOR
# get randomly selected 'real' samples
[X_real, labels_real], y_real = get_dataset_samples(dataset, half_batch)
# update discriminator model weights
d_loss1, _ = discriminator.train_on_batch([X_real, labels_real], y_real)
# generate 'fake' examples
[X_fake, labels], y_fake = generate_fake_samples(generator, noise_size, half_batch)
# update discriminator model weights
d_loss2, _ = discriminator.train_on_batch([X_fake, labels], y_fake)
#TRAIN THE GENERATOR
# prepare points in latent space as input for the generator
[z_input, labels_input] = generate_noise(noise_size, n_batch)
# create inverted labels for the fake samples
y_gan = np.ones((n_batch, 1))
# update the generator via the discriminator's error
g_loss = GAN.train_on_batch([z_input, labels_input], y_gan)
# summarize loss on this batch
print('>%d, %d/%d, d1=%.3f, d2=%.3f g=%.3f' %
(e+1, s+1, steps, d_loss1, d_loss2, g_loss))
plot_results(X_fake, 8)
# save the generator model
generator.save('cgan_generator.h5')
Aparte de entrenar al Discriminador y el Generador también se muestran algunas de las imágenes generadas en cada época y se guarda el modelo al final del entreno. Tan solo se guarda el Generador, que es el que nos interesa utilizar en tiempo de inferencia.
Para realizar el entreno tan solo hay que hacer la siguiente llamada:
train_gan(generator, discriminator, GAN, dataset, noise_size, n_epochs=30, n_batch=128)
Usando el modelo para generar una clase específica de números.
Ahora que tenemos una GAN condicional entrenada podemos generar imágenes de la clase que queramos. En nuestro caso son números que pertenecen al Dataset MNIST, es decir, del 0 al 9.
Pero podría usarse para balancear Datasets que tuvieran una falta de imágenes de cualquiera de sus clases.
model = keras.models.load_model('cgan_generator.h5')
latent_points, labels = generate_noise(noise_size, 20)
labels = np.ones(20) * 5
X = model.predict([latent_points, labels])
plot_results(X, 10)
labels = np.ones(20) * 8
X = model.predict([latent_points, labels])
plot_results(X, 10)
Como se puede ver, el uso es tan sencillo como cargar el modelo guardado previamente y llamar a su función predict pasándole ruido y la etiqueta de clase que queremos generar.
En este caso generamos diferentes números cinco y ocho.


¿Qué usos puede tener una GAN Condicional?
Si recordáis en el artículo anterior, donde explicaba cómo usar TPUs aumentar el rendimiento de nuestra GAN, generábamos rostros de gente famosa. En el caso de usar una GAN condicional podríamos haber indicado características específicas, como el color del pelo, los ojos, el sexo… Una GAN condicional no tiene por qué estar basada en tan solo un indicador de clase, sino que puede recibir varios.
Puede usarse para balancear un dataset, dado la posibilidad que tienen de generar datos del tipo requerido.
Usarse en creación de imágenes donde sea el usuario el que puede indicar algunos de los atributos de la imagen.
Generar imágenes personalizadas, a partir de una entrada de texto, o de la selección de atributos.
¿Qué hemos aprendido?
Hemos dado un paso de gigante en la creación de GANs. Aunque tan solo hemos usado un indicador de clase en nuestra GAN condicional, hemos sentado las bases para crear GANs condicionales mucho más complejas.
Hemos visto como usar la API funcional de TensorFlow para crear modelos no secuenciales y como juntar los diferentes paths para que converjan en un solo modelo.
Hemos usado múltiples entradas para entrenar un modelo. Lo hemos guardado y podemos usar múltiples entradas para generar las imágenes que queremos.
Un artículo muy largo, pero lo andado desde el primer artículo dedicado a las GANs ha sido mucho!
¡Espero que os haya gustado!