Este es el segundo artículo del Tutorial de Redes Generativas Adversarias. En el primero se vio como crear una DCGAN para el Dataset MNIST. Es decir, imágenes de 28×28 en escala de Grises. En este subimos un pequeño peldaño en la complejidad del Dataset y usaremos el Cifar-10. Un dataset también muy conocido, de hecho es uno de los Datasets que vienen con Keras. Este dataset está compuesto por 6000 imágenes de 32×32 a color.
Son imágenes un poco más grandes que las utilizadas en el primer artículo, pero sobre todo se introduce el color. Si habéis llegado a este artículo buscando un tutorial de cómo crear una GAN sencilla, no sufráis, no hace falta que os leáis el artículo anterior.
Voy a empezar dando unas mínimas explicaciones comunes para entender cómo funciona una GAN. Acto seguido pasaremos a ver el código por partes y explicarlo. Finalmente, tendremos el código completo de la GAN.
Los que habéis pasado por el primer artículo y no queréis dar un breve repaso os podéis ir directamente a la sección ¿Qué veremos de más?
El código fuente completo se encuentra en Kaggle, GitHub y Colab:
https://www.kaggle.com/code/peremartramanonellas/gan-tutorial-2-generating-color-images
https://github.com/oopere/GANs/blob/main/C2_GAN_CIFAR.ipynb
https://colab.research.google.com/drive/1atITnzNEDKDIYhGArP2wN2FwFhCVNo2W
Funcionamiento de una GAN.
Una GAN es una red neuronal, normalmente usada para generar imágenes, compuesta de dos redes: un generador y un discriminador.
El Generador recibe una entrada de datos, que son sencillamente ruido. Datos aleatorios ordenados en una forma gaussiana. No sufráis que es tan solo una llamada a una función. Con esta entrada, genera una salida con el formato de la imagen que queremos crear.
Vamos a generar el ruido a usar como entrada para el modelo Generador:
test_noise = tf.random.normal([16, 100])
Esta sencilla llamada nos devuelve el ruido que podemos usar para el generador. Vemos que le estamos indicando que nos devuelva un array de 16 filas con 100 valores cada una. Estas 16 filas las utilizará el generado para crear 16 imágenes diferentes a partir del dato con 100 valores de longitud. Es decir, se necesita una fila para cada imagen a generar.
El tamaño del ruido no tiene por qué ser 100. Es un valor arbitrario, algunos de los valores más usados son: 50, 100, 128, 1024…
Posiblemente, el mejor estudio que se ha realizado por el momento sobre el input noise de una GAN sea el realizado en 2020 por Manisha Pandala, Denoit Das, Sujit Gujar: Effect of input noise Dimension in GANs.
En el estudio se indica que para imágenes como las del Dataset Cifar-10, no se aprecian diferencias entre un valor de 100 y uno de 900, pero que con valores pequeños como 2 o 10 se pierde calidad y variedad en las imágenes generadas.
El otro modelo que forma parte de la GAN, es el Discriminador. Este se encarga de decidir cuando una imagen pertenece al Dataset Original o es Falsa. El discriminador, como entrada, recibe una imagen, en este caso con el formato 32 x 32 x 3, y tiene una salida booleana que indica cuando la imagen es auténtica o falsa.
Ambos modelos se entrenan juntos y modifican sus pesos en función de la capacidad del discriminador para adivinar qué imágenes son verdaderas o falsas.
La intención del generador es crear imágenes que engañen al discriminador. Mientras que el discriminador lo que busca es ser capaz de identificar siempre que imágenes son las generadas por el generador.
¿Qué veremos de más?
Para los que ya habéis pasado por el primer artículo, os explico un poco que veremos de más:
- Imágenes más grandes, por lo que se cambian el input y los upsampling del generador.
- Introducción del color. Se modifica la salida del generador y obviamente la entrada del discriminador.
- Crearemos dos funciones que nos permitirán crear estructuras de GAN flexibles.
- Vamos a usar el suavizador de etiquetas. Una de las GAN Hacks de Soumith Chintala.
Crear el Generador para imágenes a color.
El modelo Generador va transformando los datos de entrada a medida que estos van pasando por las capas del modelo. Con lo que el ruido que se ha usado como entrada, de una longitud de predeterminada, acaba siendo una imagen de 32 x 32 x 3 a la salida del modelo.
Para ello, primero tendremos una capa Densa, que recibirá los datos de entrada y que debe tener nodos suficientes como para contener una versión reducida de la imagen a generar. Pero como queremos que pueda aprender rápidamente en cada paso de cada época, le daremos tamaño para contener X versiones de la imagen reducida.
keras.layers.Dense(4 * 4 * 128, input_shape=[noise_input],
activation=keras.layers.LeakyReLU(alpha=0.2)),
keras.layers.Reshape([4, 4, 128]),
En el generador que vamos a ver, la primera capa densa va a tener nodos suficientes para contener 128 x 4 x 4 es decir 2048 datos. En una segunda capa le cambiamos el shape, para que se adapte a la forma que necesitamos para contener estas imágenes reducidas, o capas de imágenes. Pensemos que queremos convertir el resultado final a 32 x 32 x 3 y por ahora tenemos un shape de 4 x 4 x 128.
A partir de este punto se debe ir realizando un proceso de upsampling hasta llegar al formato de la imagen a generar.
keras.layers.Conv2DTranspose(128, kernel_size=4, strides=2, padding="SAME",
activation=keras.layers.LeakyReLU(alpha=0.2)),
keras.layers.BatchNormalization(),
Este proceso lo ejecuto con una capa Conv2DTranspose. Que va duplicando el tamaño de la imagen. Al tener el parámetro strides informado con el valor 2 los datos se multiplican por 4, y en esta primera pasada pasaríamos de tener un shape de 4 x 4 = 16, a un shape de 8 x 8 = 64.
Después de la capa de Conv2DTranspose uso una capa de BartchNormalization. Esta capa le da estabilidad al sistema. Coge la salida de la capa anterior y los normaliza antes de pasarlos a la siguiente capa.
Como activador se está usando una capa LeakyReLU, dentro de la capa Conv2DTranspose. Realmente podríamos usarla como una capa externa y situarla detrás de la capa BatchNormalization para que recibiera la entrada normalizada.
Una estructura alternativa podría ser:
#Otra opción posible para realizar el upsampling. keras.layers.Conv2DTranspose(128, kernel_size=4, strides=2, padding="SAME"), keras.layers.BatchNormalization(), keras.layers.LeakyReLU(alpha=0.2),
Pero para el dataset usado no he notado diferencia en la calidad de las imágenes generadas. Tampoco creo que podamos encontrar diferencias de rendimiento, así que dependerá de las preferencias de cada uno usar LeakyReLU como una capa aparte o como activador en Conv2DTranspose.
En el generador final, este proceso de upsampling se va a tener que repetir tres veces, para que la imagen pase de un tamaño de 4 x 4 a uno de 32 x 32.
Para finalizar el modelo Generador tenemos que tener una capa cuya salida coincida con el shape de la imagen a generar.
keras.layers.Conv2DTranspose(3, kernel_size=4, strides=2, padding="SAME",
activation='tanh'),
])
He aprovechado la última capa Conv2DTranspose para dar el shape necesario a la salida. La solución más común es usar una capa Conv2D para dar el formato a la salida, y mantener la capa Conv2DTranspose para efectuar el Upsample con un número de nodos más elevado.
#Otra alternativa para finalizar el modelo Generador.
keras.layers.Conv2DTranspose(128, kernel_size=4, strides=2, padding="SAME",
activation=keras.layers.LeakyReLU(alpha=0.2)),
keras.layers.BatchNormalization(),
keras.layers.Conv2D(3, kernel_size=5, activation='tanh', padding='same')
En ambas alternativas el activador de la última capa es tanh, no importa si usamos una Conv2DTranspose como Conv2D. Este activador nos asegura un rango de salida entre -1 y 1, el mismo que hemos usado al normalizar la entrada. Es una de las recomendaciones que se pueden encontrar en las GAN Hack.
Ha llegado el momento de juntarlo todo y ver el código del generador que he usado para la GAN.
noise_input = 100
generator = keras.models.Sequential([
keras.layers.Dense(4 * 4 * 128, input_shape=[noise_input],
activation=keras.layers.LeakyReLU(alpha=0.2)),
keras.layers.Reshape([4, 4, 128]),
keras.layers.BatchNormalization(),
#First UpSample doubling the size to 8x8
keras.layers.Conv2DTranspose(128, kernel_size=4, strides=2, padding="SAME",
activation=keras.layers.LeakyReLU(alpha=0.2)),
keras.layers.BatchNormalization(),
#Second UpSample doubling the size to 16x16
keras.layers.Conv2DTranspose(128, kernel_size=4, strides=2, padding="SAME",
activation=keras.layers.LeakyReLU(alpha=0.2)),
keras.layers.BatchNormalization(),
#Last UpSample doubling the size to 32x32, and shaping the output.
keras.layers.Conv2DTranspose(3, kernel_size=4, strides=2, padding="SAME",
activation='tanh'),
])
Este es el código del generador, con su entrada, el cuerpo principal donde se realizan los upsamples, y su capa de salida.
Como se puede ver uso el mismo número de nodos en las dos capas Conv2DTranpose. Una práctica común es reducir el número de nodos a medida que se ejecuta el upsampling. Pero en este caso en concreto, como aprovecho la última capa Conv2DTranspose como capa de salida y sus nodos ya se han reducido bastante, no hace falta irlos reduciendo en las capas previas.
Al final del artículo hay un generador que reduce el número de nodos entre upsamplings. En el notebook de Colab podéis encontrar los dos, y comparar el resultado
En el generador se han utilizado varias de las recomendaciones conocidas como GAN Hacks.
- El uso de LeakyReLU.
- El empleo de capas BatchNormalization.
- Que kernel_size sea divisible por strides.
- Usar el activador tanh en la última capa.
Resumiendo se ha creado un generador muy sencillo, pero muy optimizado para el Dataset usado.

Crear el discriminador de la GAN.
El discriminador va a ser responsable de identificar que imagen es real y cuál no lo es. Como entrada recibirá una imagen y la salida va a ser un booleano.
El Discriminador es más sencillo que el Generador. En lugar de hacer un upsampling va a ir realizando un downsizing de los datos usando capas Conv2D. Para finalmente allanar los datos con una capa Flatten y pasar el resultado a la capa Densa que decidirá si los datos pertenecen a una imagen real o falsa.
discriminator = keras.models.Sequential([
keras.layers.Conv2D(64, kernel_size=5, strides=2, padding="SAME",
activation=keras.layers.LeakyReLU(0.2),
input_shape=[32, 32, 3]),
keras.layers.Dropout(0.4),
keras.layers.Conv2D(64, kernel_size=3, strides=2, padding="SAME",
activation=keras.layers.LeakyReLU(0.2)),
keras.layers.Dropout(0.4),
keras.layers.Conv2D(64, kernel_size=3, strides=2, padding="SAME",
activation=keras.layers.LeakyReLU(0.2)),
keras.layers.Dropout(0.4),
keras.layers.Flatten(),
keras.layers.Dense(1, activation="sigmoid")
La primera capa convolucional del modelo recibe los datos con el shape 32 x 32 x 3. Mientras que la salida está marcada por una capa Densa de 1 solo nodo, con una activación sigmoid, lo que nos asegura obtener un 0 o un 1 como resultado.
Como se puede ver he usado tres capas de Dropout, con un rate bastante alto, de 0.4. Lo uso para que el discriminador no se adapte demasiado bien a los datos reales del dataset y prevenir así que se vuelva demasiado bueno identificando que imágenes son verdaderas y cuáles son falsas, lo que podría impedir al generador empezar a generar imágenes con las que poder engañar al discriminador.
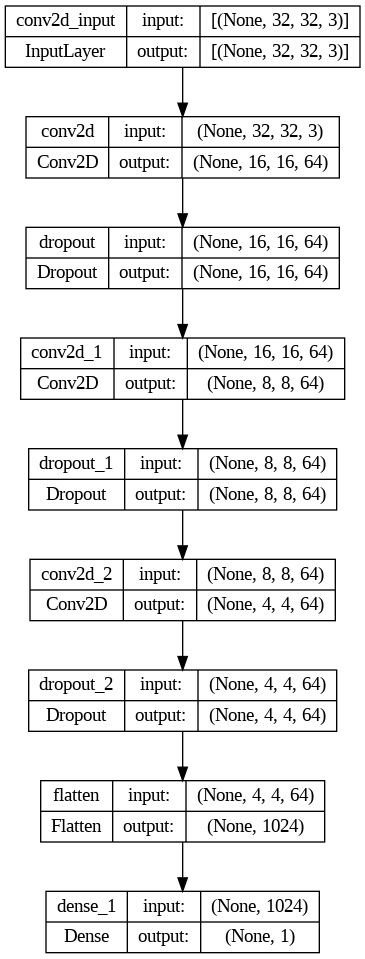
En cada una de las capas convolucionales la salida se reduce al 50 % de la entrada. Con lo que pasamos de los 32×32 de la primera capa a 4x4x64 de la última antes de allanar los datos con una capa Flatten.
He mantenido el número de nodos en las capas convolucionales, aunque es una práctica común aumentarlo a medida que se va reduciendo el tamaño de los datos. Igual que con el generador encontramos un ejemplo al final del artículo y en el notebook en Colab, donde sí que aumento el número de nodos y podemos comparar el resultado.
Función para entrenar la GAN.
Ahora que tenemos los dos modelos, el generador y el discriminador, se tiene que construir una función que los utilice conjuntamente para entrenar la GAN y conseguir generar imágenes que puedan ser tomadas como verdaderas.
El código, y, por tanto, las explicaciones a dar, son 95 % idénticos a las del primer artículo de la serie sobre GAN:
Os recomiendo que os paséis por él para obtener más detalle de la función de entreno. Si no os queréis pasar, no os preocupéis, voy a explicar lo básico.
La función está compuesta por dos grandes bloques, en uno entrenamos el discriminador y en el otro la GAN completa.
En el primer bloque entrenamos el discriminador y para ello le pasamos un conjunto de datos formado por imágenes generadas e imágenes del Dataset, con sus respectivas etiquetas. Para entrenar al discriminador llamamos a su función train_on_batch, asegurándonos de que sus capas pueden ser entrenadas poniendo el valor de discriminitor.trainable a True.
En el segundo bloque pasamos a entrenar el Generador, para ello se llama a la función train_on_batch de la GAN. A la función le pasamos un bloque de imágenes falsas generadas por el generador, pero etiquetadas como si fueran imágenes verdaderas.
Antes de realizar la llamada a la función train_on_batch de la GAN, nos tenemos que asegurar que hemos marcado las capas del discriminador como no entrenables. Al estar usando la GAN el generador sé irá entrenando dependiendo del éxito que tenga al engañar al discriminador. Por eso nos interesa que tan solo se puedan modificar las capas del Generador, ya que el discriminador ya lo entrenamos en el paso previo.
Una de las diferencias con el artículo anterior, es que en este he usado lo que se llama suavizador de etiquetas. Es decir, en lugar de marcar todas las etiquetas como 0 si son falsas o 1 si son verdaderas se ha usado unos límites. Las etiquetas falsas se marcan con valores entre 0 y 0.3, mientras que las verdaderas tendrán valores entre 0.8 y 1.2.
Para suavizar las etiquetas he usado estas dos funciones:
def smooth_positive(y): return y -0.2 + (np.random.random(y.shape) * 0.4) def smooth_negative(y): return y + np.random.random(y.shape) * 0.3
Los valores del suavizado están dentro de los márgenes recomendados en las GAN Hacks, aunque los he reducido un poco. Hay discusión sobre si suavizar tan solo las etiquetas positivas o hacerlo también con las negativas, yo he optado por suavizar ambas.
def train_gan(gan, dataset, random_normal_dimensions, n_epochs=30):
#recuperamos las capas de la GAN, que contiene el generador y el discriminador.
generator, discriminator = gan.layers
#Recorremos el dataset entero en cada epoca.
for epoch in range(n_epochs):
print("Epoch {}/{}".format(epoch + 1, n_epochs))
for real_images in dataset:
# calculamos el batch size
batch_size = real_images.shape[0]
# PRIMERA FASE: ENTRENAMOS EL DISCRIMINADOR.
# Se crea el ruido a usar como entrada para el generador.
noise = tf.random.normal(shape=[batch_size, random_normal_dimensions])
# Generamos imágenes falsas con el generador.
fake_images = generator(noise)
# concatenamos las imágenes falsas con las reales.
mixed_images = tf.concat([fake_images, real_images], axis=0)
# Creamos las etiquetas para el discriminador.
# 0 / 0.3 para las falsas
# 0.8 / 1.2 Para las reales.
discriminator_zeros = smooth_negative(np.zeros((batch_size, 1)))
discriminator_ones = smooth_positive(np.ones((batch_size, 1)))
discriminator_labels= tf.convert_to_tensor(np.concatenate((discriminator_zeros, discriminator_ones)))
# Aseguramos que las capas del discriminador pueden ser entrenadas.
discriminator.trainable = True
# Llamamos al train_on_batch del discriminador pasandole las imagenes y las etiquetas.
discriminator.train_on_batch(mixed_images, discriminator_labels)
# SEGUNDA FASE: ENTRENAMOS EL GENERADOR.
# Creamos el ruido que servirá como entrada de la GAN
noise = tf.random.normal(shape=[batch_size, random_normal_dimensions])
# Creamos etiquetas "reales" para las imagenes falsas.
generator_ones = smooth_positive(np.ones((batch_size, 1)))
generator_labels = tf.convert_to_tensor(generator_ones)
# Congelamos el discriminador.
discriminator.trainable = False
# entrenamos la GAN pasandole el ruido y las etiquetas.
gan.train_on_batch(noise, generator_labels)
# Imprimiomos las imagenes en cada epoca.
plot_results(fake_images, 8)
plt.show()
Con esto ya lo tenemos casi todo, faltan las funciones auxiliares para imprimir las imágenes, la carga de librerías, pero todo esto se puede encontrar en el notebook en Google Colab.
De momento podemos ver el resultado y compararlo con las imágenes del Dataset original.



Parece claro que nuestro Generador está entendiendo el tipo de imágenes que busca el discriminador, y que a medida que avanzan las épocas va consiguiendo imágenes más afinadas.
Es posible que el generador esté consiguiendo engañar cada vez más al discriminador, pero, salvo excepciones, no creo que consigan engañar a un humano. Nosotros sabemos que dentro de cada Imagen de Cifar-10 hay un objeto reconocible en el mundo real, que puede ser un coche, un animal, un camión… cualquier elemento que pertenezca a una de las categorías del Cifar-10.
Con este Dataset me he encontrado con dos problemas que voy a intentar solucionar en uno de los futuros artículos de la serie.
- Hacer pruebas es muy lento. Entrenar una GAN haciendo uso de las GPU no es suficiente. Tendré que empezar a usar las TPU que ofrecen Kaggle y Colab.
- ¿Cómo se mide el rendimiento de una GAN? Está claro que una forma es mirar el resultado. Muchas veces la única. El problema es que no siempre la última época es la que produce mejor resultado. Este tema hay que tratarlo aparte.
Funciones para crear un Generador y un discriminador Genéricos.
En estos dos primeros artículos hemos visto que el esqueleto del generador y del discriminador han sido muy parecidos. Se han necesitado un número diferente de upsizings y una entrada y salida diferentes. Pero la base es la misma.
Parece claro que la creación del Generador y del discriminador puede encapsularse en dos funciones.
def adapt_generator(initial_0, initial_1, nodes, upsamplings, multnodes = 1.0, endnodes = 3, input_noise=100):
#initial_0, initial_1: size of the initial mini image.
#nodes: nodes in the first Dense layers.
#upsamplings: number of upsamplings bucles.
#multnodes: a multiplicator to modify the nodes in each upsampling bucle.
#endnodes: nodes of the last layer.
#input_noise: size of the noise.
model = keras.models.Sequential()
#First Dense layer.
model.add(keras.layers.Dense(initial_0 * initial_1 * nodes, input_dim=input_noise,
activation=keras.layers.LeakyReLU(alpha=0.2)))
model.add(keras.layers.Reshape([initial_0, initial_1, nodes]))
model.add(keras.layers.BatchNormalization())
#Upsampling bucles.
nodeslayers = nodes
for i in range(upsamplings-1):
nodeslayers = nodeslayers * multnodes
model.add(keras.layers.Conv2DTranspose(nodeslayers , kernel_size=4, strides=2, padding="SAME",
activation=keras.layers.LeakyReLU(alpha=0.2)))
model.add(keras.layers.BatchNormalization())
#last upsample and last layer.
model.add(keras.layers.Conv2DTranspose(endnodes, kernel_size=4, strides=2, padding="SAME",
activation='tanh'))
return model
En la función para crear el generador podemos indicar:
- el tamaño de la mini imagen inicial
- El número de nodos de la primera capa.
- El número de upsamplings a realizar (cada upsampling dobla el tamaño de la imagen).
- Un multiplicador para variar el número de nodos.
- Los nodos de la última capa.
- El tamaño del ruido usado como input de la primera cada densa.
Para esta llamada:
adapt_gene = adapt_generator(4, 4, 128, 3, multnodes = 0.5)
Obtendremos este modelo:
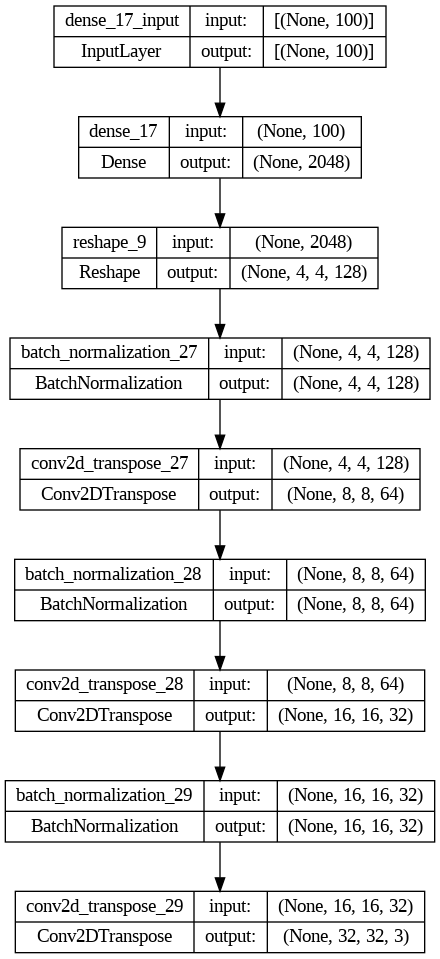
Como hemos indicado un multnodes de 0.5 los nodos se reducen a la mitad en cada iteración de upsampling.
def adapt_discriminator(nodes, downsamples, multnodes = 1.0, in_shape=[32, 32, 3]):
#nodes: nodes in the first Dense layers.
#downsamples: number of downsamples bucles.
#multnodes: a multiplicator to modify the nodes in each downsample bucle.
#in_shape: Shape of the input image.
model = keras.models.Sequential()
#input layer % first downsample
model.add(keras.layers.Conv2D(nodes, kernel_size=5, strides=2, padding="SAME",
activation=keras.layers.LeakyReLU(0.2),
input_shape=in_shape))
model.add(keras.layers.Dropout(0.4))
#creating downsamples
nodeslayers = nodes
for i in range(downsamples - 1):
nodeslayers = nodeslayers * multnodes
model.add(keras.layers.Conv2D(nodeslayers, kernel_size=3, strides=2, padding="SAME",
activation=keras.layers.LeakyReLU(0.2)))
model.add(keras.layers.Dropout(0.4))
#ending model
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(1, activation="sigmoid"))
return model
El discriminador nos permite indicar:
- Los nodos de la capa inicial.
- El número de downsamples que queremos realizar.
- Un multiplicador para modificar el número de nodos en cada downsample.
- El shape de la imagen de entrada.
adapt_disc = adapt_discriminator(64, 3, multnodes = 2)
Con esta llamada obtenemos el discriminador:

En este caso, como se ha dado un multnodes de 2.0 el número de nodos se duplica en cada upsample.
La creación de la GAN, el entreno y compilación sería exactamente el mismo que para un Generador y Discriminador creados de la forma tradicional.
#Creamos la GAN juntando los dos modelos. adapt_gana2 = keras.models.Sequential([adapt_gene, adapt_disc]) #Creamos el optimizador siguiendo los consejos de las GAN Hacks optimizer = keras.optimizers.Adam(learning_rate=0.0002, beta_1=0.5) #Compilamos el discriminador. adapt_disc.compile(loss='binary_crossentropy', optimizer=optimizer, metrics=['accuracy']) #Marcamos las capas del discriminador como no entrenables. adapt_disc.trainable = False #Compilamos el Generador. adapt_gana2.compile(loss="binary_crossentropy", optimizer=optimizer) #Llamamos a la función de entreno de la GAN train_gan(adapt_gana2, dataset, noise_input, 30)


A mí me parece que el resultado con estos segundos modelos ha sido mejor que con los primeros. Por lo que el uso de reducción de nodos en el generador y aumento en el discriminador ha aportado buenos resultados. La mejora más importante se ve con las imágenes generadas con 30 épocas.
En las imágenes generadas con 100 épocas de entreno se empiezan a apreciar figuras. En tres de ellas se podría adivinar un vehículo, y algunas de las figuras se podrían confundir con animales.
¿Qué hemos aprendido?
Hemos usado un nuevo dataset que nos pedía que realizáramos un número diferente de Upsamples al realizado en el artículo anterior. Con lo que espero que nos haya quedado mucho más claro como se construye la estructura principal de una GAN.
Aprovechando que ya lo tenemos claro, lo hemos encapsulado en un par de funciones que nos permiten crear diferentes modelos de GAN que se adapten a diferentes datasets cambiando tan solo los parámetros en su llamada.
También hemos usado un nuevo GAN Hack: el suavizado de las etiquetas de las imágenes utilizadas.
¿Cómo continuar?
Aprovechando que tenemos estas dos funciones que nos permiten crear Generadores y Discriminadores, se podrían aprovechar para crear un modelo que funcionase con el Dataset MNIST.
Jugad con las funciones y probar diferentes modelos y medid como afecta al rendimiento y si las imágenes generadas son peores o mejores.
Estamos justo al principio de este viaje. El proximo Dataset contiene imágenes que aún pueden ser consideradas como pequeñas, pero que ya duplican las usadas hasta ahora. Está claro que cada vez es más necesario que aprendamos a mejorar el rendimiento usando TPU’s. También sería muy útil tener algún método que nos permita medir el rendimiento de nuestra GAN.
Queda mucho por venir, y vamos a llegar a modelos de GAN más complejos como pueden ser las GAN condicionales.