
Este es el primer artículo de una serie que va a tratar sobre redes generativas adversarias. Conocidas como GAN, que viene de su nombre en inglés: Generative Adversarial Network. En este primer artículo usaremos uno de los Datasets más sencillos compuesto por imágenes de números escritos a mano de 28 x 28 en escalas de grises. Supongo que ya todos sabéis que se trata del famosísimo Dataset MNIST. Trabajaremos con TensorFlow, Keras y Python.
Al mismo tiempo que vamos viendo la teoría, veremos el código necesario para la creación y entreno de la GAN. Aunque sea nuestra primera GAN usaremos varias de las recomendaciones lanzadas por Soumith Chintala, conocidas como GAN Hacks. Así crearemos una GAN correctamente optimizada para el Dataset utilizado.
Después de la teoría y de ver el código separado de cada paso, pasaremos a crear un modelo de GAN completo, explicando el porqué de las decisiones tomadas y utilizando parte de las recomendaciones que hemos visto y que ya se han establecido como un estándar.
Como punto final he generado un modelo con ChatGPT para el mismo Dataset y lo vamos a comparar con el creado para el artículo.
Me gustaría destacar que aunque las GAN se suelen emplear para generar imágenes, también se pueden aprovechar en otros campos, por ejemplo se podría generar texto o sonido, y que veremos GAN creando este tipo de contenido en artículos más avanzados.
El notebook con el código completo está disponible en Kaggle:
https://www.kaggle.com/code/peremartramanonellas/gan-tutorial-first-dcgan-using-tensorflow
Github:
https://github.com/oopere/GANs/blob/main/C1_GAN_MNIST1.ipynb
Google Colab.
https://colab.research.google.com/drive/1eRJiQuLF0PTYg7nnPIDKlh3tCL27YtIw
¿Cómo funciona una GAN?
Una GAN se emplea para entrenar un modelo generativo, es decir, para producir contenido. Está compuesta de dos modelos que trabajan conjuntamente. Una vez entrenado, el modelo generativo puede separarse de la GAN y usarse en solitario.
Los modelos que podemos encontrar en una GAN son:
- Modelo Generador: Se encarga de producir las imágenes, o el contenido que queremos que sea generado por la GAN.
- Modelo Discriminador. Decide cuando una imagen es verdadera o falsa.
- Modelo GAN. La suma de los dos modelos.
Por ahora, tenemos un modelo que genera imágenes y otro que decide si estas son reales o no. Hay que poner a funcionar estos modelos juntos hasta que el modelo generador sea capaz de crear imágenes que engañen al discriminador y este sea incapaz de diferencias las imágenes reales de las generadas.
¿Cómo funciona el modelo Generador de una GAN?
Como cualquier modelo, transforma una entrada en una salida. En este caso la salida será una imagen de 28×28 en escala de grises, ya que vamos a emplear el archiconocido dataset MNIST, para nuestra primera GAN.
Como entrada, el generador, recibirá datos aleatorios, que podríamos llamar ruido. Estos datos toman la forma de un vector siguiendo una distribución Gaussiana. Hablando en plata, un vector de números aleatorios. No es una imagen, ni falta que hace.
test_noise = tf.random.normal([16, noise_input])
Con esta línea estaremos creando un vector con de 16 x noise_input de valores aleatorios que siguen una distribución gaussiana. Que nos podría servir para que el generador pudiera producir 16 imágenes falsas.
El modelo transformará esta entrada en 16 imágenes falsas que serán enviadas al discriminador. Por lo que los datos deberán pasar por un proceso de upsamplig a medida que avancen por la estructura de capas de nuestro modelo.
Para una entrada del tamaño de noise_input se deberá producir una salida de 28 x 28 x 1. El 1 es porque al ser una imagen de escala de grises no tiene la profundidad del color. Para realizar esta transformación va a tener que realizar principalmente dos acciones: darle sentido a los números y escalarlos porque necesitamos más valores de los que tenemos.
Veamos la forma sencilla de crear las primeras capas del generador.
tf.keras.Layers.Dense(128 * 7 * 7, input_dim=noise_input), tf.keras.layers.Reshape([7, 7, 128])
En la primera capa se alimentan los nodos de la capa densa con el ruido de entrada. La segunda le cambia el shape para que sea más sencillo transformar los datos para que lleguen a la salida de la última capa con el shape de la imagen.
Como salida del modelo queremos obtener una imagen de 28×28. Por ahora, después de estas capas, tenemos una forma de 7×7 con 128 features. Tendremos que hacer un upsampling para pasar de 7×7 a 14×14.
La forma más sencilla de hacer el upsampling sería con una capa Upsampling2D seguida de una capa Convolutional. Pero, aunque sería suficiente para nuestro modelo, es mucho más potente y óptimo usar una capa Conv2DTranspose. Así que nos saltamos el paso de la capa Upsampling2D y lo creamos directamente con la capa Conv2dTranspose. Con lo que nuestro modelo seguiría con la capa:
tf.keras.layers.Conv2DTranspose(64, kernel_size=4, strides=2, padding="SAME",
activation=keras.layers.LeakyReLU(alpha=0.2))
Como se puede ver, Conv2DTranspose es una capa muy potente y flexible que recibe multitud de parámetros. La mayoría de los parámetros son compartidos con una capa Convolutional y se comportan de la misma forma. En este caso el que más nos importa es el número de strides.
Al indicar un 2 en los strides, que también podría escribirse como (2, 2), se duplica el tamaño de la salida, y obtenemos 14×14 en lugar de 7×7. El tamaño del kernel es recomendable mantenerlo como un factor de los strides, por lo que he puesto 4.
Podemos ver que se han reducido las features de 128 a 64. No es necesario, tan solo que al tratarse de un Dataset tan sencillo con 64 ya son suficientes y se acelera la ejecución del modelo al tener menos parámetros que procesar.
A destacar el uso de la activación LeakyRelu. Esta activación, a diferencia de una Relu estándar, permite valores negativos. En lugar de ajustar cualquier valor negativo a 0, lo hará multiplicando a alpha * valor. Es decir, un valor negativo de -2 en nuestro caso sería -2 * 0.2 = -0. 4
Con lo que el paso de información a través de la red es más suave, ya que no se cortan tanto los valores negativos. El valor recomendado para usar como alpha es de 0.2.
Esta recomendación, junto a muchas otras que iremos viendo, son conocidas como GAN HACK’s, y fueron presentadas por Soumith Chintala en el 2016: https://github.com/soumith/ganhacks
Para que el valor de salida del modelo sea de 28×28 se necesita otra capa Conv2DTranspose para realizar otro upsampling. Esta capa va a ser la última del modelo, por lo que nos tenemos que asegurar que su salida sea de 28 x 28 x 1. Es decir, exactamente el formato de las imágenes del dataset MNIST.
keras.layers.Conv2DTranspose(1, kernel_size=4, strides=2, padding="SAME", activation='tanh'),
Otra de las recomendaciones es usar el activador tanh en la última capa del modelo. Limita la salida de la capa a un rango de valores de entre -1 y 1. Sus gradientes también son más estables que los de un activador sigmoide (otra recomendación), y puede ayudar a mejorar la velocidad y estabilidad. En todo caso, estas explicaciones, muchos nos las tenemos que creer, ya que han sido probadas empíricamente y la documentación nunca es del todo concluyente. Pero en este caso el resultado obtenido con tanh es muy bueno, mucho mejor que con sigmoid. ¡Os animo a probarlo!
Ahora tocaría montar estas capas y crear el modelo generador entero. Veamos cómo queda:
generator = keras.models.Sequential([
keras.layers.Dense(7 * 7 * 128, input_shape=[noise_input],
activation=keras.layers.LeakyReLU(alpha=0.2)),
keras.layers.Reshape([7, 7, 128]),
keras.layers.BatchNormalization(),
#First UpSample doubling the size to 14x14
keras.layers.Conv2DTranspose(64, kernel_size=4, strides=2, padding="SAME",
activation=keras.layers.LeakyReLU(alpha=0.2)),
keras.layers.BatchNormalization(),
#Second UpSample doubling the size to 28x28
keras.layers.Conv2DTranspose(1, kernel_size=4, strides=2, padding="SAME",
activation='tanh'),
])
Como podéis ver he incorporado dos capas BatchNormalization entre las capas Conv2DTranspose. Intentando suavizar el resultado de las diferentes capas, ayudando a la estabilidad y rapidez del entreno. No serían del todo necesarias, pero he obtenido mejores resultados usando las capas BatchNormalization.
Está claro que este no es el único modelo posible. Incluso yo tengo serias dudas sobre si utilizar algunas de las diferentes variaciones que he estado probando.
Una mejora que se me ocurre es sacar la activación de la Conv2DTranspose para ponerla en una capa externa y tener la capa de BatchNormalization entre las dos, y que quede de esta forma:
keras.layers.Conv2DTranspose(128, kernel_size=4, strides=2, padding="SAME"), keras.layers.BatchNormalization() keras.layers.LeakyRelu(0.2)
Pero no he probado esta combinación. Os lo dejo a vosotros 🙂
Este es uno de los cientos de generadores posibles para solucionar el problema. Lo que todos deberán tener en común es una entrada de ruido aleatorio y un proceso de upsampling hasta llegar al tamaño de la imagen que queremos generar.
Podemos ver la forma final de nuestro modelo en el siguiente plot:
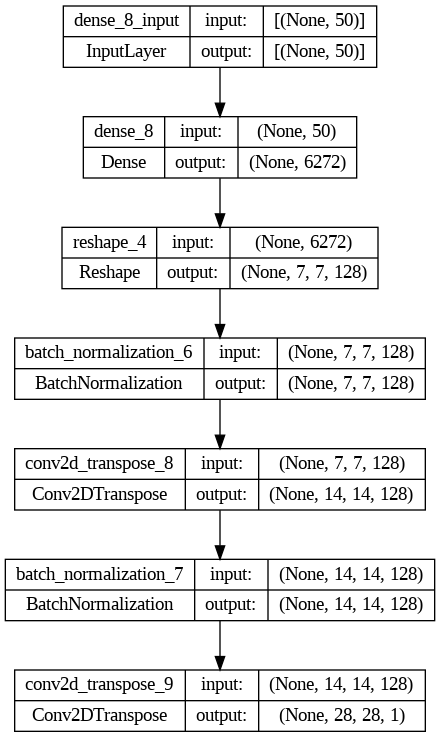
Fijaos como en cada una de las dos capas de Conv2DTranspose la salida, dobla a la entrada y el modelo finaliza con una imagen 28x28x1.
¿Cómo creamos el modelo Discriminador de nuestra GAN?
Este modelo es el responsable de decidir si una imagen es verdadera o falsa. Por lo tanto, está claro que como entrada va a recibir una imagen de 28x28x1 y como salida tendrá un valor binario.
discriminator = keras.models.Sequential([
#downsizing from 28x28 to 14x14
keras.layers.Conv2D(64, kernel_size=5, strides=2, padding="SAME",
activation=keras.layers.LeakyReLU(0.2),
input_shape=[28, 28, 1]),
keras.layers.Dropout(0.4),
#downsizing from 14x14 to 7x7
keras.layers.Conv2D(64, kernel_size=3, strides=2, padding="SAME",
activation=keras.layers.LeakyReLU(0.2)),
keras.layers.Dropout(0.4),
keras.layers.Flatten(),
keras.layers.Dense(1, activation="sigmoid")
])
El modelo discriminador es más sencillo que el generador. Hacemos un downsizing usando las capas convolucionales y un stride de 2, con lo que las dimensiones de los datos de entrada se reducen a la mitad.
En el discriminador usamos varias de las recomendaciones lanzadas por Soumith Chintala, como el uso de los activadores LeakyRelu, o el uso de las capas Dropout.
Antes de pasar los datos a la última capa densa los allanamos con la capa Flatten. La capa Densa final emplea un activador sigmoid porque tan solo nos interesan los valores 0 y 1. Es decir, que marque a la imagen como falsa o auténtica.
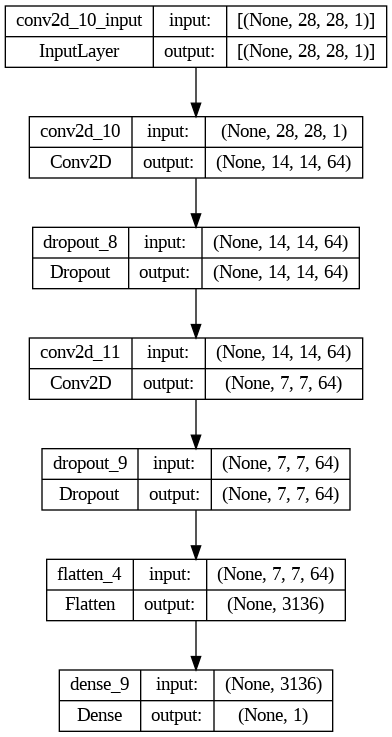
Se puede observar como las capas Conv2D reducen la dimensionalidad de los datos, al contrario de lo que sucede con las capas Conv2DTranspose.
Como optimizador del modelo usaremos Adam y como función de pérdida emplearemos binary_crossentropy. Las dos decisiones se basan en las GAN HACKS.
optimizer = keras.optimizers.Adam(learning_rate=0.0002, beta_1=0.5) discriminator.compile(loss='binary_crossentropy', optimizer=optimizer, metrics=['accuracy'])
Entrenando a la GAN.
Hemos creado, dos modelos separados. Uno genera imágenes a partir de ruido y el otro puede identificar cuando una imagen es real o no. Ahora ni el Generador es capaz de generar nada que se parezca mínimamente a lo que queremos, ni el discriminador es capaz de saber cuándo una imagen es real o no. Se deben entrenar los dos modelos y lo vamos a hacer conjuntamente.
Lo primero que tenemos que hacer es juntarlos en un solo modelo.
gan = keras.models.Sequential([generator, discriminator]) optimizer = keras.optimizers.Adam(learning_rate=0.0002, beta_1=0.5) gan.compile(loss="binary_crossentropy", optimizer=optimizer)
Para el modelo general emplearemos el optimizador y la función de pérdida que hemos usado en el Discriminador. Siguiendo las mismas recomendaciones.
Los dos modelos vamos a entrenarlos juntos en una función. Los pasos serían:
- Creamos un bucle para ejecutar las épocas necesarias. Dentro de cada época se ejecutan los pasos para cada lote de imágenes. En cada paso se entrena el discriminador y el generador.
- Entrenamos el discriminador con un juego de imágenes compuesto por imágenes reales provenientes del Dataset e imágenes fake que han sido creadas por el generador. Los dos tipos de imágenes irán con su correspondiente etiqueta 0 para las imágenes falsas y 1 para las reales.
- Entrenamos el generador. Pasando un juego de imágenes falsas, con etiquetas de imagen verdadera al modelo completo de la GAN. Para que el discriminador no actualicé sus pesos con esta información falsa se le indica que sus capas no son entrenables.
Vamos a ver el código para entrenar el discriminador.
# Entrenamos el discriminador
# creamos ruido
noise = tf.random.normal(shape=[batch_size, random_normal_dimensions])
# pasamos el ruido al generador para crear imagenes falsas.
fake_images = generator(noise)
# se crean las etiquetas. O para falsas 1 para reales.
mixed_images = tf.concat([fake_images, real_images], axis=0)
# Creamos etiquetas 0 para imagenes falsa, 1 para las reales del Dataset.
discriminator_labels = tf.constant([[0.]] * batch_size + [[1.]] * batch_size)
# Indicamos que las capas del distriminador son entrenables.
discriminator.trainable = True
# llamamos al train_on_batch del discriminador.
discriminator.train_on_batch(mixed_images, discriminator_labels)
Como queremos entrenar el Discriminador es muy importante que nos aseguremos que sus capas pueden ser entrenadas, por lo que ponemos el valor True en su atributo trainable antes de la llamada a train_on_batch. En el código podemos ver todos los pasos para realizar una llamada al discriminador.
Veamos el código utilizado dentro de la época para entrenar el generador:
# Entrenamos el generador
# Se crea un lote de ruido para alimentar al generador.
noise = tf.random.normal(shape=[batch_size, random_normal_dimensions])
# Etiquetamos todas las imagenes falsas generadas como si fueran reales.
generator_labels = tf.constant([[1.]] * batch_size)
# Congelamos las capas del discriminador para que no aprenda.
discriminator.trainable = False
# Se entrena a la GAN usando el ruido.
gan.train_on_batch(noise, generator_labels)
Pasamos el ruido generado y las etiquetas a la GAN para que ejecutando el generador y el discriminador vaya ajustando los pesos del generador para ir produciendo en cada paso imágenes de mejor calidad.
El generador produce una imagen falsa con la etiqueta de imagen real, es decir, un 1. El discriminador devuelve un valor de 0 si opina que la imagen es falsa, o un valor de 1 si piensa que la imagen es real. En las primeras épocas el discriminador será capaz de identificar todas las imágenes falsas. Por lo que el generador modificará sus pesos lo máximo que pueda.
Veamos el código completo de la función de entreno de la GAN:
def train_gan(gan, dataset, random_normal_dimensions, n_epochs=50):
""" El loop de entreno de la GAN en dos fases.
Args:
gan -- El modelo que contiene el generador y el discriminador.
dataset -- el dataset de las imagenes reales.
random_normal_dimensions -- ddimension del input del generador.
n_epochs -- numero de epocas que queremos entrenar.
"""
#Obtenemos el generador y el discriminador, ya que son las dos capas que forman el modelo general.
generator, discriminator = gan.layers
for epoch in range(n_epochs):
print("Epoch {}/{}".format(epoch + 1, n_epochs))
for real_images in dataset:
# infer batch size from the training batch
batch_size = real_images.shape[0]
# Train the discriminator - PHASE 1
# create the noise
noise = tf.random.normal(shape=[batch_size, random_normal_dimensions])
# use the noise to generate fake images
fake_images = generator(noise)
# create a list by concatenating the fake images with the real ones
mixed_images = tf.concat([fake_images, real_images], axis=0)
# Create the labels for the discriminator
# 0 for the fake images
# 1 for the real images
discriminator_labels = tf.constant([[0.]] * batch_size + [[1.]] * batch_size)
# ensure that the discriminator is trainable
discriminator.trainable = True
# use train_on_batch to train the discriminator with the mixed images and the discriminator labels
discriminator.train_on_batch(mixed_images, discriminator_labels)
# Train the generator - PHASE 2
# create a batch of noise input to feed to the GAN
noise = tf.random.normal(shape=[batch_size, random_normal_dimensions])
# label all generated images to be "real"
generator_labels = tf.constant([[1.]] * batch_size)
# freeze the discriminator
discriminator.trainable = False
# train the GAN on the noise with the labels all set to be true
gan.train_on_batch(noise, generator_labels)
Con esto tendríamos casi todo el código necesario. Falta la carga del Dataset, las funciones auxiliares, la carga de librerías. Todo el código lo podéis encontrar todo en este notebook disponible en Google Colab.
De momento veamos el resultado:
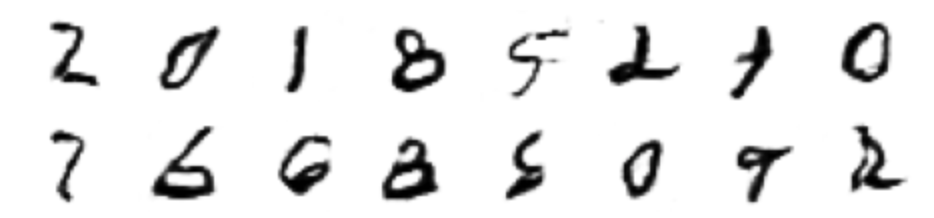
No está nada mal, 30 épocas no son demasiadas y el resultado obtenido es muy digno.
Usamos ChatGPT para crear una GAN.
He decidido poner a prueba a ChatGPT y crear un modelo con la tan famosa herramienta generativa de texto.
Le he pedido que actúe como un experto en Machine Learning que quiere crear una GAN como ejemplo para personas que están aprendiendo. Utilizando el dataset MNIST, con TensorFlow, Python y Keras.
Y lo ha hecho, me ha generado el Discriminador y el Generador.
generator = keras.models.Sequential([
keras.layers.Dense(7 * 7 * 64, activation=keras.layers.LeakyReLU(0.2), input_shape=(noise_input,)),
keras.layers.Reshape((7, 7, 64)),
keras.layers.Conv2DTranspose(64, (3, 3), strides=(2, 2), padding='same', activation=keras.layers.LeakyReLU(0.2)),
keras.layers.Conv2DTranspose(32, (3, 3), strides=(2, 2), padding='same', activation=keras.layers.LeakyReLU(0.2)),
keras.layers.Conv2D(1, (3, 3), padding='same', activation='tanh')
])
discriminator = keras.models.Sequential([
keras.layers.Conv2D(32, (3, 3), strides=(2, 2), padding='same', input_shape=(28, 28, 1)),
keras.layers.LeakyReLU(0.2),
keras.layers.Conv2D(64, (3, 3), strides=(2, 2), padding='same'),
keras.layers.LeakyReLU(0.2),
keras.layers.Flatten(),
keras.layers.Dense(1, activation='sigmoid')
])
Este es el código final que funciona, ya que he tenido que retocar un poco el Generador, pero realmente ha creado un modelo bastante de Manual. Funcional, pero sin florituras.
El Generador usa dos capas de Conv2DTranspose para realizar el upsampling, pero a diferencia de lo que hemos hecho nosotros, incorpora una última capa Conv2D para convertir los datos al formato de la imagen 28 x 28 x 1. Nuestro modelo utiliza la última capa de Conv2DTranspose para realizar el upsampling y la conversión en el mismo paso.
La otra gran diferencia es la ausencia de las capas de BatchNormalization. Pero en realidad los dos Generadores se parecen mucho.
En cuanto al Discriminador, la mayor diferencia es que está usando una capa LeakyRelu después de la capa Conv2D en lugar de usarlo como un activador de la misma capa. De esta forma la activación negativa se produce después de la Convolución. La mayor ventaja de este método es que puedes poner otras capas antes de la activación, pero no lo está utilizando en este caso. Los datos tampoco son especialmente complejos, yo no le acabo de encontrar una ventaja clara el separar la capa LeakyRelu de la activación.
Si comparamos los resultados de las dos redes, creo que el claro ganador es nuestro modelo.
Resultados de la GAN de ChatGPT después de 30 épocas:
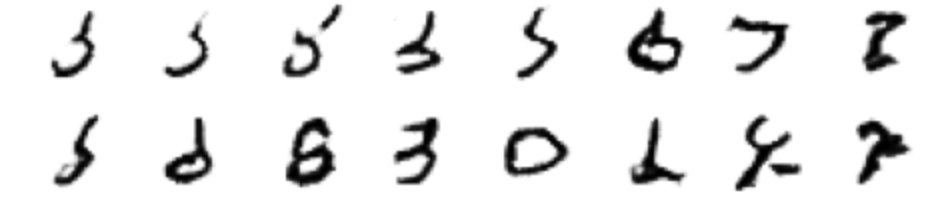
Resultados de nuestra GRAN después de 30 épocas:
En todo caso, ChatGPT ha demostrado ser una herramienta muy útil que nos puede ayudar en nuestro día a día. Os animo a que lo uséis y le preguntéis a él por las diferencias entre nuestros modelos. Estoy convencido de que os sorprenderá la forma en la que justifica las decisiones.
¿Qué hemos aprendido?
Hemos visto una GAN muy sencilla y hemos seguido algunas de las recomendaciones más famosas.
Ya sabemos cómo se usan un generador y un discriminador para generar contenido mientras se entrenan mutuamente.
También hemos visto como hacer upsampling de la entrada del generador hasta llegar al formato de la imagen que queremos generar, utilizando capas Conv2DTranspose.
Me gustaría remarcar especialmente las GAN Hacks que hemos usado:
- Al cargar las imágenes hemos normalizado sus valores entre -1 y 1.
- Hemos empleado el activador tanh como activador de la última capa del generador.
- Se ha usado LeakyRelu como capa de activación tanto las capas Conv2D del discriminador como en las Conv2DTranspose del Generador.
- Hemos usado el optimizador Adam.
¿Qué es lo siguiente?
Mi principal recomendación es que cojáis el notebook y lo modifiquéis. Jugad con él. Probad con otro Dataset, un buen sustituto podría ser el FashionMNIST, también formado por imágenes de 28 x 28 x 1. Intentad implementar algunas de las recomendaciones que aún no hemos visto, podéis encontrarlas en este enlace: https://github.com/soumith/ganhacks. Si yo tuviera que escoger, posiblemente implementaría la de suavizar las etiquetas. Creo que es muy sencilla de implementar y al mismo tiempo nos dará juego.
En los próximos artículos emplearemos Datasets más complejos. Lo primero será introducir color, lo que va a provocar que nuestra GAN sea mucho más pesada de entrenar. Por lo que incorporaremos aún más recomendaciones de las GAN Hacks, y posiblemente utilicemos TPU’s en lugar de GPU’s.
Falta ver cómo se evalúa una GAN. Pero posiblemente le dedique un artículo aparte.
Siguiente artículo en el tutorial de GANs:

Veremos lo impresionantemente sencillo que puede ser obtener mejoras de rendimiento significativas usando la generación automática de código en Graph Read more

Realizar un entreno desde 0 de uno de los Grandes Modelos de Lenguaje actuales es una acción al alcance de Read more

Antes de explicar que es o que deja de ser un agente, permitidme que de mi opinión personal sobre ellos: Read more
Una GAN, como ya sabemos, nos permite generar imágenes similares a las del Dataset con el que ha sido entrenada. Read more