
Veremos lo impresionantemente sencillo que puede ser obtener mejoras de rendimiento significativas usando la generación automática de código en Graph Mode de TensorFlow.
Originalmente, TensorFlow tan solo permitía crear código en Graph Mode, pero desde que se introdujo la posibilidad de hacerlo en Eager Mode, la mayoría de los notebooks producidos son en Eager Mode. Tanto es así que cuesta encontrar código escrito en Graph Mode, y la mayoría de los programadores de TensorFlow que están empezando, o que ya llevan un tiempo creando modelos, no han programado nunca en Graph Mode.
La verdad es que el código en Graph Mode es bastante más complicado de leer y mantener, aunque también es bastante más eficiente. Por suerte, TensorFlow nos ofrece un método de pasar de Eager Mode a Graph Mode de una forma realmente sencilla: ¡el AutoGraph!
Pero, para que nos hagamos una idea, lo mejor es que vemos el código de una función muy sencilla en Eager y en Graph Mode.
#Función en eager mode.
def func_eager(x):
if (x >0):
x = x + 1
return x
#función en graph mode.
def func_graph(x):
def if_true():
return x + 1
def if_false():
return x
x=tf.cond(tf.greater(x, 0), if_true, if_false)
Esta función es increíblemente sencilla, lo único que hace es sumarle 1 a la x en caso de que el valor de esta sea mayor a 0. En la función Eager no hay ninguna duda, la lectura es directa para cualquiera que tenga unos conocimientos mínimos de programación. Pero el código se complica en la función Graph, es bastante más complicado de leer y de entender, no digamos ya de escribir. Aun así, es un código mucho mejor para la máquina, mucho más sencillo de ejecutar en paralelo, y que obtiene un rendimiento mucho mejor.
Estas mejoras de rendimiento obtenidas con el código en modo Graph hacen que sea una técnica muy interesante para muchos notebooks y no podemos dejar pasar la oportunidad de sacar provecho de ella.
En la sección siguiente veremos cuantos ejemplos de cómo podemos usar el AutoGraph. Basados en un Notebook, que se puede encontrar en Kaggle. En él se pueden encontrar las funciones en Graph y en Eager Mode y así se puede compara el rendimiento entre los dos métodos.
Notebook en Kaggle con el código: https://www.kaggle.com/code/peremartramanonellas/improve-tensorflow-performance-with-graph-mode.
Probando el AutoGraph:
Vamos a emplear la misma función anterior.
@tf.function
def func(x):
if x > 0:
x = x + 1
return x
La única modificación ha sido decorar la función con @tf.function. No necesitamos nada más, aunque en breve veremos qué no siempre es así y que no todo el código es 100 % directamente traducible a Graph Mode.
Aparte de saber cómo transformar el código, también es muy interesante, ver el código generado. Podemos hacerlo con una sola línea de código.
print (tf.autograph.to_code(func.python_function))
El código mostrado es:
def tf__func(X):
with ag__.FunctionScope('func', 'fscope', ag__.ConversionOptions(recursive=True, user_requested=True, optional_features=(), internal_convert_user_code=True)) as fscope:
do_return = False
retval_ = ag__.UndefinedReturnValue()
def get_state():
return (x,)
def set_state(vars_):
nonlocal x
(x,) = vars_
def if_body():
nonlocal x
x = (ag__.ld(x) + 1)
def else_body():
nonlocal x
pass
x = ag__.Undefined('x')
ag__.if_stmt((ag__.ld(x) > 0), if_body, else_body, get_state, set_state, ('x',), 1)
try:
do_return = True
retval_ = ag__.ld(x)
except:
do_return = False
raise
return fscope.ret(retval_, do_return)
¡Vale! Es muchísimo más complicado que el que he escrito yo de la misma función, aunque si nos fijamos tiene la misma estructura. Todo el código que debe ejecutarse está contenido en unas funciones definidas antes de la línea que contiene la inteligencia. El flujo se controla desde la función if_stmt, que recibe una condición y tiene las funciones a ejecutar en caso de que la función sea verdadera o falsa. En nuestro caso la condición es que x sea mayor que 0. Si se cumple llamará a if_body, y si no se cumple a else_body.
Veamos a ver algunos de los casos en los que tenemos que adaptar el código si queremos pasarlo a Graph Mode.
En el caso de necesitar variables Tensor no podemos declararlas dentro de la función.
#This function will fail as it does not support declaring tf variables in the body.
#if you want to execute and test it, remove the comments. </em>
#@tf.function
#def f(x):
# v = tf.Variable(1.0)
# return v.assign_add(x)
#For it to work, we just have to remove the variable and declare it outside the function
v = tf.Variable(1.0)
@tf.function
def f(x):
return v.assign_add(x)
La solución es tan sencilla como declarar las variables fuera del cuerpo de la función.
Otro caso tener en consideración es como funciona la función print(). En Graph Mode esta función tan solo se va a ejecutar una vez, sin importar que este dentro de un bucle donde se debería ejecutar varias veces. La solución es tan sencilla como sustituirla con la función tf.print()
@tf.function
def print_test():
tf.print("with tf.print")
print("with print")
for i <strong>in</strong> range(5):
print_test()
El resultado de esta función seria:
with print with tf.print with tf.print with tf.print with tf.print with tf.print
Es decir, ejecutar 5 veces el bloque, pero tan solo realizaría una llamada a la función print().
Algo similar ocurre con ASSERT, que se debe sustituir por el correspondiente tf.debugging.assert.
Estos tres casos son tan solo una muestra, aunque son las primeras que solemos encontrarnos al intentar pasar el código de Eager a Graph Mode.
Comparar Eager con Graph Mode usando un par de Datasets.
En el notebook que puede encontrarse en Kaggle, encontraréis todo el código. En este artículo solo mostraré las partes que tengan relación directa con las pruebas y con el código en Graph Mode.
El Notebook está preparado para funcionar con un par de Datasets muy conocidos: Cats vs Dogs y Humans vs Horses. En Kaggle he empleado el dataset de Humans vs Horses debido a las limitaciones de memoria de la plataforma, pero si os bajáis el notebook y lo ejecutáis en una máquina con más memoria podéis probar con el dataset de Cats vs Dogs.
Los dos Datasets forman parte de la base de datos de TensorFlow de Datasets, así es mucho más sencillo ejecutar el notebook en cualquier entorno, sin que tengamos de preocuparnos de recuperar los datos del Dataset.
He utilizado un modelo custom, ya que será más fácil ver las mejoras obtenidas.
Una de las partes que se pueden acelerar es la de tratamiento de los datos. En este caso son imágenes muy sencillas y con poco tratamiento, pero incluso así se aprecia una mejora significativa en porcentaje. En campos como NLP, donde el tratamiento de datos puede ser muy pesado, las mejoras obtenidas serán más importantes. Siempre dependiendo del tamaño del Dataset y del tratamiento que se quiera realizar.
#Treat the image in eager mode.
def map_fn_eager(img, label):
# resize the image
img = tf.image.resize(img, size=[IMAGE_SIZE, IMAGE_SIZE])
# normalize the image
img /= 255.0
return img, label
#Treat the image in graph mode.
@tf.function
def map_fn_graph(img, label):
# resize the image
img = tf.image.resize(img, size=[IMAGE_SIZE, IMAGE_SIZE])
# normalize the image
img /= 255.0
return img, label
# Prepare train dataset by using preprocessing with map_fn_eager or graph, shuffling and batching
def prepare_dataset(train_examples, validation_examples, test_examples, num_examples, map_fn, batch_size):
train_ds = train_examples.map(map_fn).shuffle(buffer_size = num_examples).batch(batch_size)
valid_ds = validation_examples.map(map_fn).batch(batch_size)
test_ds = test_examples.map(map_fn).batch(batch_size)
return train_ds, valid_ds, test_ds
Como se puede ver el código de las dos funciones, map_fn_eager y map_fn_graph, es exactamente el mismo, tan solo varía la decoración con @tf.function. Hay una tercera función prepare_dataset, que será la función a llamar para preparar los juegos de Datasets, y a la que le pasaremos la función a ejecutar. Esta última función nos devolverá tres datasets ya con las imágenes ajustadas en tamaño y normalizadas.
Vamos a ver la llamada:
start_time = time.time()
train_ds_eager, valid_ds_eager, test_ds_eager = prepare_dataset(train_examples,
validation_examples,
test_examples,
num_examples,
map_fn_eager, BATCH_SIZE)
end_time = time.time()
print ("Eager Time spend:", end_time - start_time)
start_time = time.time()
train_ds_graph, valid_ds_graph, test_ds_graph = prepare_dataset(train_examples,
validation_examples,
test_examples,
num_examples,
map_fn_graph, BATCH_SIZE)
end_time = time.time()
print ("GraphTime spend:", end_time - start_time)
Eager Time sped: 0.061063528060913086
Graph Time spend: 0.0561823844909668Como se puede ver es un proceso muy rápido, pero es que el Dataset es pequeño y muy sencillo. Incluso así, hemos necesitado tan solo una línea para obtener una mejora de rendimiento del 15 %. No está mal. La mejora más importante la veremos en la ejecución del modelo.
El notebook usado en Kaggle viene preparado para funcionar con tres modelos. Dos de ellos obtenidos desde él. tfhub de TensorFlow. Un resnet_50 y resnet_v2_152. Pero veremos los resultados de un tercer modelo, mucho más sencillo, y que es un modelo construido con la API sequential de TensorFlow. En el caso de que podáis ejecutarlo en una máquina más potente, no dudéis en probar los otros dos modelos.
#MODULE_HANDLE = 'https://tfhub.dev/tensorflow/resnet_50/feature_vector/1'
#MODULE_HANDLE = 'https://tfhub.dev/google/imagenet/resnet_v2_152/classification/5'
#model = tf.keras.Sequential([
# hub.KerasLayer(MODULE_HANDLE, input_shape=(IMAGE_SIZE, IMAGE_SIZE, 3)),
# tf.keras.layers.Dense(num_classes, activation='softmax')
#])
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(16, (4,4), activation="relu", input_shape=(IMAGE_SIZE, IMAGE_SIZE, 3)),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Conv2D(32, (4,4), activation="relu"),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Conv2D(64, (4,4), activation="relu"),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation="relu"),
tf.keras.layers.Dense(2, activation="softmax")])
model.summary()
Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d (Conv2D) (None, 221, 221, 16) 784 _________________________________________________________________ max_pooling2d (MaxPooling2D) (None, 110, 110, 16) 0 _________________________________________________________________ dropout (Dropout) (None, 110, 110, 16) 0 _________________________________________________________________ conv2d_1 (Conv2D) (None, 107, 107, 32) 8224 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 53, 53, 32) 0 _________________________________________________________________ dropout_1 (Dropout) (None, 53, 53, 32) 0 _________________________________________________________________ conv2d_2 (Conv2D) (None, 50, 50, 64) 32832 _________________________________________________________________ max_pooling2d_2 (MaxPooling2 (None, 25, 25, 64) 0 _________________________________________________________________ dropout_2 (Dropout) (None, 25, 25, 64) 0 _________________________________________________________________ flatten (Flatten) (None, 40000) 0 _________________________________________________________________ dense (Dense) (None, 512) 20480512 _________________________________________________________________ dense_1 (Dense) (None, 2) 1026 ================================================================= Total params: 20,523,378 Trainable params: 20,523,378 Non-trainable params: 0 _________________________________________________________________
Atención, porque el modelo va a ser un modelo custom. Lo que significa que voy a escribir la función que se ejecutará en cada paso, y la que controlará el entreno de las épocas. Esta segunda función será la que se ejecutará en Eager o en Graph Mode.
# Custom training step. This function is executed in each step each epoch.
def train_one_step(model, optimizer, x, y, train_loss, train_accuracy):
with tf.GradientTape() as tape:
<em># Run the model on input x to get predictions</em>
predictions = model(x)
<em># Compute the training loss using `train_loss`, passing in the true y and the predicted y</em>
loss = train_loss(y, predictions)
# Using the tape and loss, compute the gradients on model variables using tape.gradient
grads = tape.gradient(loss, model.trainable_variables)
# Zip the gradients and model variables, and then apply the result on the optimizer
optimizer.apply_gradients(zip(grads, model.trainable_variables))
# Call the train accuracy object on ground truth and predictions
train_accuracy(y, predictions)
return loss
Esta es la función que se va a ejecutar en cada paso. Como podéis ver no tiene ningún secreto. Realiza una predicción, recupera la perdida, y calcula los gradientes que se pasan al optimizador que decide como modifica los pesos.
def train_eager(model, optimizer, epochs, train_ds, train_loss, train_accuracy, valid_ds, val_loss, val_accuracy):
step = 0
loss = 0.0
for epoch <strong>in</strong> range(epochs):
for x, y <strong>in</strong> train_ds:
# training step number increments at each iteration
step += 1
# Run one training step by passing appropriate model parameters
# required by the function and finally get the loss to report the results
loss = train_one_step(model, optimizer, x, y, train_loss, train_accuracy)
# Use tf.print to report your results.</em>
# Print the training step number, loss and accuracy
print('Step', step,
': train loss', loss,
'; train accuracy', train_accuracy.result())
for x, y <strong>in</strong> valid_ds:
# Call the model on the batches of inputs x and get the predictions
y_pred = model(x)
loss = val_loss(y, y_pred)
val_accuracy(y, y_pred)
# Print the validation loss and accuracy
tf.print('val loss', loss, '; val accuracy', val_accuracy.result())
@tf.function
def train_graph(model, optimizer, epochs, train_ds, train_loss, train_accuracy, valid_ds, val_loss, val_accuracy):
step = 0
loss = 0.0
for epoch in range(epochs):
for x, y in train_ds:
# training step number increments at each iteration
step += 1
# Run one training step by passing appropriate model parameters
# required by the function and finally get the loss to report the results
loss = train_one_step(model, optimizer, x, y, train_loss, train_accuracy)
# Use tf.print to report your results.
# Print the training step number, loss and accuracy
tf.print('Step', step,
': train loss', loss,
'; train accuracy', train_accuracy.result())
for x, y in valid_ds:
# Call the model on the batches of inputs x and get the predictions
y_pred = model(x)
loss = val_loss(y, y_pred)
val_accuracy(y, y_pred)
# Print the validation loss and accuracy
tf.print('val loss', loss, '; val accuracy', val_accuracy.result())
Como se puede ver el código de las dos funciones, es casi el mismo. La única modificación necesaria ha sido sustituir las funciones print() por funciones tf.print(). Esta función es la responsable de llamar en cada paso a train_eager y hacerlo durante las épocas indicadas.
Como esta es la función decorada, todas las funciones que se llaman a partir de ella se ejecutan en Graph Mode. Es decir, no tenemos que decorar toda la jerarquía de funciones, tan solo hace falta hacerlo a la primera que llamamos. Pero todas las funciones deben cumplir con los requisitos de una función en Graph Mode, ya estén decoradas o no. Lo importante es el modo en el que se ejecutan.
#Solving the model in eager mode, and printing the time elapsed.
st = time.time()
train_eager(model, optimizer, 6, train_ds_eager,
train_loss, train_accuracy, valid_ds_eager,
val_loss, val_accuracy)
et = time.time()
print('Eager mode spent time: ' et - st)
...... Step 137 : train loss tf.Tensor(0.00049685716, shape=(), dtype=float32) ; train accuracy tf.Tensor(0.9509188, shape=(), dtype=float32) Step 138 : train loss tf.Tensor(0.0001548939, shape=(), dtype=float32) ; train accuracy tf.Tensor(0.9510895, shape=(), dtype=float32) val loss 4.05896135e-05 ; val accuracy 0.98780489 Eager mode spent time: 21.57599711418152
#Solving the model in graph mode, and printing the time elapsed.
st = time.time()
train_graph(model, optimizer, 6, train_ds_graph,
train_loss, train_accuracy, valid_ds_graph,
val_loss, val_accuracy)
et = time.time()
print('Graph mode spent time: ' et - st)
............. Step 137 : train loss 0.000154053108 ; train accuracy 0.975502133 Step 138 : train loss 3.81469249e-07 ; train accuracy 0.975544751 val loss 2.89767604e-06 ; val accuracy 0.993902445 11.941826820373535
Como se puede ver, la mejora de rendimiento en la ejecución del modelo es más que considerable. Cercana al 50%. Pasamos de 21 a 12 segundos. Como ya sabéis, estos son números un poco falsos. Estamos jugando con Datasets de juguete, muy sencillos. Imaginaos la capacidad de ahorro que puede tener en un Dataset grande. Aparte que la mejora no se consigue tan solo en tiempo de entreno, también puede usarse en tiempo de inferencia.
Conclusiones.
Sinceramente, creo que es imprescindible hacer nuestros modelos compatibles con el Modo Graph. No hace falta que sean nativos, pero si compatibles con AutoGraph.
Vemos que no tan solo encontramos una mejora en el rendimiento, sino que también hay una diferencia en el valor del accuracy obtenido. Soy incapaz de explicar el porqué. Pero es algo que tenemos que controlar, si las métricas obtenidas no son las mismas se debe tener en cuenta volver a evaluar el modelo cada vez que pasemos alguna función de Eager a Graph Mode o viceversa.
Espero que os haya gustado, sinceramente en la muchos casos la transformación va a ser casi directa y la mejora obtenida muy significativa.

Tal como indica el título, vamos a construir con TensorFlow una red siamesa que aceptará dos entradas y nos dirá Read more

En el artículo anterior, aprendimos a montar un prompt que era capaz de generar órdenes SQL desde peticiones realizadas en Read more
¿Te falla la instalación de Conda en MacOs Catalina? A mi tambíen me ha pasado... y lo he solucionado modificando Read more
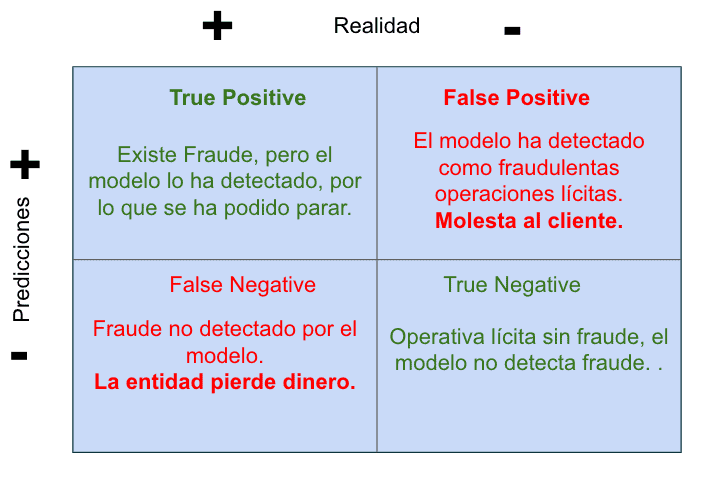
Depende de lo que estemos intentando hacer con nuestro modelo de Machine Learning, vamos a tener que fijarnos en unos Read more