Depende de lo que estemos intentando hacer con nuestro modelo de Machine Learning, vamos a tener que fijarnos en unos u otros KPI’s para saber si vamos bien o no. O bueno, si alguien nos presenta un producto basado en Machine Learning dependiendo de la necesidad que queramos cubrir nos tendremos que mirar unos KPI’s o no.
antes de empezar un poco leyenda:
TP: True Positive. Los positivos predecidos que acaban siendo realmente positivos.
FP: False Positive. Positivos que predice el sistema, que no acaban siendo positivos.
TN: True Negative. Negativos que el modelo acierta.
FN: False Negative. El modelo prevé un negativo y acaba siendo un positivo.
Ya vemos que no es nada complicado. Los típicos positivos y negativos. Los errores se cuentan, como falsos positivos o falsos negativos.
Vamos a quedarnos con tan solo 3 KPIs:
Accuracy / Exactitud: (TP + TN) / Total. Nos indica el porcentaje de aciertos del modelo. Está claro que es un KPI importante, pero que puede inducir a errores, y no tiene por que ser el mas importante, dependiendo de lo que estemos estudiando. Si un modelo tuviera un 100% de Exactitud (cosa que no pasa nunca) los otros KPI’s carecerian de importancia. Pero podemos encontrar modelos con un % superior al 90% que sean auténticos desastres para nuestro negocio.
Precision / Precisión: TP / (TP + FP). Nos indica qué porcentaje de los positivos predichos son correctos. Es diferente al KPI de Exactitud, por que no tiene en cuenta los errores o los aciertos en los negativos.
Recall / exhaustividad: TP / (TP + FN). Nos indica la tasa de acierto en los positivos. Este KPI es muy importante dependiendo de lo que estemos estudiando. Para casos de fraude, que és mi campo, es de los principales. Ya que aquí nos indica la posibilidad de que nos cuelen un fraude sin detectarlo. Pero hay un caso donde aún es más importante: diagnóstico de enfermedades. Estamos hablando de personas que el modelo les ha indicado que estan sanas, cuando en realidad tienen esa enfermedad. Como más alto sea mejor, si nos encontramos con una exhaustividad baja el modelo estará dejando pasar muchos positivos como falsos.
Veamos un pequeño ejemplo y así ponemos en practica los números.
KPI’s a estudiar para modelos que previenen ataques a una entidad financiera.
En este caso los positivos identifican fraude, mientras que los negativos son operaciones no fraudulentas de los clientes.
Antes de ver los números veamos una especie de Matriz de confusión donde se describe, muy brevemente qué significa para el negocio la detección o no de los casos positivos y falsos.
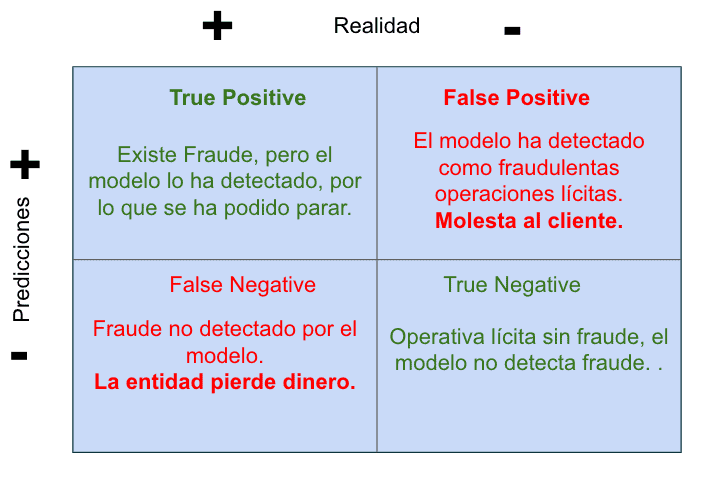
En rojo los dos errores que se pueden dar, y su significado al negocio. Recomiendo que en toda reunión en la que se hable de cómo mejorar el modelo, o se deba decidir entre un producto u otro se tenga muy claro esta Matriz de confusión, y sobre qué KPI’s se debe actuar modificar para reducir los impactos negativos
Veamos los números de nuestro ejemplo:
True Positive: 20. El sistema ha identificado 20 ataques como positivos que se han podido parar y realmente eran ataques positivos.
False Positive: 20. El sistema identifica como ataques operativas de los clientes. Hay afectación en el servicio por que posiblemente se corte la operación y el cliente se vea afectado.
True Negative: 1800. Operaciones identificadas como no fraudulentas de forma correcta. Todo funciona como tiene que funcionar.
False Negative: 100. Operaciones no identificadas como fraude, pero que han acabado siendo fraude. En cada una de estas operaciones nos roban algo de dinero.
Con estos números veamos como quedan los KPI’s.
Exactitud: (20 + 1800) / 1940 = 94%. Como podéis ver el modelo tiene una exactitud que sin ser impresionante, se podría definir como muy buena. Cuando realmente es un desastre de modelo para nosotros.
Precisión: 20 / (20 + 20) = 50%. De todos los positivos detectados, es decir todos los casos de fraude. Tan solo un 50% de ellos eran realmente casos de fraude. Este KPI es muy importante si lo que estás buscando es reducir el impacto a los clientes.
Exhaustividad: 20 / (20 / 300) = 17%. Recordemos que aquí hemos dicho que cuanto más bajo el número pero para nosotros. Nos está indicando que se nos han colado 100-17 % de fraude. Es decir de cada 100 intentos de fraude que tenemos, nos tragamos 83!!!!!!
Como podéis ver la exactitud es un tanto engañosa, y en nuestro caso, un modelo que tiene que parar casos de fraude, no podemos basar nuestra decisión en este KPI. Tenemos que mirar la Exhaustividad, que es el KPI que nos está indicando cuántos casos de fraude acaban pasando.
Pero los números aún podrían ser más engañosos imaginemos que se reducen los falsos positivos a un solo caso. Quedando los números así:
TP: 20 FP: 1 FN: 100 TN: 1800
En este caso el modelo tendría una Exactitud del 95% un pequeño incremento de un punto. Una Precisión del 95% que es un aumento impresionante, y que nos podría hacer creer que estamos ante un modelo realmente bueno para nuestro caso. Pero no es así, la Exhaustividad no varia, estamos ante el mismo 17%., con lo que se nos continúan colando el 83% de los intentos de fraude.
Resumen.
Como se puede ver, tenemos que conocer nuestro negocio y el significado de cada KPI para decidir qué se debe mejorar del sistema de machine learning, o decidir entre dos modelos. En el caso de los intentos de fraude está claro que el foco se tenía que poner en la exhaustividad ya que nos permite identificar el número de fraudes que se cuelan en el sistema. Pero tampoco podríamos dar por bueno un sistema con una exhaustividad muy pequeña que se dedicase a catalogar como fraude casi todas las operaciones, parando las operativas de los clientes.
El ejemplo se podría haber hecho con el diagnosis de enfermedades como el cáncer, donde la exhaustividad tambíen es muy importante, sino mas, ya que este caso identifica a pacientes que se han marchado con un diagnóstico erróneo indicando que están sanos, cuando tiene una enfermedad que debe ser tratada lo antes posible.
Mas info:
https://medium.com/swlh/how-to-measure-ai-product-performance-the-right-way-2d6791c5f5c3
https://ai4.io/blog/the-10-measures-and-kpis-of-ml-success

Antes de explicar que es o que deja de ser un agente, permitidme que de mi opinión personal sobre ellos: Read more

Usando los ML Agents de Unity he empezado a crear lo que se llaman NPC's. Son aquellos caracteres que pueblan Read more
Una GAN, como ya sabemos, nos permite generar imágenes similares a las del Dataset con el que ha sido entrenada. Read more

Tal como indica el título, vamos a construir con TensorFlow una red siamesa que aceptará dos entradas y nos dirá Read more