
Vamos a crear dos proyectos de Machine Learning usando la herramienta Google Teachable Machines. Es una herramienta impresionantemente sencilla de usar, y que nos permite crear modelos sencillos, que podemos usar en proyectos con TensorFlow, o simplemente jugar un poco con ellos.
Como todos sabemos los tres pilares fundamentales, sobre los que se basa cualquier proyecto de Machine Learning son:
- Datos.
- Algoritmos.
- Capacidad de proceso.
En este caso para obtener los datos voy a utilizar el repositorio de Datasets de Kaggle, es un sitio ideal para conseguir datos siempre que queramos practicar con cualquier proyecto de IA. Está claro que Kaggle es mucho más que un repositorio de Datasets, pero nadie nos impide usarlo tan solo con este fin.
Nuestro primer proyecto va a ser un modelo capaz de diferenciar entre las figuras del famosísimo juego: Piedra, Papel, tijera. Para ello vamos a usar los datos de un dataset de Kaggle, tan solo tenemos que bajarnos los datos, y obtendremos un zip que al descomprimirlo se nos crearan tres directorios, con las imágenes necesarias.
En el vídeo explico que separó algunas de estas imágenes en un directorio aparte, para usarlas para comprobar el modelo, y así poderlo probar con imágenes que no han sido usadas para entrenarlo. Aunque es una práctica muy recomendable, para este caso es innecesario, ya que es un modelo muy sencillo que con pocas imágenes puede entrenarse. Pero para proyectos más complejos es totalmente necesario disponer de unos datos correctamente clasificados, con los que poder probar el modelo, y que el modelo no los conozca previamente.
Con este paso ya tenemos cubierta la primera necesidad de cualquier proyecto de Machine Learning: los datos. Para cubrir los otros dos, Algoritmos y capacidad de proceso, usaremos Google Teachable Machine.
Google Teachable Machine.
Al entrar en Google Teachable Machine nos encontramos con que podemos escoger tres tipos de proyectos diferentes, seguramente sumarán más en un futuro, por lo que si tú ves alguno más, pues mejor 🙂 .
Para este primer proyecto se escoge el de tipo imagen.
Es tan sencillo como crear tres clases y alimentar cada una de las clases con las imágenes de su tipo. Cuando ya tenemos las imágenes tan solo hay que pulsar el botón Preparar Modelo.
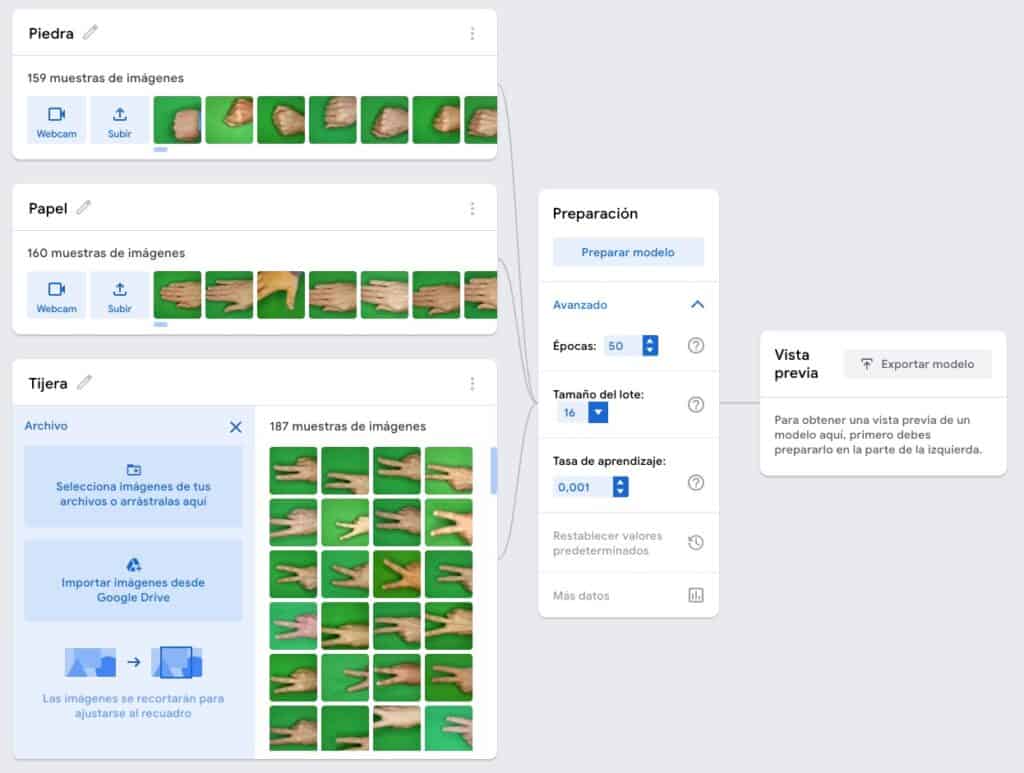
Como se puede ver en la imagen no hace falta demasiada explicación, la gente de Google ha conseguido una interfaz espectacularmente sencilla que nos aísla de la complejidad inherente a los proyectos de Machine Learning.
Nos permite modificar tan solo tres de los muchos hyperparameters que se usan para configurar un proyecto de este tipo:
- Épocas (Epoch). Cada vez que el modelo estudia todas las imágenes pasa una época. Hay que minimizar el número de épocas, ya que consumen recursos. En Teachable Machine no es importante, porque no pagamos por consumir, si se trata de nuestros recursos o cualquier otra herramienta que cobre por uso, cuanto más consumamos más pagaremos. En todo caso, en la mayoría de las otras herramientas las Épocas no son una variable de entrada, es decir, no puedes informarlas, tan solo son una variable informativa, ya que lo fundamental es llegar a un buen nivel de aprendizaje y no las épocas transcurridas.
- Tamaño del lote (batch_size). El modelo coge las imágenes en grupo para estudiarla, aquí le indicamos el tamaño del grupo de imágenes a coger. No suele afectar demasiado al funcionamiento del modelo.
- Tasa de aprendizaje (learning_rate). Esta variable puede ser muy influyente en la capacidad de aprendizaje de un modelo. Le indica al sistema cuanto puede variar cada vez que modifica la aproximación a lo que cree correcto. Un valor muy bajo, hará que el modelo aprenda linealmente, pero puede ser muy lento si no consigue encontrar al principio la senda correcta, tan lento que puede ser inviable esperar a que finalice el aprendizaje. Mientras que un valor muy alto, puede hacer que el modelo aprenda mucho más rápido, pero también da como resultado un aprendizaje con idas y venidas, es decir, que puede estar aprendiendo y de golpe decidir probar con un valor totalmente diferente y perder parte de lo aprendido.
Como veis todo es muy sencillo, la única complejidad es ajustar la tasa de aprendizaje, pero para estos proyectos con el valor por defecto, o algo inferior a 0,03 se suelen conseguir buenos resultados.
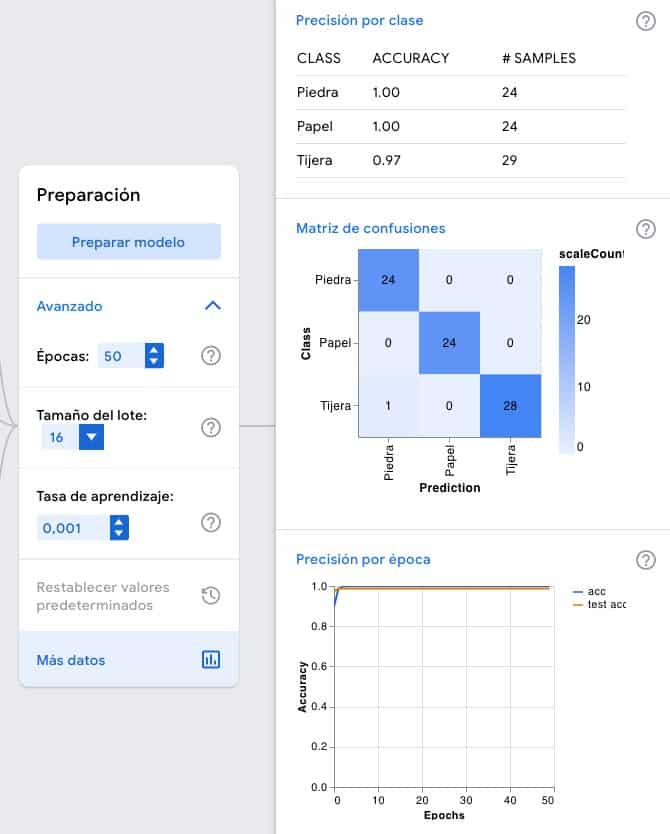
Cuando el modelo ya está entrenado podemos pulsar sobre el botón Más Datos. Así obtenemos información de cómo ha ido él entro de modelo y la calidad de este.
Primero nos encontramos con la Precisión por clase. Como podéis ver, dos de ellas tiene una precisión de 1, lo que significa que el modelo, durante el entreno, no ha fallado en ninguna de las comprobaciones. Una parte del entreno del modelo es realizar comprobaciones, y lo hace con un % de las imágenes que le hemos facilitado, usándolas para ir probando el modelo.
En cambio, en Tijera vemos que la precisión de un 0.97, lo que significa que en alguna comprobación se ha producido un error. Podemos consultar el error en la Matriz de confusiones. Como podemos ver, el modelo ha predicho una piedra cuando realmente era una tijera. En el eje de las X encontramos las predicciones, y en el de las Y la clase a la que pertenece.
El último gráfico que encontramos es el de precisión por época. Como se puede ver nos han sobrado la mayoría de las épocas. Yo diría que con unas cinco ya sería suficiente, en lugar de las 50 que hemos usado.
Más cosas en el vídeo.
En el vídeo, que por si no lo has visto está al principio del artículo, se crea un segundo proyecto, también con Google Teachable, pero en él se usa la Webcam como método de entrada en lugar de imágenes obtenidas. Por lo demás, como os podéis imaginar, el proceso es casi el mismo. Google Teachable es fácil de usar, pero tampoco nos da mucha flexibilidad.
Para explicar cómo funciona el learning_rate, o tasa de aprendizaje, y cómo afecta al aprendizaje en el vídeo he usado la herramienta playground de tensorflow. Esta herramienta te permite construir modelos de una forma gráfica muy sencilla y modificar algunos hyperparameters para que se pueda ver cómo afectan al aprendizaje. Es una herramienta muy útil, muy sencilla de utilizar y muy gráfica. En otro vídeo o en otro artículo explicaré más de sus utilidades y características.
Links :
Recuperamos el Dataset para el primer proyecto de Kaggle: https://www.kaggle.com/drgfreeman/rockpaperscissors
Google Teachable Machine: https://teachablemachine.withgoogle.com/
Playground Tensorflow: https://playground.tensorflow.org/
Hola,
Solo me queda la duda de en qué momento le damos la retroalimentación de que ha fallado en una imagen, para que sepa que se ha equivocado, esto lo pregunto porque yo hice un ejercicio con 133 imágenes de radiografías con pacientes con COVID 19, 133 con neumonía viral, 133 con neumonía bacterial y 133 con pacientes sanos, mas 10 imágenes de prueba por cada uno de esos rubros y su tasa de precisión rondaba por el 0.7, en muchas imágenes fallaba o calculaba un cierto % para 2 o 3 clases del ejercicio, entonces me interesa saber cómo puede mejorar la identificación de las imágenes hasta llegar a una precisión de 1.
Hola Mario,
No se si te voy a ayudar demasiado. Teachable Machines es una herramienta muy sencilla. Tan solo podemos modificar las épocas de entreno, el tamaño del lote y la tasa de aprendizaje.
Por lo que entiendo entrenaste el modelo dandole 399 imágenes, 133 de cada tipo y despúes realizaste la prueba con 33. No se la calidad de las imágenes. Pero creo que el problema principal debe ser el modelo construido por Teachable Machines. No creo que sea un modelo muy grande-
Te recomiendo que le des un vistazo a un notebook en Kaggle:
https://www.kaggle.com/code/alifrahman/covid-19-detection-using-transfer-learning, utiliza un modelo grande de reconocimiento de imágenes y entrena tan solo unas capas.
Creo que esta aproximación puede ser la mejor.
Espero que te ayude!
Excelente, muchas gracias Martra, haré esa prueba,
Saludos cordiales,