
En este artículo veremos una breve introducción al funcionamiento del API de OpenAI, usaremos uno de sus famosos modelos, en los que se basa la famosísima herramienta ChatGPT, para crear nuestro propio ChatBot. .
Para hacer esta pequeña introducción al mundo de los LLM, vamos a ver como crear un chat simple, usando la API de OpenAI y su modelo gpt-3.5-turbo.
Es decir, vamos a construir un pequeño ChatGPT, entrenado para que sea un chatbot de un restaurante de comida rápida.
Breve introducción al API de OpenAI.
Antes de empezar a crear el chatbot creo que es interesante explicar brevemente un par ce conceptos:
- Los roles que existen en una conversación con OpenAI.
- Como se mantiene la memoria de la conversación.
Pero si prefieres ir directamente a la creación del chatbot, puedes ir directamente a la sección: Empezamos a crear el chatbot con OpenAI y GPT.
Los roles en los mensajes de OpenAI.
Una de las características menos conocidas de los modelos de lenguaje como GPT 3.5 es que la conversación se produce entre varios roles diferentes. Podemos identificar el Usuario y el Asistente, pero hay un tercer rol, llamado system, que nos permite configurar mejor como debe actuar el modelo.
Al usar herramientas como las de ChatGPT siempre estamos asumiendo el rol del usuario, pero el API nos da la posibilidad de indicar que Rol queremos que sea tomado como propietario de la frase que le enviamos al modelo.
Para enviar texto, conteniendo nuestra parte del dialogo al Modelo usamos la función ChatCompletion.create, a la que, se le indica, como mínimo, el modelo a usar y una lista de mensajes. Cada uno de los mensajes de la lista está compuesto por un rol, y el texto que queremos que reciba el modelo.
Veamos un ejemplo de la lista de mensajes que podemos enviar, usando los tres roles disponibles:
messages=[
{"role": "system", "content": "You are a OrderBot in a fastfood restaurant."},
{"role": "user", "content": "I have only 10 dollars, what can I order?"},
{"role": "assistant", "content": "We have the fast menu for 7 dollars."},
{"role": "user", "content": "Perfect! Give me one! "}
]
Veamos un poco mas para que sirven los tres roles existente:
- System: Podemos indicarle al modelo como queremos que se comporte y darle instrucciones de cómo debe ser su personalidad y el tipo de respuesta. De alguna manera nos permite configurar el funcionamiento básico del modelo. Según OpenAI aunque en GPT3.5 se le hace caso, se va aumentar la importancia de este rol en modelos posteriores.
- User: Son las frases que vienen del usuario. Aunque en la API podemos actuar como si fueramos el asistente, lo más usual es informar lo que nos está pidiendo el cliente. Aunque siempre podemos modificarlo.
- Assistant: Son las respuestas que nos devuelve el modelo. Aunque con la API podemos introducir respuestas indicando que son del modelo, aunque provengan de otra parte.
La memoria en las conversaciones con OpenAI.
Si estamos acostumbrados a usar ChatGPT podemos ver cómo se mantiene una «memoria» de la conversación, es decir, ChatGPT recuerda el contexto. Tanto lo que le hemos dicho antes como sus respuestas. Pues bien, esto es así porque la memoria la está manteniendo la interfaz, no el modelo. En nuestro caso pasaremos la lista de todos los mensajes, junto al contexto, generados en cada llamada a ChatCompletion.create.
El contexto no es nada más que el primer mensaje que vamos a crear para pasárselo al modelo antes de que pueda hablar con el usuario. En él indicaremos como debe comportarse y el tono de la respuesta. También le pasaremos los datos que necesita para realizar correctamente la tarea que le hemos asignado.
Vemos un pequeño contexto, y como mantener una conversación con OpenAI.
import openai
#creamos el contexto
context =[
{'role':'system', 'content':"""Actua como el camarero de un restaurante de comida rapida \
pregunta al cliente que desea y ofrecele las cosas del menu. \
En el menu hay: \
Bocadillo fuet 6
Bocadillo jamon 7
Agua 2
"""}]
#Le pasamos el contexto a OpenAI y recogemos su respuesta.
mensajes = context
respuesta = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=mensajes)
#enseñamos la respuesta al usuario y pedimos una entrada nueva.
print(respuesta.choices[0].message["content"])
#añadimos la respuesta al pool de mensajes
mensajes.append(respuesta)
#añadimos una segunda linea del usuario.
mensajes.append({'role':'user', 'content':'un agua por favor'})
#Volvemos a llamar al modelo con las dos lineas añadidas.
respuesta = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=mensajes)
Como podéis ver es muy sencillo, se trata de ir añadiendo las líneas de conversación al contexto y pasárselo al modelo cada vez que lo llamemos. ¡Realmente el modelo no tiene memoria! La memoria la tenemos que implementar nosotros en nuestro código.
Como podéis imaginar el código que se puede ver arriba está hecho tan solo a modo de ejemplo, vamos a tener que organizarlo mejor, para no tener que ir creando código a medida que el usuario va introduciendo nuevas frases.
Con esta breve explicación creo que ya estamos listos empezar a crear nuestro chatbot de pedidos de comida rápida.
Empezamos a crear el ChatBot con OpenAI y GPT.
Lo primero que tenemos que tener en cuenta es que vamos a necesitar una cuenta de pago en OpenAI para usar su servicio y que tendremos que informar de una tarjeta válida. Pero no nos preocupemos, yo lo he estado usando bastante para realizar desarrollos y pruebas y os puedo asegurar que el coste es ínfimo.
Hacer todas las pruebas para este artículo creo que me han costado 0.07€. Tan solo podríamos encontrarnos una sorpresa si subimos alguna cosa a producción que se convierte en un HIT. Incluso así podemos establecer el límite mensual consumo que queramos.
Lo primero como siempre es saber si tenemos las librerías necesarias instaladas, si estamos trabajando en nuestra máquina. En caso de que trabajemos en Google Colab, creo, que tan solo tenemos que instalar dos, OpenAI y panel.
!pip install openai !pip install panel
Panel, es una librería muy sencilla que nos permite mostrar campos en el notebook e interactuar con el usuario. Si quisiéramos hacer una aplicación WEB podríamos utilizar streamlit en lugar de panel, el código para usar el OpenAI y crear el chatbot seria el mismo.
Ahora toca importar las librerías necesarias e informar del valor de la key que acabamos de obtener de OpenAI.
¿No tienes la key? Puedes obtenerla en esta url: https://platform.openai.com/account/api-keys
import openai import panel as pn #obtener la key from mykeys import openai_api_key openai.api_key=openai_api_key
Como podéis ver la key la obtengo de un fichero en el que guardo las claves. Vosotros la podéis informar directamente en el notebook, o guardarla en el fichero que queráis, siempre con extensión .py, y cargarla. En todo caso aseguraros de que nunca nadie puede conocer el valor de la Key, si no podrían hacer llamadas a la API de OpenAI que acabaríais pagando.
Ahora vamos a definir dos funciones, que será las que van a contener la lógica de mantener la memoria de la conversación.
def continue_conversation(messages, temperature=0):
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=messages,
temperature=temperature,
)
#print(str(response.choices[0].message["content"]))
return response.choices[0].message["content"]
Esta es muy sencilla, tan solo hace una llamada a la API de opeanai que permite mantener una conversación, ya la hemos visto en la primera parte del artículo. Le pasamos el modelo que queremos usar, los mensajes que forman parte de la conversación, y nos devuelve la respuesta del modelo.
Pero hay un tercer parámetro que no hemos visto anteriormente: temperature. Se trata de un valor numérico que puede contener un valor entre 0 y 1, y que indica, cuanto de imaginativo puede ser el modelo al generar la respuesta. Como menos sea el valor, menos original será el modelo. Creo que para el ejemplo he usado el valor de 0, pero jugad con él, y veréis cómo se modifican las respuestas. Como sabéis un modelo de generación de lenguaje, no siempre da las mismas respuestas a las mismas entradas, pero como menor sea el valor de temperature más parecido será el resultado, llegando a repetirse en muchos de los casos.
Creo que vale la pena hacer un paréntesis para explicar grosso modo cómo funciona este parámetro en un modelo de generación de lenguaje. El modelo va construyendo la frase averiguando que palabra es la que debe usar, la escoge de una lista de palabras que tiene asociado un % de posibilidades de aparecer.
Por ejemplo para la frase: Mi coche es… el modelo nos podría devolver la siguiente lista de palabras:
- Rápido – 45%
- Rojo – 32%
- Viejo – 20%
- Extraño – 3%
Con un valor de 0 en temperature siempre nos va a devolver la palabra Rápido, pero a medida que aumentamos el valor de este la posibilidad de que escoja otra de las palabras de la lista se incrementa.
Tenemos que tener cuidado, por qué esto no tan solo aumenta la originalidad, muchas veces aumenta las “alucinaciones” del modelo.
def add_prompts_conversation(_):
#Get the value introduced by the user
prompt = client_prompt.value_input
client_prompt.value = ''
#Append to the context the User prompt.
context.append({'role':'user', 'content':f"{prompt}"})
#Get the response.
response = continue_conversation(context)
#Add the response to the context.
context.append({'role':'assistant', 'content':f"{response}"})
#Undate the panels to shjow the conversation.
panels.append(
pn.Row('User:', pn.pane.Markdown(prompt, width=600)))
panels.append(
pn.Row('Assistant:', pn.pane.Markdown(response, width=600, style={'background-color': '#F6F6F6'})))
return pn.Column(*panels)
Esta función se encarga de recoger la entrada del usuario, incoporarla al contexto, o la conversación, y llamar al modelo e incorporar la respuesta de este a la conversación. Es decir, tal como hemos visto que es necesario en la primera parte del artículo, esta función se encarga de ¡gestionar la memoria! Cosa tan sencilla como ir añadiendo a una lista las frases con el formato correcto, que recordemos que debe contener el rol y la frase.
¡Ahora ya toca el prompt!!!!!! Esto es un modelo LLM. No vamos a programar, vamos a intentar que se comporte como queremos porque le vamos a dar unas instrucciones. Al mismo tiempo, también debemos darle la información suficiente como para que haga su trabajo correctamente informado.
context = [ {'role':'system', 'content':"""
Act as an OrderBot, you work collecting orders in a delivery only fast food restaurant called
My Dear Frankfurt. \
First welcome the customer, in a very friedly way, then collects the order. \
You wait to collect the entire order, beverages included \
then summarize it and check for a final \
time if everithing is ok or the customer wants to add anything else. \
Finally you collect the payment.\
Make sure to clarify all options, extras and sizes to uniquely \
identify the item from the menu.\
You respond in a short, very friendly style. \
The menu includes \
burguer 12.95, 10.00, 7.00 \
frankfurt 10.95, 9.25, 6.50 \
sandwich 11.95, 9.75, 6.75 \
fries 4.50, 3.50 \
salad 7.25 \
Toppings: \
extra cheese 2.00, \
mushrooms 1.50 \
martra sausage 3.00 \
canadian bacon 3.50 \
romesco sauce 1.50 \
peppers 1.00 \
Drinks: \
coke 3.00, 2.00, 1.00 \
sprite 3.00, 2.00, 1.00 \
vichy catalan 5.00 \
"""} ]
El prompt, o el contexto, está dividido en dos partes. En la primera le indicamos como debe comportarse y cuál es su objetivo. Le digo que debe actuar como un bot de un restaurante de comida rápida, y que su objetivo es tener claro que quiere comer el cliente.
En la segunda parte le paso la composición del menú del restaurante. Con una lista de precios, pero sin decirle nada. Ya veréis en las conversaciones que él solo averigua que cada preció corresponde a un tamaño diferente del plato.
¡Por último, usamos panel para crear el prompt de entrada de usuario y ponemos el modelo a trabajar!
#Creamos el panel.
pn.extension()
panels = []
client_prompt = pn.widgets.TextInput(value="Hi", placeholder='Enter text here…')
button_conversation = pn.widgets.Button(name="talk")
interactive_conversation = pn.bind(add_prompts_conversation, button_conversation)
dashboard = pn.Column(
client_prompt,
pn.Row(button_conversation),
pn.panel(interactive_conversation, loading_indicator=True, height=300),
)
dashboard
Con esto ya lo tenemos todo. Os dejo él resulta de una de las conversaciones mantenidas.
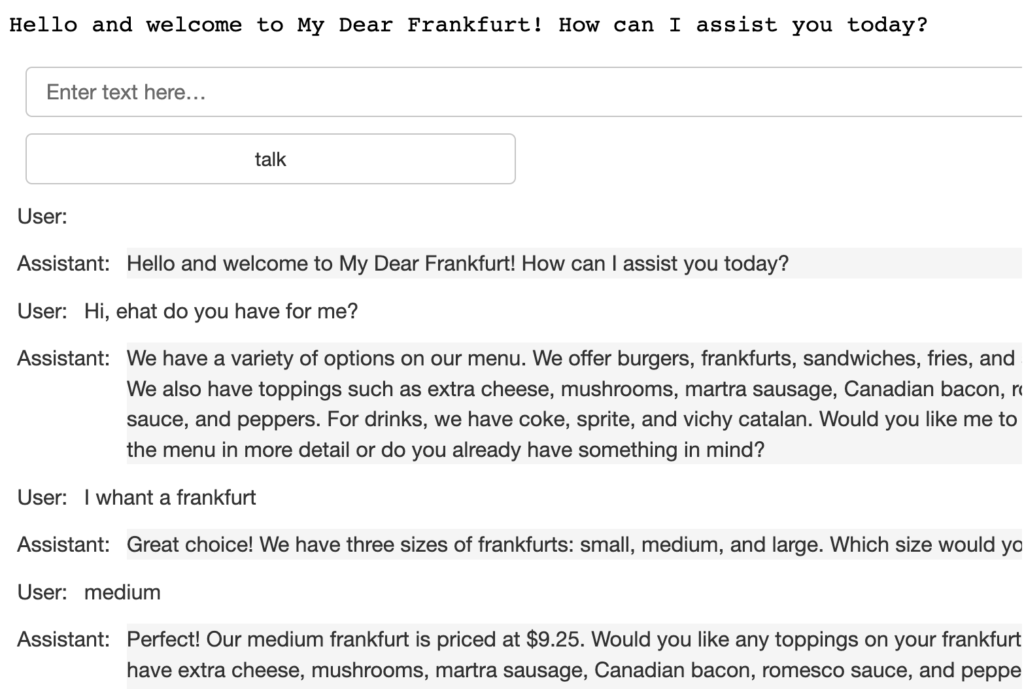
Como curiosidad, pero no falta de importancia, me gustaría remarcar, que aunque el contexto está escrito en Inglés, y la primera frase que nos dice el modelo es en Inglés, si usamos castellano cambiará el idioma con el que mantiene la conversación, traduciendo, incluso, los platos de la carta.
Es decir, en unas pocas líneas tenemos un ChatBot, que podría servir para un pequeño negocio y encima es multiidioma.
Podéis encontrar el notebook completo en github:
https://github.com/peremartra/small_isolated_notebooks/blob/main/Vertical%20Chat.ipynb
¿Cómo continuar?
Hay mil posibilidades de ampliación, se puede adaptar a multitud de negocios, pero quizás una de las más importantes, sea decirle al modelo que al finalizar la conversación, nos cree un JSON o XML con los datos del pedido, y así podríamos enviarlo al sistema de pedidos.
Espero que os haya gustado, y que veáis que las posibilidades son casi infinitas. Un buen sitio donde continuar, quizás el mejor, sea el curso de prompt engineering de Deeplearning.ai.
He tenido la suerte de ver como el curso se creaba desde el principio, y os puedo asegurar que la calidad del contenido es excelente y que se le ha puesto mucho cariño.
Referencias:
El ChatBot ha sido creado influenciado en un 95% por el curso Prompt Engineering for Developers de DeepLearning.ai. Debido a que soy mentor en la especialización de TensorFlow Advanced Techniques he tenido la posibilidad de ver como se creaba el cursos desde el inicio, y os puedo asegurar que si lo seguís serán unas horas muy bien invertidas.