
Recientemente he finalizado la especialización de Deeplearning.ai: TensorFlow Developer Professional Certificate. Lo primero es decir que recomiendo a cualquier persona interesada en Machine Learning, sobretodo Deep Learning, la especialización. No tengo suficientes buenas palabras para describirla.
La verdadera intención es pasar el examen de Google Tensorflow Developer Certificate.
El examen dura unas cinco horas y cuesta 100 Euros. Lo primero me da bastante pereza, no recuerdo el último examen de 5 horas que tuve que realizar. Lo segundo, lo de los 100 euros, como buen Catalan, me duele en el alma. Así que aunque tenga claro que es una inversión, un gasto que tengo simplemente por que me apetece, es un revulsivo inmenso para intentar aprobar a la primera. Así que me lo voy a preparar bastante mejor de lo que recuerdo me preparaba mis anteriores exámenes.
Veamos el contenido del examen en el apartado de Image Classification.
You need to understand how to build image recognition and object detection models with deep neural
networks and convolutional neural networks using TensorFlow 2.x. You need to know how to:
❏ Define Convolutional neural networks with Conv2D and pooling layers.
❏ Build and train models to process real-world image datasets.
❏ Understand how to use convolutions to improve your neural network.
❏ Use real-world images in different shapes and sizes..
❏ Use image augmentation to prevent overfitting.
❏ Use ImageDataGenerator.
❏ Understand how ImageDataGenerator labels images based on the directory structure.
Todas las marcadas en amarillo las cubro con el notebook ConvMNISTTImage.ipynb que me he preparado, y que podéis encontrar en un repositorio de github que he creado expresamente para contener los notebooks que vaya preparando para prepararme para el examen.
Contenido y estructura del fichero ConvMNISTImage.ipynb.
El fichero lo he dividido en diversas secciones para que sea sencillo encontrar la información durante el examen. Aparte de que muchas de las funciones que contienen las podré reutilizar directamente en el notebook que tenga que crear.
Import Libraries and data.
#First step is import the libraries. import tensorflow as tf tf.random.set_seed(42) #Numpy is a lybrary that allow us to work with arrays. import numpy as np #keras is an open source neural networks lybrary writted in python that run's in various frameworks, TensorFlow included. from tensorflow import keras from time import time import matplotlib.pyplot as plt gEpochs = 100 print (tf.__version__)
Se importan las librerías necesarias, y también aprovecho para definir una variable gEpochs, que indica el número de épocas a entrenar los modelos.
# Load the Fashion MNIST dataset fmnist = tf.keras.datasets.fashion_mnist # Load the training and test split of the Fashion MNIST dataset (x_train, y_train), (x_val, y_val) = fmnist.load_data() # Normalize the pixel values of the train and test images x_train = x_train / 255.0 x_val = x_val / 255.0
Se carga el dataset Fashion MNIST, que viene con Tensorflow. Después de cargarlo se divide el dataset en cuatro partes, dos para entreno y dos para validar. Cada una conteniendo un juego de datos y labels.
Para finalizar se normaliza cada imagen dividiendo por 255.0.
Functions.
def plot_loss_acc(history):
'''Plots the training and validation loss and accuracy from a history object'''
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo-', label='Training accuracy')
plt.plot(epochs, val_acc, 'go-', label='Validation accuracy')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo-', label='Training Loss')
plt.plot(epochs, val_loss, 'go-', label='Validation Loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
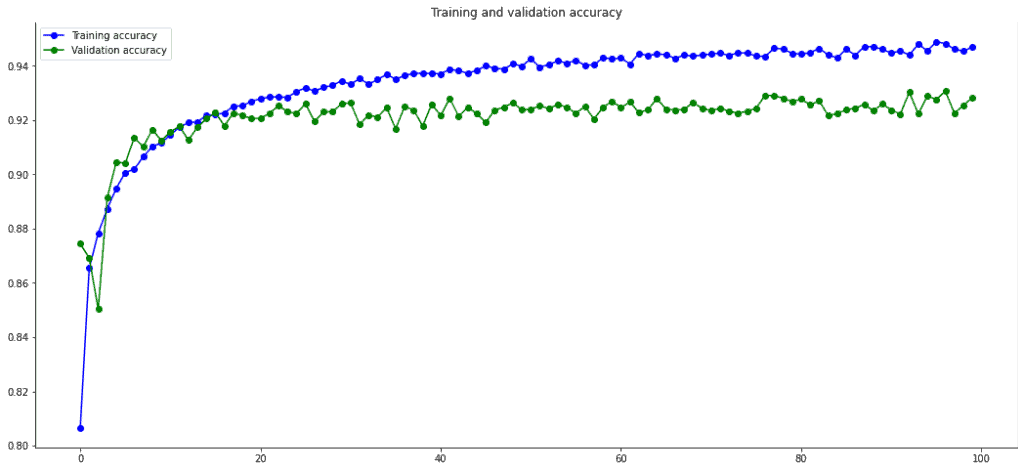
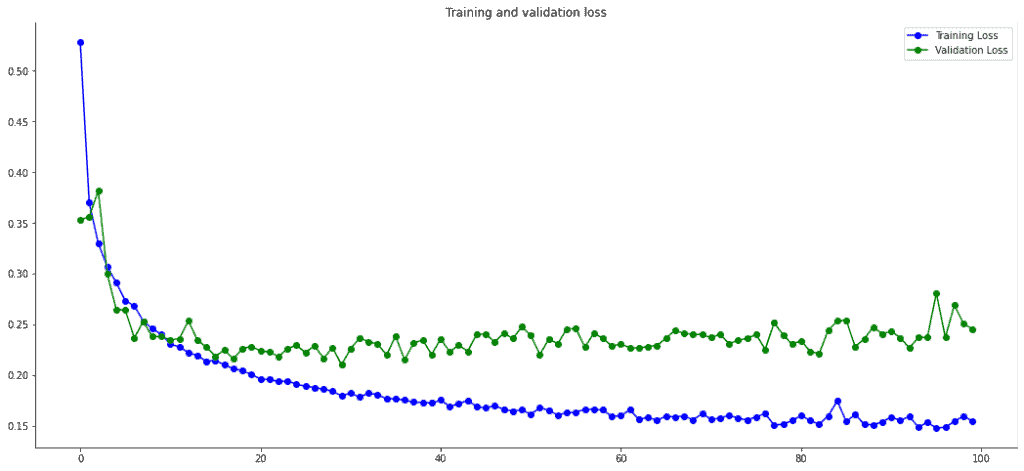
Nos muestra dos gráficas. En la primera se puede ver la Accuracy de los datos de training y los datos de validación en cada época. La segunda nos muestra una gráfica igual, pero con el dato de Loss.
La Gráfica nos va perfecta para detectar cuando un modelo puede tener un problema de overfitting, al separarse las curvas de loss de training y validation. También nos permite detectar en qué época se podría parar el aprendizaje al no continuar subiendo la curva. O si tuviésemos algún problema con el learning_rate, que podríamos verlo al tener una curva con muchas subidas y bajadas.
def plot_loss_acc_lr(history):
rcParams['figure.figsize'] = (18, 8)
rcParams['axes.spines.top'] = False
rcParams['axes.spines.right'] = False
plt.plot(
np.arange(1, 101),
history.history['loss'],
label='Loss', lw=3
)
plt.plot(
np.arange(1, 101),
history.history['accuracy'],
label='Accuracy', lw=3
)
plt.plot(
np.arange(1, 101),
history.history['lr'],
label='Learning rate', color='#000', lw=3, linestyle='--'
)
plt.title('Evaluation metrics', size=20)
plt.xlabel('Epoch', size=14)
plt.legend();
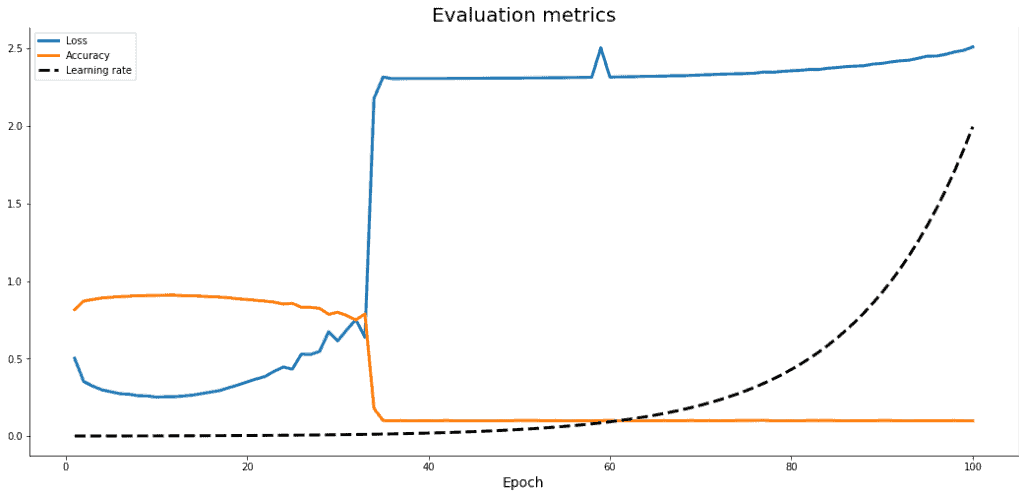
Traza una gráfica donde podemos ver el Accuracy, el Loss y el learning_rate. Esta pensada para poder localizar rápidamente un learning_rate optimo para nuestro modelo, en el caso de que queramos personalizarlo.
Para ello se ejecuta el modelo con una función de callback que modificará el learning_rate a cada epoca. En esta gráfica podemos ver que el learning rate correcto sería el usado entre las épocas 7 y 9 más o menos.
class myCallback(tf.keras.callbacks.Callback):
# Define the correct function signature for on_epoch_end
def on_epoch_end(self, epoch, logs={}):
if logs.get('val_accuracy') is not None and logs.get('val_accuracy') > 0.95:
print("\nReached 95% val_accuracy so cancelling training!")
# Stop training once the above condition is met
self.model.stop_training = True
callbacks = myCallback()
Esta es la función de callback a pasar en el .fit del modelo. En esta función lo único que se hace es vigilar el val_accuracy, pero podríamos vigilar tranquilamente el accuracy, y cuando se llega a un porcentaje se para el proceso de aprendizaje.
def get_model(kindmodel):
default = tf.keras.models.Sequential([tf.keras.layers.Flatten(input_shape=[28, 28, 1]),
tf.keras.layers.Dense(128, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)])
switcher = {
#First simple model, just to have a point where to start.
#we got a lot of overffiting with this model.
#100 epochs
# 6s 3ms/step loss: 0.0575 - accuracy: 0.9788 - val_loss: 0.8411 - val_accuracy: 0.8788
0: tf.keras.models.Sequential([tf.keras.layers.Flatten(input_shape=[28, 28, 1]),
tf.keras.layers.Dense(128, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)]),
#simple convolutional model just to apply some filters to the images
#a lot of overfitting too
#100 epochs.
# 9s 5ms/step - loss: 0.0277 - accuracy: 0.9920 - val_loss: 1.3412 - val_accuracy: 0.8906
#After Data Augmentation:
#100 epochs:
# 22s 47ms/step - loss: 0.2268 - accuracy: 0.9146 - val_loss: 0.3091 - val_accuracy: 0.8955
1: tf.keras.models.Sequential([tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(128, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')]),
#To avoid overfitting I'm going to add some dropout layers. and it works!
#The curve is realy nice, wiuth the samen numbers betewwen training and validating data
#100 epochs
# 10s 5ms/step - loss: 0.2712 - accuracy: 0.9015 - val_loss: 0.2841 - val_accuracy: 0.8950
#After Data Augmentation:
#100 epochs:
# 22s 46ms/step - loss: 0.4052 - accuracy: 0.8544 - val_loss: 0.3293 - val_accuracy: 0.8794
2: tf.keras.models.Sequential([tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Conv2D(128, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Dropout(0.4),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.4),
tf.keras.layers.Dense(10, activation='softmax')]),
#More powerful version of the model 2. With more filters in the Conv layers and a bigger dense layer.
#100 epochs
# 10s 5ms/step - loss: 0.2150 - accuracy: 0.9239 - val_loss: 0.3072 - val_accuracy: 0.8975
#After Data Augmentation:
#100 epochs:
# 22s 47ms/step - loss: 0.3286 - accuracy: 0.8800 - val_loss: 0.2861 - val_accuracy: 0.8961
21: tf.keras.models.Sequential([tf.keras.layers.Conv2D(64, (3,3), activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Conv2D(128, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Conv2D(256, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Dropout(0.4),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dropout(0.4),
tf.keras.layers.Dense(10, activation='softmax')]),
#Add more convolutional layers and mixing dropout with batchnormalization, and remove some MaxPooling to mantain more
#100 eopochs
# 10s 5ms/step - loss: 0.0867 - accuracy: 0.9692 - val_loss: 0.2542 - val_accuracy: 0.9327
# lr: 0.0016
# 10s 5ms/step - loss: 0.1545 - accuracy: 0.9470 - val_loss: 0.2455 - val_accuracy: 0.9283
#After Data Augmentatiuon
#100 epochs:
# 16s 35ms/step - loss: 0.1895 - accuracy: 0.9301 - val_loss: 0.2020 - val_accuracy: 0.9271
22: tf.keras.models.Sequential([tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Conv2D(32, (3,3), activation='relu'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.BatchNormalization(),
#tf.keras.layers.Dropout(0.2),
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Dropout(0.4),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')]),
#This model is based in one that works really fine in Kaggle with MNIST dataset.
#Reference model 1.
#https://www.kaggle.com/code/cdeotte/how-to-choose-cnn-architecture-mnist/notebook
#Author: CHRIS DEOTE
#The accuracy is really good in both sets of data, but it have some signs of overfitting, i'm not sure about
#how the model will work with more epochs.
#100 epochs:
# 14s 8ms/step - loss: 0.0466 - accuracy: 0.9837 - val_loss: 0.2819 - val_accuracy: 0.9350
#After Data Augmentation:
#100 epochs:
# 23s 50ms/step - loss: 0.1745 - accuracy: 0.9359 - val_loss: 0.1891 - val_accuracy: 0.9322
3: tf.keras.models.Sequential([tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Conv2D(32, (3,3), activation='relu'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Conv2D(32, (5,5), strides=2, activation='relu', padding='same'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Dropout(0.4),
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Conv2D(64, (5,5), strides=2, activation='relu', padding='same'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Dropout(0.4),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Dropout(0.4),
tf.keras.layers.Dense(10, activation='softmax')]),
#another model adapted from Kaggle, in this ocassion a top 1%, by Kassem.
#https://www.kaggle.com/code/elcaiseri/mnist-simple-cnn-keras-accuracy-0-99-top-1
#100 epochs
# 10s 5ms/step - loss: 0.0082 - accuracy: 0.9977 - val_loss: 0.7954 - val_accuracy: 0.9231
#After Data Augmentation:
#100 epochs:
# 24s 52ms/step - loss: 0.0575 - accuracy: 0.9791 - val_loss: 0.3185 - val_accuracy: 0.9265
4: tf.keras.models.Sequential([tf.keras.layers.Conv2D(64, (3,3), activation="relu", input_shape=(28,28,1)),
tf.keras.layers.Conv2D(filters=64, kernel_size = (3,3), activation="relu"),
tf.keras.layers.MaxPooling2D(pool_size=(2,2)),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Conv2D(filters=128, kernel_size = (3,3), activation="relu"),
tf.keras.layers.Conv2D(filters=128, kernel_size = (3,3), activation="relu"),
tf.keras.layers.MaxPooling2D(pool_size=(2,2)),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Conv2D(filters=256, kernel_size = (3,3), activation="relu"),
tf.keras.layers.MaxPooling2D(pool_size=(2,2)),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512,activation="relu"),
tf.keras.layers.Dense(10,activation="softmax")]),
}
#return model
return switcher.get(kindmodel, default)
Todos los modelos usados están contenidos en la función get_model. Prefiero tenerlo así, y no desperdigados por el notebook, simplemente porque me es mucho más sencillo compararlos y encontrarlos en caso de que necesite consultarlos.
Como se puede ver hay modelos muy diferentes. Desde el más simple posible para este problema, hasta varios que utilizan combinaciones de diferentes capas para intentar aumentar el accuracy o reducir el overfitting.
Los modelos los he ejecutado dos veces, la primera ha sido con los datos tal como han salido del dataset, bueno, tan solo normalizando las imágenes. La segunda vez he utilizado data augmentation para reducir el overfitting, por lo que el comportamiento de los modelos se ha modificado, ya que las imágenes que reciben los modelos son diferentes al pasar por el proceso de data augmentation.
Vamos a ver el resultado de cada uno de los modelos, y intentare dar una pequeña explicación del por que de la forma del modelo y sus resultados.
Modelo simple.
tf.keras.models.Sequential([ tf.keras.layers.Flatten(input_shape=[28, 28, 1]), tf.keras.layers.Dense(128, activation=tf.nn.relu), tf.keras.layers.Dense(10, activation=tf.nn.softmax)])
Es el modelo de referencia, lo uso tan solo para probar que todo funciona correctamente, pero también al ser el modelo más sencillo su velocidad de aprendizaje es la mejor.
Resultados:
5s 2ms/step – loss: 0.0547 – accuracy: 0.9796 – val_loss: 0.7742 – val_accuracy: 0.8826
14s 29ms/step – loss: 0.3927 – accuracy: 0.8554 – val_loss: 0.3729 – val_accuracy: 0.8658*Con Data Augmentation
El modelo tiene un claro problema de overfitting. Es decir funciona mucho mejor con los datos de entreno que con los datos de validación, y a medida que van pasando las épocas el loss de los datos de validación va aumentando, por lo que no serviría de nada entrenarlo más.
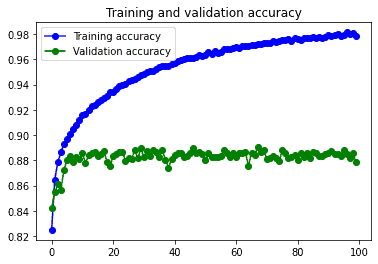
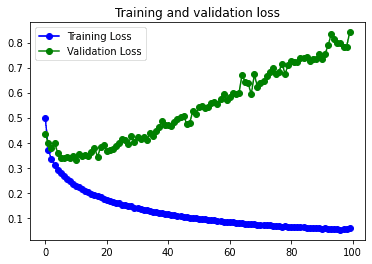

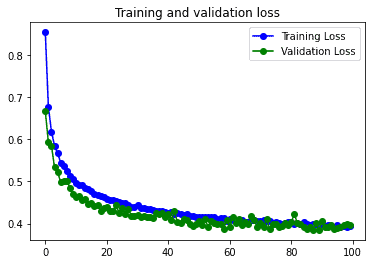
En las gráficas se puede observar que el problema de overfitting queda resuelto al usar el Data Augmentation. Pero la simpleza del modelo no le permite pasar de un 87% de accuracy en los datos de validación.
Simple Convolutional Model
tf.keras.models.Sequential([ tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(28, 28, 1)), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Conv2D(64, (3,3), activation='relu'), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Conv2D(128, (3,3), activation='relu'), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Flatten(), tf.keras.layers.Dense(128, activation='relu'), tf.keras.layers.Dense(10, activation='softmax')]),
Aplico tres capas convolucionales, de 32, 64 y 128 filtros, por orden. aunque la tercera capa realmente aporta muy poco. El Dataset són imagenes simples. Después de cada capa convolutional he usado una capa de MaxPooling para ayudar a resaltar las features. Al hacer maxpooling de 2,2 coge un cuadrado de cuatro píxeles y se queda con el valor mayor. Por lo que también reduce el tamaño de la imagen.
Sin Data Augmentation.
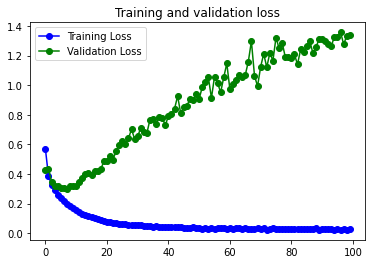
9s 5ms/step – loss: 0.0277 – accuracy: 0.9920 – val_loss: 1.3412 – val_accuracy: 0.8906
22s 47ms/step – loss: 0.2268 – accuracy: 0.9146 – val_loss: 0.3091 – val_accuracy: 0.8955*Data Augmentation
Mejora en muy poco el accuracy del modelo simple, tarda el doble y tiene exactamente el mismo problema de overfitting, incluso mayor. Es decir, para este juego de datos quizás no nos valga la pena complicar demasiado el modelo. Lo que está claro es que tenemos que trabajar en el overfitting. Para esto hay dos caminos, empezar a usar capas de Dropout y trabajar en los datos con Data Augmentation, o una combinación de las dos.
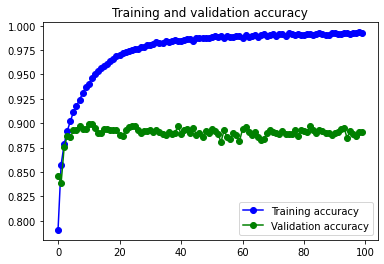
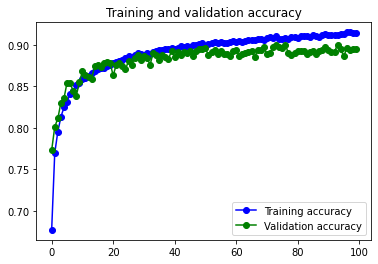
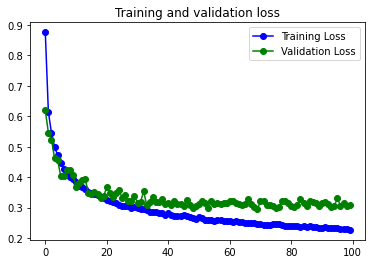
Se reduce muchísimo el problema de overfitting y aumenta un poco el accuracy respecto al mismo modelo con los datos sin pasar por el Data augmentation.
Model with Dropout Layers.
tf.keras.models.Sequential([ tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(28, 28, 1)), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Dropout(0.2), tf.keras.layers.Conv2D(64, (3,3), activation='relu'), tf.keras.layers.MaxPooling2D(2,2), tf.keras.layers.Dropout(0.2), tf.keras.layers.Conv2D(128, (3,3), activation='relu'), tf.keras.layers.MaxPooling2D(2,2), tf.keras.layers.Dropout(0.4), tf.keras.layers.Flatten(), tf.keras.layers.Dense(128, activation='relu'), tf.keras.layers.Dropout(0.4), tf.keras.layers.Dense(10, activation='softmax')])
Las capas de dropout se añaden al modelo convolucional para que ayuden a eliminar el problema de overfitting cuando trabaja con los datos sin tratar. La capa de dropout elimina aleatoriamente el valor de unos neurones, el porcentaje se le indica en el parámetro al crear la capa. Con esto se consigue que el modelo no pueda confiar demasiado en los mismos neurones, ya que no sabe cuándo le van a venir sin informar.
Rresultados:
10s 5ms/step – loss: 0.2712 – accuracy: 0.9015 – val_loss: 0.2841 – val_accuracy: 0.8950
22s 46ms/step – loss: 0.4052 – accuracy: 0.8544 – val_loss: 0.3293 – val_accuracy: 0.8794*Con Data Augmentation
Respecto al modelo convolucional sin capas de dropout conseguimos nuestro objetivo: reducir el overfitting. El val_loss pasa de 1.3412 a a 0.2841, y el val_accuracy aumenta un poco. Por lo que parece claro que este modelo funciona mucho mejor.
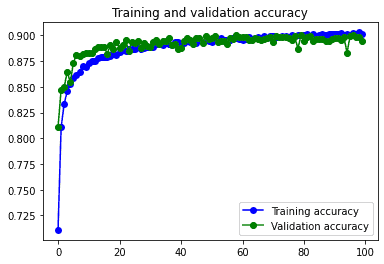
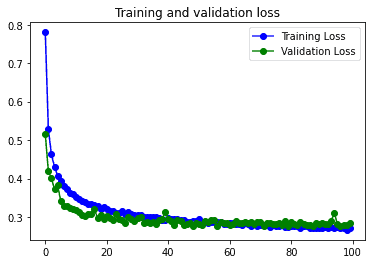
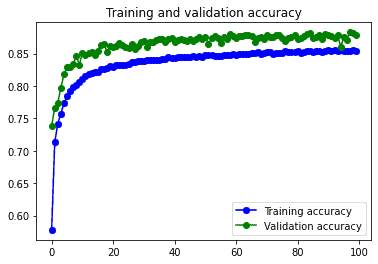
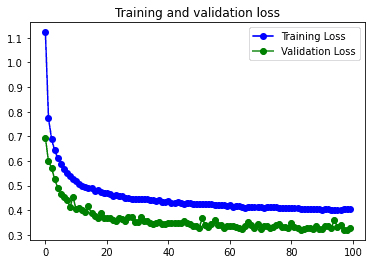
Como este modelo ya dispone de las capas de Dropout para reducir el overfitting no se ve demasiado afectado por el Data augmentation. Esto no tienen por que suceder siempre, depende mucho de cómo sean las imágenes del dataset.
Se podría decir que el modelo funciona mejor con el dataset sin pasar por el data augmentation, ya que consigue unos resultados ligeramente mejores en mucho menos tiempo.
Convolutional Model Powered 1
tf.keras.models.Sequential([ tf.keras.layers.Conv2D(64, (3,3), activation='relu', input_shape=(28, 28, 1)), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Dropout(0.2), tf.keras.layers.Conv2D(128, (3,3), activation='relu'), tf.keras.layers.MaxPooling2D(2,2), tf.keras.layers.Dropout(0.2), tf.keras.layers.Conv2D(256, (3,3), activation='relu'), tf.keras.layers.MaxPooling2D(2,2), tf.keras.layers.Dropout(0.4), tf.keras.layers.Flatten(), tf.keras.layers.Dense(512, activation='relu'), tf.keras.layers.Dropout(0.4), tf.keras.layers.Dense(10, activation='softmax')])
Este modelo duplica el número de filtros de cada capa convolutional y aumenta también el número de nodos de la capa Densa que viene después del Flatten. Se utiliza la misma estructura que en el Modelo Convolutional anterior, pero es más pesado.
Resultados:
10s 5ms/step – loss: 0.2150 – accuracy: 0.9239 – val_loss: 0.3072 – val_accuracy: 0.8975
22s 47ms/step – loss: 0.3286 – accuracy: 0.8800 – val_loss: 0.2861 – val_accuracy: 0.8961*Con Data Augmentation
Comparado con el modelo anterior se comporta mejor con Data Augmentation, pero pero con los datos sin aumentar, parece que en el primer caso el val_loss empeora. Posiblemente por que hemos aumentado la información disponible al incorporar más filtros, pero no hemos aumentado el valor de las capas de dropout, por lo que se empieza a ver algo de Overfitting.
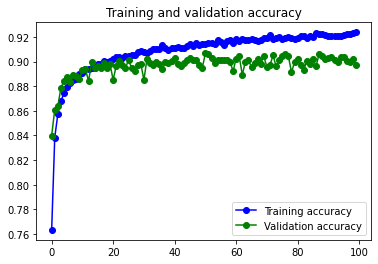
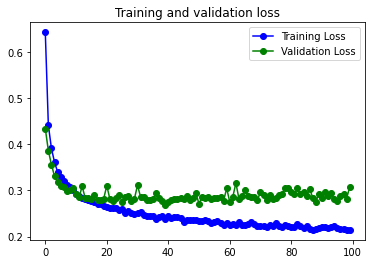
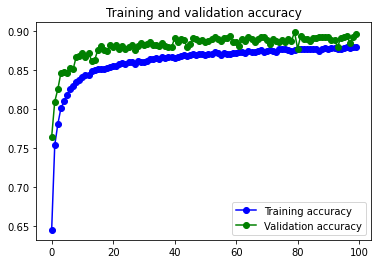
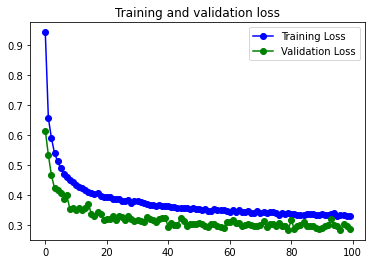
En los graficos se puede observar como los resultados con el dataset aumentado eliminan el pequeño problema de Overfitting, manteniendo más o menos el mismo valor de val_accuracy.
El modelo no consigue una mejora significativa respecto al mismo modelo con menos filtros y menos neuronas en la capa densa. Posiblemente causado por el Dataset, compuesto por imágenes muy pequeñas y sencillas.
Convolutional Model Powered 2.
tf.keras.models.Sequential([ tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(28, 28, 1)), tf.keras.layers.BatchNormalization(), tf.keras.layers.Conv2D(32, (3,3), activation='relu'), tf.keras.layers.BatchNormalization(), tf.keras.layers.Conv2D(64, (3,3), activation='relu'), tf.keras.layers.BatchNormalization(), tf.keras.layers.Conv2D(64, (3,3), activation='relu'), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Dropout(0.2), tf.keras.layers.Conv2D(64, (3,3), activation='relu'), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Dropout(0.4), tf.keras.layers.Flatten(), tf.keras.layers.Dense(128, activation='relu'), tf.keras.layers.Dense(10, activation='softmax')])
Se combinan las capas de BatchNormalization con capas de MaxPooling. Las capas de BatchNormalization normalizan las entradas y a diferencia de lo que ocurre con una capa de maxpooling no elimina datos. Para nuestro Dataset quizás sean más útiles.
Resultados:
11s 6ms/step – loss: 0.0810 – accuracy: 0.9714 – val_loss: 0.2444 – val_accuracy: 0.9338
18s 39ms/step – loss: 0.1952 – accuracy: 0.9291 – val_loss: 0.2030 – val_accuracy: 0.9269
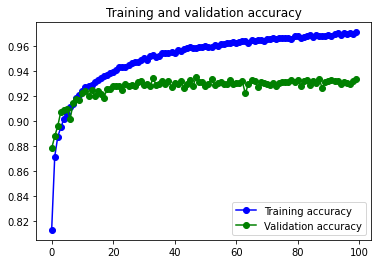
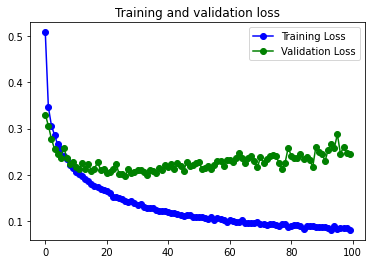
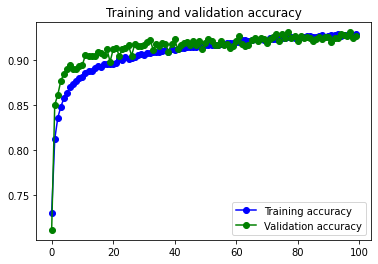
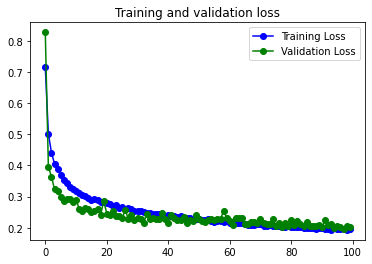
El modelo obtiene unos datos de accuracy y val_accuracy muy buenos. Con los datos sin data augmentation se aprecia un inicio de overfitting, creo que fácilmente solucionable aumentando el valor de las capas de dropout, o incorporando capas de dropout después de volvolucionales.
Con los datos pasados por Data augmentation desaparece totalmente el overfitting, y los números de accuracy se mantienen buenos, pero disminuyen un poco. Posiblemente se podría mejorar su funcionamiento si sustituyeramos alguna de las capas de MaxPooling que hemos dejado por otra de BatchNormalization.
En todo caso el modelo funciona muy bien con los dos juegos de datos.
Resumen de los modelos.
Hemos visto casi todos los modelos que hay en la función. Nos faltan dos, pero para ser sincero, esos no son mios, los he obtenido de Kaggle y no acaban de aportar nada que no aporte el «Convolutiona Powered 2». De largo creo que es el mejor modelo y que se podría afinar aún más. Pero como se trata de pasar el examen, y no tengo claro que Dataset me van a facilitar lo defaré aqui.
Al final del Notebook hay un pequeño experimento que consiste en ejecutar el modelo cambiando el learning rate en cada época, identificar con qué Learning Rate se obtiene mejor resultado y probarlo pasandoselo al optimizador. Como el optimizador que estoy usando es el Adam y él ya ajusta bastante bien el learning rate. Pero repito, que el notebook lo he creado para que me ayude con el examen de TensorFlow, y lo de ajustar el learning Rate es uno de los puntos que me dicen que puede salir.
Ajuste del Learning Rate.
lr_schedule = tf.keras.callbacks.LearningRateScheduler( lambda epoch: 1e-3 * 10 ** (epoch / 30))
Esta función es la que modifica el learning rate en cada epoca. Se le pasa al llamar al .fit del modelo como una función de callback y ya está.
optim=Adam() modelr22.compile(optimizer=optim, loss='sparse_categorical_crossentropy', metrics=['accuracy']) historylr22 = modelr22.fit(x_train, y_train, epochs=100, validation_data = (x_val, y_val), callbacks=[callbacks, lr_schedule])
Epoch 1/100 1875/1875 [==============================] - 20s 5ms/step - loss: 0.5090 - accuracy: 0.8134 - val_loss: 0.3850 - val_accuracy: 0.8615 - lr: 0.0010 Epoch 2/100 1875/1875 [==============================] - 10s 5ms/step - loss: 0.3538 - accuracy: 0.8689 - val_loss: 0.3210 - val_accuracy: 0.8777 - lr: 0.0011 Epoch 3/100 1875/1875 [==============================] - 9s 5ms/step - loss: 0.3175 - accuracy: 0.8825 - val_loss: 0.2822 - val_accuracy: 0.8905 - lr: 0.0012 Epoch 4/100 .................
En este ejemplo de las tres primeras épocas podemos ver como ha utilizado tres learning rates diferentes. Después con la función plot_loss_acc_lr que podeis ver en el apartado de funciones del notebook se saca la siguiente gráfica:
Ahora tocaria identificar, ayudándonos con la traza de la ejecución del modelo y de la gráfica qué learning Rate podemos usar para entrenar el modelo.
Tenemos que escoger un learning rate correcto. Para ello podemos escoger uno que esté en la parte baja del Loss, que en este caso sería entre la época 7 y 10.
Despues cuestión de ejecutar de nuevo el modelo, pero pasandole el learning rate que hayamos decidido al optimizador, y ver cual es el resultado!
Siguientes pasos para preparar el examen de Tensorflow Certified Developer.
Con este Notebook creo que cubró buena parte del apartado de imagen del examen de TensorFlow. Pero no todo, trabajaré con un dataset que contenga imágenes más reales, y que sobretodo estén en disco, que no sea un dataset de los que vienen con TensorFlow. Por que uno de los puntos que me han quedado sin tratar es este:
❏ Understand how ImageDataGenerator labels images based on the directory structure.
y recordemos que el objetivo es NO pagar dos veces el examen!!!!
El proximo notebook, serà todavía de Clasificación de imágenes y posiblemente intentaRé tratar tambien el Transfer Learning!
Comments