
Realizar un entreno desde 0 de uno de los Grandes Modelos de Lenguaje actuales es una acción al alcance de muy poco. Las horas de GPUs necesarias y el coste son prohibitivos para la mayoría de las empresas, y no estoy hablando de pequeñas empresas. Empresas que se pueden considerar grandes, sobre todo a nivel nacional, no disponen del músculo necesario para entrenar un modelo desde cero. Aunque hay un motivo mucho más importante: tampoco lo necesitan.
La alternativa a entrenar un modelo, es coger uno ya preentrenado, y enseñarle comportamientos más específicos mediante FineTunig. Una técnica en la que un nuevo proceso de aprendizaje modifica los pesos de algunas capas del modelo.
Pues bien, el Finetuning, debido al tamaño de los Grandes Modelos actuales, ha evolucionado con la aparición de nuevas técnicas que nos permiten FineTunear un modelo de la forma más óptima posible. Reduciendo al máximo el número de pesos a actualizar, y así poder entrenar al modelo con menor tiempo y coste.
La librería PEFT de Hugging Face.
PEFT es el acrónimo de Parameter Efficient FineTuning. Esta librería nos permite ejecutar técnicas de Finetuning optimizadas para reducir el número de parámetros a entrenar. Reduciendo así el tiempo y coste de enseñar nuevos conocimientos a un Modelo.
Con PEFT podemos optar a tres categorías diferentes de Finetunning. Aditivas, Selectivas y re-parametrización.

Cada una de estas categorías tiene sus ventajas y sus desventajas. Posiblemente, el método más conocido y usado actualmente sea LoRA. Por otro lado, Prompt-Tuning es la gran desconocida que va siendo más usada para casos muy concretos. Las técnicas de Prunning van perdiendo terreno, así que me voy a centrar en explicar tan solo el funcionamiento de dos técnicas, el Prompt-Tuning y LoRA, que serán las que vamos a usar más adelante en el curso de Aplicaciones con Grandes Modelos de Lenguaje.
Prompt Tuning.
Esta categoría se llama aditiva, porque estamos añadiendo capas al modelo. No modificamos los pesos del Modelo base.
Se añaden unos valores a los embeddings contenidos en el prompt, y estos valores añadidos son los que se entrenan, es decir, tan solo estamos modificando el peso de los parámetros del prompt.
El entreno del modelo se produce de la forma común, es decir, modificando el peso de los parámetros que no están fijados, con el objetivo de reducir el error devuelto por la función de pérdida.
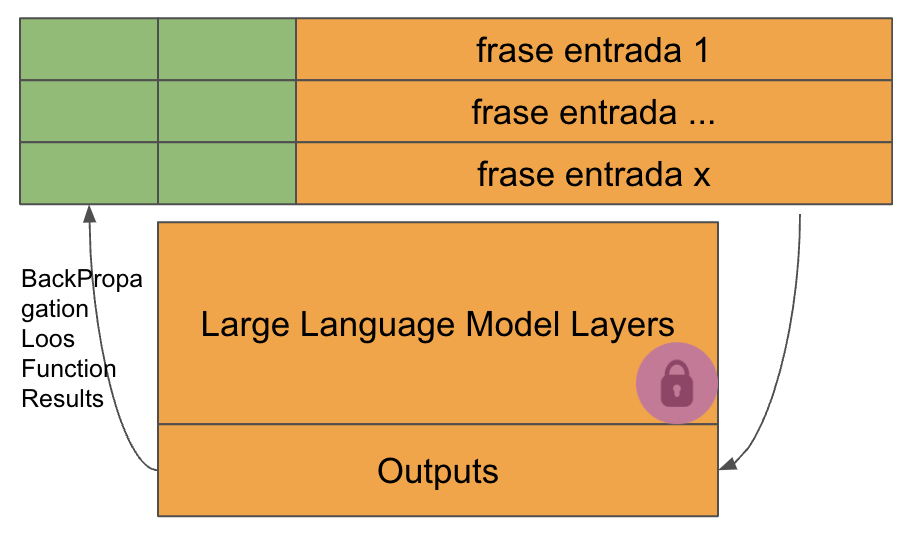
Cada secuencia de embeddings enviada al modelo contiene unos tokens añadidos, y son estos tokens los que son modificados para reducir el resultado devuelto por la función de pérdida.
Como se puede ver, el número de parámetros a modificar es muy pequeño, y ninguno corresponde al modelo. Esta es una técnica muy especial y que está dando unos resultados muy buenos.
Una de las principales características es que podemos utilizar un solo modelo para diferentes usos. Ahorrando no tan solo espacio de almacenamiento, sino también espacio en memoria, ya que únicamente hace falta cargar un modelo. Puesto que no hemos modificado sus pesos y el modelo funcionará igual, sea cual sea el prompt que estemos usando.
Características:
- Funciona mejor con modelos grandes. Lo que todavía produce más ahorro.
- Funciona bien para temas específicos. No para introducir información general.
- Rendimiento superior a técnicas como el Few Shot Prompt, que aumenta el prompt pasándole algunos ejemplos de lo que tendría que hacer el modelo.
Paper: The Power of Scale for Parameter-Efficient Prompt Tuning.
Notebook de Ejemplo: https://github.com/peremartra/Large-Language-Model-Notebooks-Course/blob/main/5-Fine%20Tuning/Prompt_Tuning_PEFT.ipynb
Re-parametrización. LoRA.
Dentro de la categoría de re-parametrización encontramos la técnica LoRA. Su funcionamiento es sencillo, complicado y brillante al mismo tiempo. Se trata de reducir el tamaño de las matrices a entrenar, dividiéndolas de tal forma que al multiplicarlas nos vuelva a dar la matriz origen.
Los pesos que se modifican son los de las matrices reducidas, no la de la matriz origen. Mejor lo vemos en una imagen.
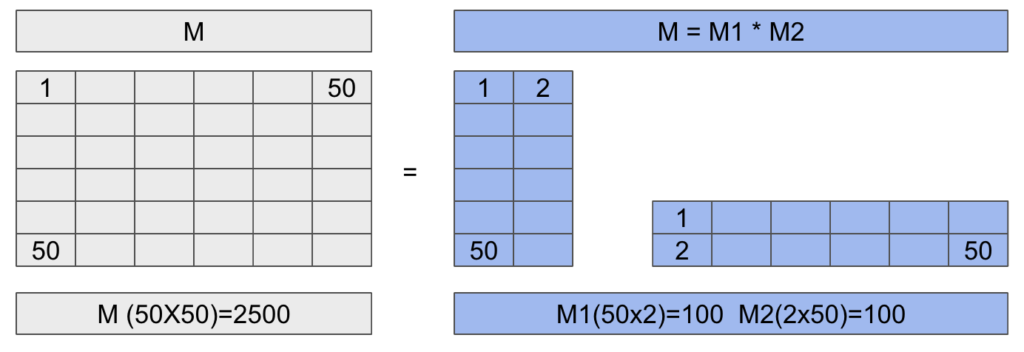
Tenemos una matriz original de 50×50, lo que significa que tendríamos que modificar unos 2500 parámetros. Pero como sabemos, si multiplicamos dos matrices de (2×50) y (50×2) obtenemos una matriz de 50×50. Sin embargo, estas dos matrices tan solo están formadas por 100 parámetros cada una. Es decir, que en total para las matrices reducidas tenemos que modificar 200 parámetros frente a los 2500 de la matriz original. Esto nos representa una reducción del 92%, y como mayor sea la matriz origen, mayor será el porcentaje de ahorro.
Tal como he dicho, a mí me parece, sencillo, complicado y brillante.
En Modelos de Lenguaje como GPT 3, o cualquiera de los actuales con LoRA es posible que tan solo tengamos que entrenar un 0.02 de los parámetros originales. Varía para cada modelo. Lo mejor es que el resultado obtenido es muy parecido al de un fine-tuning completo, en algunos casos incluso puede ser mejor.
Resumen.
Hemos visto tan solo dos técnicas de las muchas que hay en la librería PeFT, pero son suficientes para hacernos una idea de que existe una necesidad en el mercado de realizar entrenos forma más eficiente, aunque sea sacrificando algo de estabilidad en la respuesta del modelo.
Es un campo en el que ya se lleva cierto tiempo investigando, pero recientemente se han acelerado las implementaciones. Dos de las más recientes son QLoRA, que es un método de LoRA que usa también quantization (reducir longitud de números) o un nuevo método llamado IA3 que promete reducir aún más el número de parámetros entrenables de lo que se consigue con LoRA.
Este paper es un gran ejemplo de todo lo que se está haciendo: https://arxiv.org/abs/2205.05638. En él se comparan diferentes técnicas disponibles en PEFT y se ha llegado a la conclusión que entrenar un modelo puede ser más barato que utilizar técnicas de enriquecimiento del prompt. En él también se usan IA3 y se demuestra ser un método muy eficiente.
¡Un Mundo apasionante! Espero que os haya gustado. En breve, un par de artículos aplicando esta técnica en el entreno de modelos. Recordad que podéis encontrar toda la información y los notebooks usados en el curso de Grandes Modelos de Lenguaje en Github.