
Vamos a dar un paso de gigante en la complejidad de nuestra GAN. En los artículos anteriores hemos creado dos GANs sencillas, usando Datasets igualmente sencillos.
En este artículo vamos a usar un Dataset mucho más complicado, con imágenes más grandes a todo color. El Dataset está formado por, 200.000 imágenes de rostros de personajes famosos.
La GAN va a intentar generar caras realistas, que sean capaces de pasar por caras que podría pertenecer a personas existentes. Aunque he limitado el tamaño de las imágenes a 80 x 80, el trabajo de entrenar la GAN puede resultar muy pesado, por lo que en una GPU bien podría tardar un par de horas o más. Un buen método para acelerar el proceso es usar TPUs en lugar de GPUs, un procesador más potente disponible en algunos clouds como Google Colab o Kaggle.
Este cambio que parece sencillo y poca cosa, ya que se podría pensar que tan solo se necesita cambiar el entorno en Google Colab, como cuando cambiamos de CPU a GPU. Pero no es así. Vamos a tener que adaptar nuestro código.
Para saber más sobre TPUs:
https://codelabs.developers.google.com/codelabs/keras-flowers-data/#2
Codelab
No voy a explicar que es ni como funciona una TPU, nos basta con saber que es un procesador mucho más rápido que una GPU para realizar tareas de Deep Learning, no hace falta entrar en más detalles.
Aprovechando que trabajamos con un Dataset de caras, vamos a explorar la posibilidad de usar la librería MTCNN de detección de rostros para seleccionar tan solo la parte de la imagen que contiene la cara.
Tenéis el código disponible en Github y Colab.
https://github.com/oopere/GANs/blob/main/C3_Faces_TPU.ipynb
https://colab.research.google.com/drive/1p6sQqiu4kWeDpxu91C0MQBX9P6qSwmPG?usp=sharing
Activar la TPU.
Para activar el uso de TPUs para nuestro notebook hay que hacer dos cosas: seleccionarlo en el menú de Google Colab y recuperar la instancia de la TPU.
En Google Colab encontramos la opción de cambiar de entorno en el menú: Entorno de Ejecución -> Cambiar tipo de entorno de ejecución.
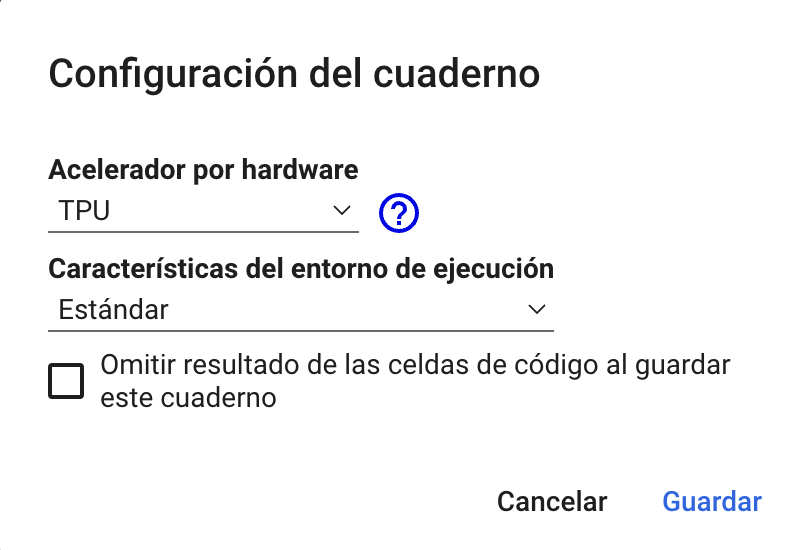
Una vez ya hemos escogido en entorno hay que instanciar la TPU.
try:
tpu = tf.distribute.cluster_resolver.TPUClusterResolver()
except ValueError:
raise BaseException("CAN'T CONNECT TO A TPU")
tf.config.experimental_connect_to_cluster(tpu)
tf.tpu.experimental.initialize_tpu_system(tpu)
strategy = tf.distribute.TPUStrategy(tpu)
El código persigue construir una estrategia de ejecución del código. Lo primero es conectar a una TPU. Una vez conectados creamos la estrategia con tf.distribute.TPUStrategy. Le indicamos que vamos a ejecutar el código de forma distribuida. Con lo que el Dataset va a tener que dividirse entre diferentes máquinas, al igual que nuestro código que va a estar ejecutándose en paralelo. En algún momento vamos a tener que decidir la estrategia para tratar las diferentes respuestas obtenidas de las ejecuciones en paralelo.
Cargar y preparar el Dataset.
El Dataset que vamos a usar es el CelebA Dataset. Está formado por unas, 200000 imágenes de famosos. Yo lo voy a bajar de un repositorio en Google, pero hay muchas fuentes en las que está disponible.
Se puede encontrar en:
- Directorio Google: https://storage.googleapis.com/learning-datasets/Resources/archive.zip
- Kaggle: https://www.kaggle.com/datasets/jessicali9530/celeba-dataset
- Mmlab: https://mmlab.ie.cuhk.edu.hk/projects/CelebA.html
- TensorFlow: https://www.tensorflow.org/datasets/catalog/celeb_a?hl=es-419
# make a data directory
try:
os.mkdir('/tmp/celeb')
except OSError:
pass
# download the dataset archive
data_url = "https://storage.googleapis.com/learning-datasets/Resources/archive.zip"
data_file_name = "archive.zip"
download_dir = '/tmp/celeb/'
urllib.request.urlretrieve(data_url, data_file_name)
# extract the zipped file
zip_ref = zipfile.ZipFile(data_file_name, 'r')
zip_ref.extractall(download_dir)
zip_ref.close()
Lo primero que se hace es crear el directorio, en caso de que ya exista y de error, lo ignoramos. Nos bajamos el fichero que contiene las imágenes del directorio de Google donde está guardado y lo descomprimimos.
Con esto ya tendremos las imágenes descomprimidas en el directorio /tmp/celeb/img_align_celeba/img_align_celeba.
Ahora necesitaremos una función que cargue las imágenes y las transforme. Es decir, que les dé a todas el mismo tamaño y normalice el valor de sus píxeles a valores entre -1 y 1 tal y como se indica en las GAN Hacks.
Para ello he preparado dos funciones. La única diferencia es que una de ellas usa una librería para localizar donde está el rostro dentro de la imagen, mientras que la otra se limita a hacer un recorte de la parte central, que es donde suele estar. En ambos casos el tamaño de salida de la imagen es el mismo. Para el ejemplo he escogido un formato de 80 x 80.
En las dos funciones se puede indicar el número máximo de imágenes a utilizar, recomiendo que para hacer pruebas lo hagáis con unas 1000 imágenes, es suficiente para ver resultados.
#Function to load the faces.
#Crop & center the images because the faces is almost always in the center.
def load_faces(image_paths, resize, max_images):
crop_size = 128
if (max_images == 0):
max_images = len(image_paths)
print(max_images)
images = np.zeros((max_images, resize, resize, 3), np.uint8)
for i, path in tqdm(enumerate(image_paths)):
with Image.open(path) as img:
left = (img.size[0] - crop_size) // 2
top = (img.size[1] - crop_size) // 2
right = left + crop_size
bottom = top + crop_size
img = img.crop((left, top, right, bottom))
img = img.resize((resize, resize), Image.LANCZOS)
images[i] = np.asarray(img, np.uint8)
if (i >= max_images-1):
break
return images
Esta función se recorre todas las imágenes, del directorio, y recorta la zona del centro, que es donde suele estar el rostro, para que todas las imágenes tengan el mismo tamaño. Después ajusta el tamaño de la imagen al valor indicado en el parámetro resize.
Nos devuelve todas las imágenes recortadas y ajustadas al mismo tamaño.
En el notebook se puede encontrar una segunda función, que en lugar de centrar el recorte emplea la librería MTCNN para localizar el rostro.
#Funtion to load the faces. Use the MTCNN lybrary to detect where the face is.
def load_faces_MTCNN(image_paths, resize, max_images):
MTCNN_model = mtcnn.MTCNN()
if (max_images == 0):
max_images = len(image_paths)
print(max_images)
images = np.zeros((max_images, resize, resize, 3), np.uint8)
for i, path in enumerate(image_paths):
with Image.open(path) as img:
img = img.convert('RGB')
#img_pixels = np.asarray(img)
face = MTCNN_model.detect_faces(img_pixels)
if len(face) == 0:
#just in case MTCNN can't find a face
continue
x1, y1, width, height = face[0]['box']
x1, y1 = abs(x1), abs(y1)
x2, y2 = x1 + width, y1 + height
img = img.crop((x1, y1, x2, y2))
img = img.resize((resize, resize), Image.LANCZOS)
images[i] = np.asarray(img, np.uint8)
if (i >= max_images-1):
break
return images
La función detect_faces nos devuelve las coordenadas donde encuentra el rostro. El recorte se hace usando esas coordenadas, y después, al igual que en la función anterior, se ajusta el tamaño de las imágenes.
Las dos funciones comparten entradas y salida, por lo que podemos usar cualquiera de ellas. En el caso de que usemos la detección de rostros se penaliza en tiempo necesario para tratar las imágenes, pero da como resultado una GAN mejor entrenada.
A las imágenes devueltas por cualquiera de estas dos funciones aún les queda normalizar el valor de sus píxeles y ponerlas dentro de un dataset que sea apto para ser tratado en una estrategia distribuida.
Para normalizar los píxeles tenemos esta función:
def preprocess(img):
x = tf.cast(img, tf.float32) / 127.5 - 1.0
return x
Que la llamaremos en el momento de preparar el dataset.
dataset = tf.data.Dataset.from_tensor_slices((images1, images2))
dataset = dataset.map(
lambda x1, x2: (preprocess(x1), preprocess(x2))
).shuffle(4096).batch(batch_size, drop_remainder=True).prefetch(tf.data.experimental.AUTOTUNE)
return dataset
Al preparar el Dataset le pasamos dos juegos de imágenes, y mediante la función lambda se llama a la función preprocess para normalizar los píxeles de las imágenes.
Todo esto sucede dentro de una función:
#Load the pictures in the dataset. You can indicate the max_images. I recommend
#that for testing you use 1000 images, and when you want to see the result final
#use the max number of images, indicating 0 to max_images.
def load_celeba(batch_size, resize=80, max_images=0):
"""Creates batches of preprocessed images from the JPG files
Args:
batch_size - batch size
resize - size in pixels to resize the images
crop_size - size to crop from the image
Returns:
prepared dataset
"""
# initialize zero-filled array equal to the size of the dataset
image_paths = sorted(glob.glob("/tmp/celeb/img_align_celeba/img_align_celeba/*.jpg"))
print("Creating Images")
# crop and resize the raw images then put into the array
#choose wich function you want to use.
images = load_faces(image_paths, resize, max_images)
#images = load_faces_MTCNN(image_paths, resize, max_images)
#Plot the 5 first images.
plot_results(images[0:5], unnorm=False)
# split the images array into two
split_n = images.shape[0] // 2
images1, images2 = images[:split_n], images[split_n:2 * split_n]
del images
# preprocessing function to convert the pixel values into the range [-1,1]
#Is a GAN Hack to normalize the pixels of the images
def preprocess(img):
x = tf.cast(img, tf.float32) / 127.5 - 1.0
return x
# use the preprocessing function on the arrays and create batches
dataset = tf.data.Dataset.from_tensor_slices((images1, images2))
dataset = dataset.map(
lambda x1, x2: (preprocess(x1), preprocess(x2))
).shuffle(4096).batch(batch_size, drop_remainder=True).prefetch(tf.data.experimental.AUTOTUNE)
return dataset
Como se puede ver, la función a la que llamamos no usa la librería MTCNN de detección de caras. Pero se puede cambiar modificando la llamada a la función load_faces por una llamada a load_faces_MTCNN.
En la función recuperamos el nombre de las imágenes y las ponemos en image_paths. La que usamos en la llamada a la función load_faces, junto al tamaño y al número máximo de imágenes que queremos usar para entregar la GAN.
El número máximo, de imágenes a cargar, lo podemos cambiar sin problema, aunque recomiendo un mínimo de 1000. En caso de que queramos usar todas las imágenes del dataset tan solo tenemos que darle un valor de 0 a la variable max_images.
Como se puede ver en las últimas líneas, en la preparación del dataset se pasa cada una de las imágenes por la función preprocess, que se dedica a normalizar los valores de los píxeles a valores entre -1 y 1.
La creación del dataset se produce en la línea:
dataset = tf.data.Dataset.from_tensor_slices((images1, images2))
dataset = dataset.map(
lambda x1, x2: (preprocess(x1), preprocess(x2))
).shuffle(4096).batch(batch_size, drop_remainder=True).prefetch(tf.data.experimental.AUTOTUNE)
Como veis, dentro de dataset.map se preprocesan las imágenes mediante la función lambda. Las imágenes se barajan, y se crea el prefetch para que estén cargadas en memoria, y así acelerar el proceso de aprendizaje.
Vamos a ver la llamada a la función para crear el dataset:
# use the function above to load and prepare the dataset #Note how the batch_size is multiplied by strategy.num_replicas_in_sync batch_size = 8 batch_size = batch_size * strategy.num_replicas_in_sync dataset = load_celeba(batch_size, max_images=1000)
El tamaño del batch_size lo multiplicamos por el número de réplicas que va a tener nuestra estrategia de ejecución. El batch_size se acaba pasando a datasep.map para indicar el tamaño del batch.
Esta llamada se ha realizado en una de las pruebas para entrenar la GAN, y he usado tan solo 1000 imágenes. Para ver el resultado final lo mejor es indicar 0 en max_images y así utilizar todas las imágenes disponibles en el Dataset.
Como que en la función load_celeba tenemos una llamada a plot_results, una función de soporte para mostrar las imágenes, en la ejecución del notebook podremos ver cómo son las imágenes con las que vamos a entrenar la GAN.

Crear el Generador y el Discriminador.
Para una explicación más detallada de cómo funcionan el Generador y Discriminador de una GAN recomiendo la lectura del primer artículo de la serie dedicada al funcionamiento de las GAN: Como crear una GAN para el Dataset MNIST.
martra.uadla.com
Una GAN está compuesta de dos Modelos, el Generador y el Discriminador. El Generador crea imágenes tomando como punto de partida un conjunto de datos aleatorio, que se puede llamar ruido. Va transformando este ruido a través de sus capas hasta que consigue una imagen del formato indicado.
El discriminador se encarga de identificar si una imagen pertenece al Dataset original, es decir, es una imagen verdadera, o si, por el contrario, se trata de una imagen generada por el Generador.
El Generador de la GAN.
def adapt_generator(initial_0, nodes, upsamplings, multnodes = 1.0, endnodes = 3, input_noise=100):
#initial_0 : size of the initial mini image.
#nodes: nodes in the first Dense layers.
#upsamplings: number of upsamplings bucles.
#multnodes: a multiplicator to modify the nodes in each upsampling bucle.
#endnodes: nodes of the last layer. 1 for gray scale images, 3 for color images.
#input_noise: size of the noise.
model = keras.models.Sequential()
#First Dense layer.
model.add(keras.Input(shape=(1, 1, 128)))
nodeslayers = nodes
model.add(keras.layers.Conv2DTranspose(nodeslayers , kernel_size=initial_0, strides=1, padding="valid", use_bias=False))
#Upsampling bucles.
for i in range(upsamplings-1):
nodeslayers = int(nodeslayers * multnodes)
model.add(keras.layers.Conv2DTranspose(nodeslayers , kernel_size=4, strides=2, padding="SAME",
activation=keras.layers.LeakyReLU(alpha=0.2)))
model.add(keras.layers.BatchNormalization())
#last upsample and last layer.
model.add(keras.layers.Conv2DTranspose(endnodes, kernel_size=4, strides=2, padding="SAME",
activation='tanh'))
return model
La función adapt_generator nos permite indicar las características que debe tener el Generador de la GAN mediante sus parámetros. Esta función ya la vimos en el segundo artículo del tutorial de GANs: Crear una GAN que genere imágenes a color.
El Generador que queremos debe crear imágenes de 80 x 80 x 3. Como entrada recibiremos el ruido generado de forma aleatoria. Tenemos que llegar desde este ruido hasta el formato deseado de imagen a base de realizar upsamplings.
En nuestro modelo estos upsamplings se realizan con capas Conv2DTranspose con un stride de 2, lo que significa que la imagen duplica su longitud y anchura en cada upsample. Por ejemplo, podríamos partir de una imagen de 10 y ejecutar 2 upsamplings, o de una imagen de 5 y hacer cuatro upsamplings. Yo he optado por la segunda opción.
En el generador se usan varias de las GAN Hacks para optimizarlo.
- Uso de una capa de BatchNormalization después de cada Upsample.
- Uso del activador LeakyReLU con un alpha de 0.2.
- Uso del activador tanh en la última capa del modelo.
Para crear el generador he usado la llamada:
model_G = adapt_generator(5, nodes=128, upsamplings=4, multnodes=1, endnodes=3, input_noise=100)
Que nos crea el generador:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_transpose (Conv2DTra (None, 5, 5, 128) 409600
nspose)
conv2d_transpose_1 (Conv2DT (None, 10, 10, 128) 262272
ranspose)
batch_normalization (BatchN (None, 10, 10, 128) 512
ormalization)
conv2d_transpose_2 (Conv2DT (None, 20, 20, 128) 262272
ranspose)
batch_normalization_1 (Batc (None, 20, 20, 128) 512
hNormalization)
conv2d_transpose_3 (Conv2DT (None, 40, 40, 128) 262272
ranspose)
batch_normalization_2 (Batc (None, 40, 40, 128) 512
hNormalization)
conv2d_transpose_4 (Conv2DT (None, 80, 80, 3) 6147
ranspose)
=================================================================
Total params: 1,204,099
Trainable params: 1,203,331
Non-trainable params: 768
Como se puede ver vamos evolucionando desde el 5 x 5 iniciales hasta el 80 x 80 necesarios. El número de nodos lo mantengo estable en todas las capas, pero podríamos haber indicado más nodos para la primera capa y reducirlos a medida que avanzáramos por el upsample. Para hacer la reducción tan solo tendríamos que haber indicado un valor diferente a 1 en el parámetro multnodes. Para reducirlos a la mitad en cada upsample se debería indicar el valor 0.5.
Crear el Discriminador de la GAN.
def adapt_discriminator(nodes, downsamples, multnodes = 1.0, in_shape=[32, 32, 3]):
#nodes: nodes in the first Dense layers.
#downsamples: number of downsamples bucles.
#multnodes: a multiplicator to modify the nodes in each downsample bucle.
#in_shape: Shape of the input image.
model = keras.models.Sequential()
#input layer % first downsample
model.add(keras.layers.Conv2D(nodes, kernel_size=5, strides=2, padding="SAME",
activation=keras.layers.LeakyReLU(0.2),
input_shape=in_shape))
model.add(keras.layers.Dropout(0.4))
#creating downsamples
nodeslayers = nodes
for i in range(downsamples - 1):
nodeslayers = int(nodeslayers * multnodes)
model.add(keras.layers.Conv2D(nodeslayers, kernel_size=3, strides=2, padding="SAME",
activation=keras.layers.LeakyReLU(0.2)))
model.add(keras.layers.Dropout(0.4))
#ending model
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(1, activation="sigmoid"))
return model
Para crear el discriminador también vamos a usar una función que nos permite ir generando diferentes discriminadores, y que ya hemos usado en el artículo anterior.
El discriminador necesita una primera capa capaz de recibir una imagen, en este caso de 80 x 80 x 3. En la última capa va a generar una salida binaria indicando si la imagen es falsa o verdadera.
En el Discriminador también se siguen algunas de las recomendaciones publicadas en las GAN Hacks.
- El uso del activador LeakyReLU.
- El uso de capas de Dropout.
El uso de las capas de Dropout es muy importante, impide que el discriminador se vuelva inteligente demasiado pronto e impida al generador empezar a generar imágenes capaces de engañarlo.
La llamada para crear el discriminador es:
model_D = adapt_discriminator(128, 5, multnodes=1, in_shape=shape)
Nos crea el discriminador:
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 40, 40, 128) 9728
dropout (Dropout) (None, 40, 40, 128) 0
conv2d_1 (Conv2D) (None, 20, 20, 128) 147584
dropout_1 (Dropout) (None, 20, 20, 128) 0
conv2d_2 (Conv2D) (None, 10, 10, 128) 147584
dropout_2 (Dropout) (None, 10, 10, 128) 0
conv2d_3 (Conv2D) (None, 5, 5, 128) 147584
dropout_3 (Dropout) (None, 5, 5, 128) 0
conv2d_4 (Conv2D) (None, 3, 3, 128) 147584
dropout_4 (Dropout) (None, 3, 3, 128) 0
flatten (Flatten) (None, 1152) 0
dense (Dense) (None, 1) 1153
=================================================================
Total params: 601,217
Trainable params: 601,217
Non-trainable params: 0
Al igual que en el Generador los nodos se mantienen entre capas. Es una práctica común aumentarlos a medida que se reduce el tamaño de la imagen. Si quisiéramos hacerlo tan solo hay que modificar el valor del parámetro multnodes. Para duplicarlos se tendría que indicar un 2.
Veamos el código completo de la creación de los dos modelos:
# Settings
resize = 80
shape = (resize, resize, 3)
# Build the GAN
with strategy.scope():
# create the generator model
model_G = adapt_generator(5, nodes=128, upsamplings=4, multnodes=1, endnodes=3, input_noise=100)
# create the discriminator model
model_D = adapt_discriminator(128, 5, multnodes=1, in_shape=shape)
# print summaries
model_G.summary()
model_D.summary()
# set optimizers
param_G = tf.keras.optimizers.Adam(learning_rate=0.0002, beta_1=0.5)
param_D = tf.keras.optimizers.Adam(learning_rate=0.0002, beta_1=0.5)
Lo primero que hacemos es indicarle a TensorFlow que vamos a utilizar la estrategia distribuida. Dentro de ese ámbito crearemos el modelo y también cualquier elemento que sea necesario, como los optimizadores.
Dentro del ámbito estamos llamando a las funciones que crean el Generador y el Discriminador que ya hemos visto antes.
Para acabar creamos dos activadores. Atención, aunque el activador sea exactamente el mismo, se deben crear dos variables distintas, una para el generador y otra para el discriminador. No podemos usar la misma variable para los dos modelos. Si lo hacemos nos dará un error en TensorFlow 2.11 o superior y en versiones más antiguas funcionará, pero seguramente la GAN perderá eficiencia.
Entrenar la GAN.
Vamos a utilizar una función train_on_batch personalizada. Hay que tener en cuenta que esta función se va a ejecutar de forma paralela en diferentes TPU’s y que al finalizar vamos a tener que juntar los valores que retorne. Si no tenemos en cuenta esta característica, la función será muy parecida a la utilizada en los dos artículos anteriores.
Primero una parte para entrenar al discriminador:
# PHASE ONE - train the discriminator
with tf.GradientTape() as d_tape:
# create noise input
z = tf.random.normal(shape=(real_img.shape[0], 1, 1, z_dim))
# generate fake images
fake_img = model_G(z)
# feed the fake images to the discriminator
fake_out = model_D(fake_img)
# feed the real images to the discriminator
real_out = model_D(real_img)
# use the loss function to measure how well the discriminator
# labels fake or real images
d_fake_loss = loss_func(tf.zeros_like(fake_out), fake_out)
d_real_loss = loss_func(tf.ones_like(real_out), real_out)
# get the total loss
d_loss = (d_fake_loss + d_real_loss)
d_loss = tf.reduce_sum(d_loss) / (batch_size * 2)
# get the gradients
gradients = d_tape.gradient(d_loss, model_D.trainable_variables)
# update the weights of the discriminator
param_D.apply_gradients(zip(gradients, model_D.trainable_variables))
Vemos que creamos un contexto con tf.GradientType, con esto indicamos que todas las operaciones realizadas dentro del contexto se registran y sirven para poder calcular los gradientes de una variable de salida, en nuestro caso de d_loss. Es decir, la pérdida del discriminador. Que recuperamos en la línea:
# get the gradients
gradients = d_tape.gradient(d_loss, model_D.trainable_variables)
Lo que nos servirá para poder actualizar los pesos del discriminador, al aplicar posteriormente los gradientes:
# update the weights of the discriminator
param_D.apply_gradients(zip(gradients, model_D.trainable_variables))
Como primer paso, dentro del contexto, se crea el ruido y con el ruido generado se llama al Generador que se encargará de producir imágenes a partir del ruido.
# create noise input
z = tf.random.normal(shape=(real_img.shape[0], 1, 1, z_dim))
# generate fake images
fake_img = model_G(z)
Estas imágenes se pasan al discriminador junto a imágenes reales del Dataset y se usa la función de Loss para medir lo bien que identifica las imágenes.
# feed the fake images to the discriminator
fake_out = model_D(fake_img)
# feed the real images to the discriminator
real_out = model_D(real_img)
# use the loss function to measure how well the discriminator
# labels fake or real images
d_fake_loss = loss_func(tf.zeros_like(fake_out), fake_out)
d_real_loss = loss_func(tf.ones_like(real_out), real_out)
# get the total loss
d_loss = (d_fake_loss + d_real_loss)
d_loss = tf.reduce_sum(d_loss) / (batch_size * 2)
El d_loss calculado es el que hemos usaremos para calcular los gradientes a usar para modificar los pesos del discriminador y entrenarlo.
En el segundo bloque de la función pasamos a entrenar el Generador:
# PHASE TWO - train the generator
with tf.GradientTape() as g_tape:
# create noise input
z = tf.random.normal(shape=(real_img.shape[0], 1, 1, z_dim))
# generate fake images
fake_img = model_G(z)
# feed fake images to the discriminator
fake_out = model_D(fake_img)
# use loss function to measure how well the generator
# is able to trick the discriminator (i.e. model_D should output 1's)
g_loss = loss_func(tf.ones_like(fake_out), fake_out)
g_loss = tf.reduce_sum(g_loss) / (batch_size * 2)
# get the gradients
gradients = g_tape.gradient(g_loss, model_G.trainable_variables)
# update the weights of the generator
param_G.apply_gradients(zip(gradients, model_G.trainable_variables))
Como se puede ver que el funcionamiento es muy parecido, a la sección donde se entrena el discriminador. También lo ejecutamos dentro de un contexto que nos permite calcular los gradientes a usar para modificar los pesos del Generador.
Primero se generan unas imágenes usando ruido, y se las pasamos al Discriminador. Pero esta vez con una etiqueta de imagen verdadera, es decir, como si fueran imágenes pertenecientes al Dataset.
Con esto calculamos el loss con la función de pérdida, con este loss calculamos los gradientes, y con ellos actualizamos el peso del modelo.
Veamos ahora el código completo.
@distributed(Reduction.SUM, Reduction.SUM, Reduction.CONCAT)
def train_on_batch(real_img1, real_img2):
'''trains the GAN on a given batch'''
# concatenate the real image inputs
real_img = tf.concat([real_img1, real_img2], axis=0)
# PHASE ONE - train the discriminator
with tf.GradientTape() as d_tape:
# create noise input
z = tf.random.normal(shape=(real_img.shape[0], 1, 1, z_dim))
# generate fake images
fake_img = model_G(z)
# feed the fake images to the discriminator
fake_out = model_D(fake_img)
# feed the real images to the discriminator
real_out = model_D(real_img)
# use the loss function to measure how well the discriminator
# labels fake or real images
d_fake_loss = loss_func(tf.zeros_like(fake_out), fake_out)
d_real_loss = loss_func(tf.ones_like(real_out), real_out)
# get the total loss
d_loss = (d_fake_loss + d_real_loss)
d_loss = tf.reduce_sum(d_loss) / (batch_size * 2)
# get the gradients
gradients = d_tape.gradient(d_loss, model_D.trainable_variables)
# update the weights of the discriminator
param_D.apply_gradients(zip(gradients, model_D.trainable_variables))
# PHASE TWO - train the generator
with tf.GradientTape() as g_tape:
# create noise input
z = tf.random.normal(shape=(real_img.shape[0], 1, 1, z_dim))
# generate fake images
fake_img = model_G(z)
# feed fake images to the discriminator
fake_out = model_D(fake_img)
# use loss function to measure how well the generator
# is able to trick the discriminator (i.e. model_D should output 1's)
g_loss = loss_func(tf.ones_like(fake_out), fake_out)
g_loss = tf.reduce_sum(g_loss) / (batch_size * 2)
# get the gradients
gradients = g_tape.gradient(g_loss, model_G.trainable_variables)
# update the weights of the generator
param_G.apply_gradients(zip(gradients, model_G.trainable_variables))
# return the losses and fake images for monitoring
return d_loss, g_loss, fake_img
Como se puede ver tenemos los dos bloques de entrenamiento, y devolvemos la pérdida del Discriminador, la pérdida del Generador y las últimas imágenes falsas generada, que hemos usado para entrenar al Generador.
Como hemos dicho, esta función se va a ejecutar en diferentes TPUs de forma paralela, y se tiene que encontrar una forma de concatenar los resultados que nos devuelven las diferentes instancias de la función, como si fueran devueltas por una sola función.
De esto se encarga la función @distributed con la que hemos decorado nuestra función train_on_batch. Vamos a verla:
class Reduction(Enum):
SUM = 0
CONCAT = 1
#This decorated function indicates how to concatenate the values
#returned by all the functions working in the different distributed
#TPU's.
#We have two possibilites. return a reducted SUM of each process, or
# a concatenation.
def distributed(*reduction_flags):
def _decorator(fun):
def per_replica_reduction(z, flag):
if flag == Reduction.SUM:
return strategy.reduce(tf.distribute.ReduceOp.SUM, z, axis=None)
elif flag == Reduction.CONCAT:
z_list = strategy.experimental_local_results(z)
return tf.concat(z_list, axis=0)
else:
raise NotImplementedError()
@tf.function
def _decorated_fun(*args, **kwargs):
fun_result = strategy.run(fun, args=args, kwargs=kwargs)
assert type(fun_result) is tuple
return tuple((per_replica_reduction(fr, rf) for fr, rf in zip(fun_result, reduction_flags)))
return _decorated_fun
return _decorator
La función recibe una lista de reductio_flags, que no es nada más que unas constantes que hemos definido en Reduction, que le indican como debe actuar con los valores a retornar. Por ahora tan solo tenemos dos posibilidades, realizar una Suma con reducción o Concatenar.
Nuestra función train_on_batch, devuelve tres elementos y, por lo tanto, al realizar la llamada al decorador le tenemos que indicar como queremos que sea tratado cada uno de los elementos.
@distributed(Reduction.SUM, Reduction.SUM, Reduction.CONCAT) def train_on_batch(real_img1, real_img2): ...... ...... ...... # return the losses and fake images for monitoring return d_loss, g_loss, fake_img
La función train_on_batch retorna tres parámetros. En la llamada a @distributed le estamos indicamos a los dos primeros parámetros se les aplique la Suma, mientras que al tercero se le aplique una concatenación. Cosa que tiene toda la lógica del mundo porque los dos primeros son numéricos que contienen la pérdida del discriminador y el generador, mientras que el tercero es una lista de las imágenes generadas.
Todo el código está disponible en un Notebook en Google Colab: https://colab.research.google.com/drive/1p6sQqiu4kWeDpxu91C0MQBX9P6qSwmPG#scrollTo=snusiGSBtrlU
El bucle de entreno.
Ahora tan solo nos queda ir llamando a la función train_on_batch tantas veces como épocas queramos ejecutar para entrenar la GAN.
NUM_EPOCHS = 100
# generate a batch of noisy input
z_dim = 128
test_z = tf.random.normal(shape=(64, 1, 1, z_dim))
# start loop
tf.keras.backend.clear_session()
for epoch in range(NUM_EPOCHS):
with tqdm(dataset) as pbar:
pbar.set_description(f"[Epoch {epoch}]")
for step, (X1, X2) in enumerate(pbar):
# train on the current batch
d_loss, g_loss, fake = train_on_batch(X1, X2)
# generate fake images
fake_img = model_G(test_z)
# save face generated to file.
if not os.path.exists(out_dir):
os.makedirs(out_dir)
file_path = out_dir+f"/epoch_{epoch:04}.png"
# display gallery of generated faces
if epoch % 10 == 0:
plot_results(fake_img.numpy()[:4], 2, save_path=file_path)
Después de cada llamada a train_on_batch llamamos al Generador para que genere algunas imágenes y podamos ver cómo va avanzando. Para ello no tan solo las mostramos por pantalla, sino que también las guardamos en disco.

Con las imágenes guardadas en disco se puede crear este GIF, que muestra el proceso de mejora en la creación de las caras.
¿Qué hemos aprendido?
Lo más importante es que hemos visto como trabajar de forma distribuida. Ahora lo hemos utilizado para entrenar una GAN usando TPUs. Pero si quisiéramos entrenar cualquier otro modelo con múltiples GPUs en lugar de TPUs el código no variaría demasiado.
Hemos visto que se debe crear una estrategia, instanciar la TPU, y tener en cuenta que los retornos de las funciones que se ejecutan en paralelo deben tratarse de tal forma que se fusionen como si proveyeran de una sola función.
Por lo que respecta a GANs hemos usado un Dataset mucho más completo que los usados en los artículos anteriores, y, por lo tanto, hemos adaptado la estructura del Generador y el Discriminador, usando las funciones que ya creamos en el artículo anterior.
¡Continuamos!
Espero que os haya gustado el artículo. Ha sido laborioso de hacer y me ha quedado más largo de lo que quería en un principio.
Está claro que no está 100% basado en GANs, pero el uso de TPUs o procesamiento paralelo para acelerar el entreno es muy necesario en GANs, ya que suelen requerir de muchos recursos y tiempo.
¡En el próximo artículo volvemos a las GAN! Mientras tanto podéis probar con diferentes estructuras en el Generado y el Discriminador, o incluso aumentar la resolución de las imágenes de salida.
También puede ser un buen ejercicio transformar el Notebook para que funcione con GPUs, sin procesamiento paralelo, cosa muy sencilla, y comprobar la diferencia de rendimiento.