
En el primer post de preparar la certificación de TensorFlow Developer, vimos el notebook preparado para solucionar un problema de clasificación de imágenes multiples usando el dataset Fashion MNIST que viene con Tensorflow.
En el notebook actual voy a usar un Dataset muy conocido, el de gatos y perros de Microsoft, opara solucionar un problema de clasificación binaria. El Dataset muy diferente al usado en el notebook anterior. No tan solo por el tamaño de las imágenes. Este debe descargarse un fichero .zip, descomprirlo en el disco y cargar las imagines usando un ImageDataGenerator. Una técnica que no se vio en el ejemplo anterior.
Puntos cubiertos del examen TensorFlow Developer en el notebook.
(2) Building and training neural network models using TensorFlow 2.x
❏ Build, compile and train machine learning (ML) models using TensorFlow.
❏ Preprocess data to get it ready for use in a model.
❏ Use models to predict results.
❏ Build sequential models with multiple layers.
❏ Build and train models for binary classification.
❏ Build and train models for multi-class categorization.
❏ Plot loss and accuracy of a trained model.
❏ Identify strategies to prevent overfitting, including augmentation and dropout.
❏ Use pretrained models (transfer learning).
❏ Extract features from pre-trained models.
❏ Ensure that inputs to a model are in the correct shape.
❏ Ensure that you can match test data to the input shape of a neural network.
❏ Ensure you can match output data of a neural network to specified input shape for test data.
❏ Understand batch loading of data.
❏ Use callbacks to trigger the end of training cycles.
❏ Use datasets from different sources.
❏ Use datasets in different formats, including json and csv.
❏ Use datasets from tf.data.datasets.
(3) Image classification
❏ Define Convolutional neural networks with Conv2D and pooling layers.
❏ Build and train models to process real-world image datasets.
❏ Understand how to use convolutions to improve your neural network.
❏ Use real-world images in different shapes and sizes..
❏ Use image augmentation to prevent overfitting.
❏ Use ImageDataGenerator.
❏ Understand how ImageDataGenerator labels images based on the directory structure.
He intentado cubrir todas las marcadas en amarillo en el Notebook IMAGERecog.ipynb disponible en el repositorio de GitHub donde están todos los notebooks preparados para el examen de TensorFlow Developer.
Contenido y estructura del notebook.
El notebook esta dividido en diferentes secciones. Primero se cargan las librerías necesarias y los datos. Se crea la estructura. Después se definen funciones genéricas, los modelos. A partir de aquí se hace el aprendizaje de los diferentes modelos, con y sin data augmentation. En el ultimo apartado se usan dos procesos diferentes de Transfer Learning, usando los modelos prentrenados InceptionV3 y VGG16.
Importar librerías y datos.
#First steep is import the libraries.
import tensorflow as tf
tf.random.set_seed(42)
#Numpy is a lybrary that allow us to work with arrays.
import numpy as np
#keras is an open source neural networks lybrary writted in python that run's in varios frameworks, TensorFlow included.
from tensorflow import keras
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.optimizers import RMSprop
from tensorflow.keras.optimizers import Adam
print (tf.__version__)
gEpochs=30
Se importan las típicas librerías, se define una semilla para que los datos se repartan siempre igual en todas las ejecuciones. Importo dos optimizadores, por que he realizado pruebas con ambos, aunque me gusta más cómo funciona Adam.
Se importa ImageDataGenerator que se utiliza para trabajar con el Dataset.
#obtain the data from microsoft.com #the same dataset is available in kaggle but with a different organization #https://www.kaggle.com/competitions/dogs-vs-cats/data #If it dosn't run be sure to have wget installed in your local machine. It works fine in Colab. !wget --no-check-certificate \ https://download.microsoft.com/download/3/E/1/3E1C3F21-ECDB-4869-8368-6DEBA77B919F/kagglecatsanddogs_5340.zip \-O /tmp/catsvsdogs.zip
Obtenemos el fichero .zip. Hay que recalcar que el código funciona tanto en Google Colab como en un notebook Jupyter en el disco local. Nos deja el fichero .zip en el directorio /tmp/
#unzip the data
import zipfile
cvr_zip_file = '/tmp/catsvsdogs.zip'
zipmem = zipfile.ZipFile(cvr_zip_file)
zipmem.extractall('/tmp/catsvsdogs')
zipmem.close()
Para descomprimirlo importamos zipfile, y no hay ningún secreto. el zip viene con las imagenes en dos directorios:
dira="/tmp/catsvsdogs/PetImages/Cat/" dirb="/tmp/catsvsdogs/PetImages/Dog/"
Tendremos que pasarlo de estos dos directorios a otros para tener datos de entreno y datos de validación.
destDirTraina='/tmp/datacvd/train/cats/' destDirTrainb='/tmp/datacvd/train/dogs/' destDirVala='/tmp/datacvd/validation/cats/' destDirValb='/tmp/datacvd/validation/dogs/' dirTrain='/tmp/datacvd/train/' dirVal='/tmp/datacvd/validation/'
La estructura de directorios se debe crear en el disco, ya sea en el que nos monta de forma temporal Colab, como en el nuestro.
#create the directory structure
import os
#we need a try block, because it fails when the directories already exist.
try:
os.mkdir('/tmp/datacvd')
os.mkdir('/tmp/datacvd/train')
os.mkdir('/tmp/datacvd/validation')
os.mkdir('/tmp/datacvd/train/cats')
os.mkdir('/tmp/datacvd/train/dogs')
os.mkdir('/tmp/datacvd/validation/cats')
os.mkdir('/tmp/datacvd/validation/dogs')
except:
pass
La función mkdir devuelve una excepción en caso de que el directorio ya esté creado, por eso lo he puesto dentro de un bloque try y he ignorado la excepción.
Con los directorios ya creados podemos copiar las imágenes, para ello tengo una función que recibe los directorios origen, los destino y el número de imágenes que quiero usar como validadoras.
#we need 4 datasets, two for training the model and two for validate or test the model.
#to classify the images in this dataset we can move it from their original directories to
#a new ones with the correct structure.
def getimagesfromdir(dira="", dirb="", destDirTraina="", destDirTrainb="", destDirVala="", destDirValb="", NumVal=100):
from shutil import copyfile
#this array contents all the images to move/copy
imagesA=[]
imagesB=[]
for imagename in os.listdir(dira):
imageCat = dira + imagename
if (os.path.getsize(imageCat)) > 0:
imagesA.append(imagename)
for imagename in os.listdir(dirb):
imageDog = dirb + imagename
if (os.path.getsize(imageDog)) > 0:
imagesB.append(imagename)
counterImage = 0
for imagename in imagesA:
if counterImage < 2000:
copyfile(dira + imagename, destDirVala+imagename)
else:
copyfile(dira + imagename, destDirTraina+imagename)
counterImage +=1
counterImage = 0
for imagename in imagesB:
if counterImage < 2000:
copyfile(dirb + imagename, destDirValb+imagename)
else:
copyfile(dirb + imagename, destDirTrainb+imagename)
counterImage +=1
print(len(os.listdir(destDirValb)))
print(len(os.listdir(destDirTrainb)))
print(len(os.listdir(destDirVala)))
print(len(os.listdir(destDirTraina)))
return imagesA, imagesB
La llamada a la función es muy sencilla:
imagesCats, imagesDogs = getimagesfromdir(dira=dira,
dirb=dirb,
destDirTraina=destDirTraina,
destDirTrainb=destDirTrainb,
destDirVala=destDirVala,
destDirValb=destDirValb,
NumVal=2000)
La llamada a la función nos devuelve los datos divididos en dos arrays, uno para cada categoría, pero no es lo importante. Lo que realmente ha hecho es dividir las imágenes en los cuatro directorios para poder crear datos de entreno y datos de validación partiendo del directorio en el que se han situado.
Funciones del Notebook.
Son las funciones genéricas, usadas para imprimir gráficos, o tratar los datos. Muchas de ellas compartidas entre diferentes notebooks.
def SimpleDataGenerator():
#TRAIN Dataset
#Normalize the images
train_idg = ImageDataGenerator(rescale=1/255)
train_data = train_idg.flow_from_directory(
'/tmp/datacvd/train',
target_size = (150, 150),
batch_size = 105,
class_mode='binary'
)
#VALIDATION Dataset
val_idg = ImageDataGenerator(rescale=1/255)
val_data = val_idg.flow_from_directory(
'/tmp/datacvd/validation',
target_size = (150, 150),
batch_size = 100,
class_mode='binary'
)
return train_data, val_data
Aquí se preparan los juegos de datos, el de training y el de validation. Usando ImageDataGenerator se normalizan las imágenes. Acto seguido con flow_from_directory se cargan las imágenes. Le podemos indicar el target size, pera que todas tengan el mismo, debe coincidir con el shape de entrada de nuestro modelo.
La función devuelvo los dos juegos de datos.
#Print accuracy & val_accura vs loss & val_loss
def plot_loss_acc(history):
'''Plots the training and validation loss and accuracy from a history object'''
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo-', label='Training accuracy')
plt.plot(epochs, val_acc, 'go-', label='Validation accuracy')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo-', label='Training Loss')
plt.plot(epochs, val_loss, 'go-', label='Validation Loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
Esta función nos crea un gráfico comparando el loss y el accuracy del history de la ejecución del modelo que le pasemos.
Modelos.
def get_model(kindmodel):
switcher = {
#it's a minimal model for images, with just an Convolutionatl layer and a MaxPooling layer
0: tf.keras.models.Sequential([
tf.keras.layers.Conv2D(16, (4,4), activation="relu", input_shape=(150, 150, 3)),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation="relu"),
tf.keras.layers.Dense(1, activation="sigmoid")]),
#keeping it simple just add more convolutional anv maxpooling layers
#es incluso menos pesado que el anterior, gracias a las capas de maxpooling
1: tf.keras.models.Sequential([
tf.keras.layers.Conv2D(16, (4,4), activation="relu", input_shape=(150, 150, 3)),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(32, (4,4), activation="relu"),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(64, (4,4), activation="relu"),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation="relu"),
tf.keras.layers.Dense(1, activation="sigmoid")]),
3: tf.keras.models.Sequential([
tf.keras.layers.Conv2D(16, (4,4), activation="relu", input_shape=(150, 150, 3)),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation="relu"),
tf.keras.layers.Dense(1, activation="sigmoid")]),
4: tf.keras.models.Sequential([
tf.keras.layers.Conv2D(16, (4,4), activation="relu", input_shape=(150, 150, 3)),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Conv2D(32, (4,4), activation="relu"),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Conv2D(64, (4,4), activation="relu"),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation="relu"),
tf.keras.layers.Dense(1, activation="sigmoid")]),
}
return switcher.get(kindmodel, None)
Los modelos los he puesto todos dentro de una función en lugar de irlos creando por el notebook. Me facilita la vida para compararlos, buscarlos o editarlos. como podeís ver hay dos modelos y son todos muy sencillos.
Tenemos un modelo con una sola capa convolucional y después otro con tres capas convolucionales. Cada capa convolutional se acompaña de una capa MaxPooling2D.
Los dos siguientes modelos son exactamente los mismos pero incorporando capas de Dropout detrás de la capa MaxPooling2D.
Modelo con una sola capa convolucional.
tf.keras.models.Sequential([
tf.keras.layers.Conv2D(16, (4,4), activation="relu", input_shape=(150, 150, 3)),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation="relu"),
tf.keras.layers.Dense(1, activation="sigmoid")])
Es un modelo muy simple, tan solo una capa convolucional, una de MaxPooling2D y la capa densa con 128 neurones.
Resultados:
6s 180ms/step – loss: 0.1124 – accuracy: 0.9857 – val_loss: 1.4532 – val_accuracy: 0.8167
84s 418ms/step – loss: 0.3824 – accuracy: 0.8318 – val_loss: 0.3082 – val_accuracy: 0.8762Con Data Augmentation
Como es normal, el modelo tiene un gran problema de overfitting, que se ve solucionado parcialmente al usar Image Augmentation.
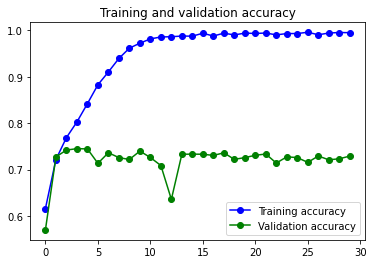
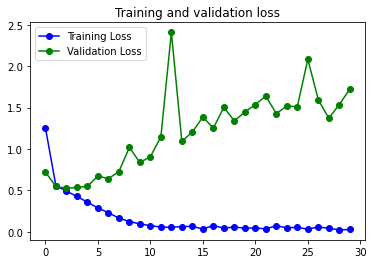
Con Image Augmentation:
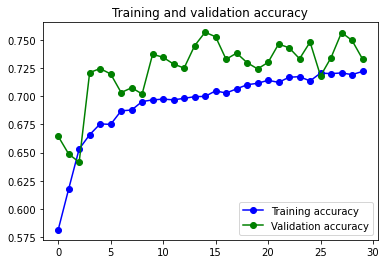
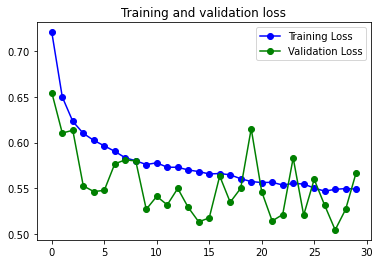
Modelo con tres capas convolucionales.
tf.keras.models.Sequential([
tf.keras.layers.Conv2D(16, (4,4), activation="relu", input_shape=(150, 150, 3)),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(32, (4,4), activation="relu"),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(64, (4,4), activation="relu"),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation="relu"),
tf.keras.layers.Dense(1, activation="sigmoid")])
Este modelo es el típico en el que a cada convolucional le sigue una de MaxPooling2D, y se aumentan los filtros aplicados en cada capa convolucional añadida. Se aumentan también el número de neurones de la capa Densa.
Resultados:
36s 180ms/step – loss: 0.1124 – accuracy: 0.9857 – val_loss: 1.4532 – val_accuracy: 0.8167
84s 418ms/step – loss: 0.3824 – accuracy: 0.8318 – val_loss: 0.3082 – val_accuracy: 0.8762Con Data augmentation
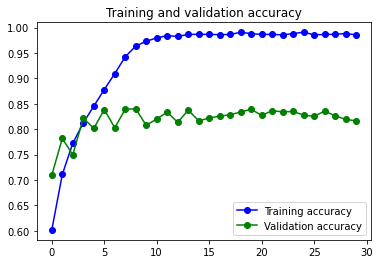
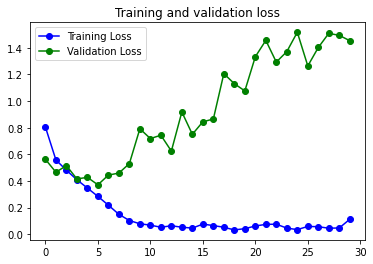
Con Image Augmentation:
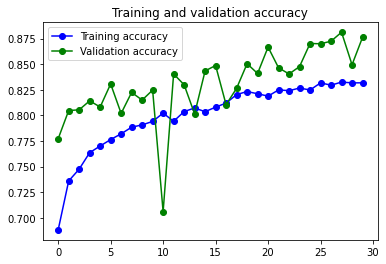
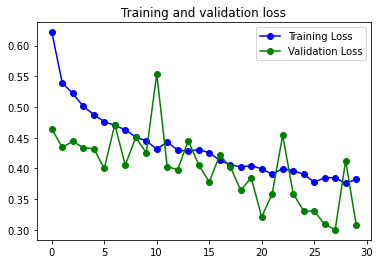
Mejora los números del modelo simple, pero mantiene exactamente el mismo problema de Overfitting y reacciona igual a la solución de usar Data Augmentation.
En los dos modelos se aprecia una irregularidad en la curva de Loss. Una posible causa es el Learning Rate usado para el optimizador RMSprop que se ha usado. Se podría crear una función para identificar que learning rate puede ser mejor y usar el optimizador Adam para ver si se consigue una curva con menos estridencias.
Con tres capas convolucionales y Dropout.
tf.keras.models.Sequential([
tf.keras.layers.Conv2D(16, (4,4), activation="relu", input_shape=(150, 150, 3)),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Conv2D(32, (4,4), activation="relu"),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Conv2D(64, (4,4), activation="relu"),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation="relu"),
tf.keras.layers.Dense(1, activation="sigmoid")])
Se incorpora una capa de Dropout déspues de cada capa de MaxPooling2D.
Resultados:
85s 423ms/step – loss: 0.3076 – accuracy: 0.8639 – val_loss: 0.3255 – val_accuracy: 0.8672Con Image Augmentation.
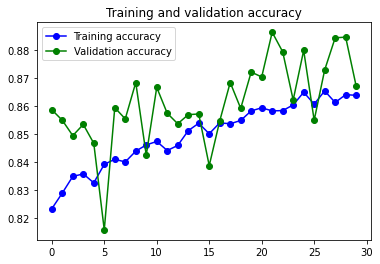
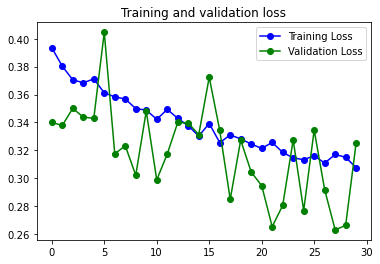
Solo he realizado entrenos con Data Augmentation. No se aprecia overfitting, pero la curva continua teniendo unos picos que tendrían que eliminarse, o reducirse.
Transfer Learning.
He usado dos modelos preentrenados diferentes InceptionV3 y VGG16. He usado dos técnicas diferentes para bajarme los pesos y crear el modelo.
Con Transfer Learning lo que se hace es aprovechar modelos existentes que ya están entrenados. Se puede seleccionar el modelo completo, o tan solo las capas que queramos del modelo. Después se complementa con nuestras capas finales, y entrenamos tan solo las capas que hemos incorporado. Con esto no se aprovecha tan solo la forma del modelo, que ya es mucho, sino que también aprovechamos el esfuerzo de entreno, tanto en horas como en datos que se ha realizado con el modelo pre entrenado.
Transfer Learning con InceptionV3
from tensorflow.keras import Model
# Download the pre-trained weights. No top means it excludes the fully connected layer it uses for classification.
!wget --no-check-certificate \
https://storage.googleapis.com/mledu-datasets/inception_v3_weights_tf_dim_ordering_tf_kernels_notop.h5 \
-O /tmp/inception_v3_weights_tf_dim_ordering_tf_kernels_notop.h5
Importamos Model de Keras, para crear el modelo. Nos bajamos los pesos del modelo, parta cargarlos al crear el modelo.
#conver layers in non trainable.
def notrainlayers(model):
for layer in model.layers:
layer.trainable=False
return model
Esta función nos permite marcar cómo no entrenables las capas del modelo que reciba. Al bajarnos un modelo pre entrenado, con sus pesos correspondientes no queremos volver a entrenar el modelo. Para ello marcamos las capas como entrenables.
#import Inceptionv3.
from tensorflow.keras.applications.inception_v3 import InceptionV3
#create the model.
inception_pre_trained=InceptionV3(input_shape=(150, 150, 3),
include_top=False,
weights=None)
#store name of the file in a variable.
local_weigth_file = '/tmp/inception_v3_weights_tf_dim_ordering_tf_kernels_notop.h5'
#load the weights, obtained downloading
inception_pre_trained.load_weights(local_weigth_file)
El modelo InceptionV3 esta precargado en la libreria keras, por lo que lo importamos directamente.
Al crear el modelo con InceptionV3 le pasamos tres parametros:
- El input shape. Que debe coincidir con la forma de los elementos de nuestro dataset.
- Include_top = False para indicar que no queremos el clasificador del modelo, que usaremos el nuestro.
- weigths=None. como hemos recuperado los pesos y los hemos guardado en un fichero local le indicamos que no queremos que los cargue.
Finalmente cargamos los pesos desde el fichero que hemos guardado.
================================================================================================== Total params: 21,802,784 Trainable params: 21,768,352 Non-trainable params: 34,432
Al consultar el summary del modelo, al final podemos ver que tenemos casi 22 millones de parámetros entrenables. Esto cambiará porque primero, vamos a marcarlas como no entrenables, y tamboen eliminaremos algunas.
inception_pre_trained = notrainlayers(inception_pre_trained)
Para marcar las capas del modelo como no entrenables tan solo tenemos que pasarlo a la función que hemos creado antes, que tan solo contiene un bucle que pasa por todas las capas del modelo que recibe y las marca como entrenables.
Si después de llamar a la función llamamos al Summary del modelo veremos como los parametroa ahora son no entrenables.
================================================================================================== Total params: 21,802,784 Trainable params: 0 Non-trainable params: 21,802,784
El modelo tiene una cantidad de capas inmensa, en el summary nos indica todas y podemos seleccionar una para realizar un corte. Ee decir quedarnos con esa capa y todas las previas.
..............
batch_normalization_257 (Batch (None, 7, 7, 192) 576 ['conv2d_289[0][0]']
Normalization)
activation_248 (Activation) (None, 7, 7, 192) 0 ['batch_normalization_248[0][0]']
activation_251 (Activation) (None, 7, 7, 192) 0 ['batch_normalization_251[0][0]']
activation_256 (Activation) (None, 7, 7, 192) 0 ['batch_normalization_256[0][0]']
activation_257 (Activation) (None, 7, 7, 192) 0 ['batch_normalization_257[0][0]']
mixed7 (Concatenate) (None, 7, 7, 768) 0 ['activation_248[0][0]',
'activation_251[0][0]',
'activation_256[0][0]',
'activation_257[0][0]']
...............
En este pequeña porción del modelo podemos ver la capa mixed7, que es la seleccionada como última capa que nos interesa.
#select the last layer we want from the pretrained model
last_layer = inception_pre_trained.get_layer('mixed7')
last_output = last_layer.output
Seleccionamos la última capa que queremos, la guardamos en last_layer. Acto seguido se usa para obtener el output del modelo a partir de esa ultima capa. Ese output lo vamos a usa para continuar añadiendo capas al modelo.
#Flatten the output layer to 1 dimension flayers = tf.keras.layers.Flatten()(last_output) #add a fullly connected layer woth 512 neurons the samen that with the others models. flayers = tf.keras.layers.Dense(512, activation='relu')(flayers) #add a final sigmoid layer for binary classification flayers = tf.keras.layers.Dense(1, activation='sigmoid')(flayers) #append the final layers to the pretrained layer and create a new model modelf = Model(inception_pre_trained.input, flayers)
Las layers las voy a ir almacenando en la variable flayers primero le pongo una capa de flatten, y fijaros que le añado (last_output) donde tengo el contenido del modelo anterior hasta la capa que he seleccionado como capa final.
Despues le incorporo una capa Densa y acto seguido el clasificador. Quizas podria haber puesto alguna capa de Dropout, usar mas neurones, pero he preferido mantenerlo simple y con la misma estructura final de los modelos usados en el notebook.
Finalmente con Model, creo el modelo nuevo que ya contiene tanto la parte del modelo preentrenado que nos interesa como las capas que acabamos de incoporar.
Ahora al consultar el summary del modelo acabado de crear podemos ver que ya tenemos parámetros entrenables.
........
mixed7 (Concatenate) (None, 7, 7, 768) 0 ['activation_248[0][0]',
'activation_251[0][0]',
'activation_256[0][0]',
'activation_257[0][0]']
flatten_20 (Flatten) (None, 37632) 0 ['mixed7[0][0]']
dense_36 (Dense) (None, 512) 19268096 ['flatten_20[0][0]']
dense_37 (Dense) (None, 1) 513 ['dense_36[0][0]']
==================================================================================================
Total params: 28,243,873
Trainable params: 19,268,609
Non-trainable params: 8,975,264
También se puede ver cómo el modelo finaliza con la capa mixed7 y las capas que le he incorporado.
modelf.compile(loss="binary_crossentropy",
optimizer='Adam',
metrics=['accuracy'])
historyF = modelf.fit(
train_data,
validation_data = val_data,
epochs=gEpochs,
steps_per_epoch=len(train_data),
validation_steps=len(val_data),
verbose=1)
El modelo lo he compilado con el Optimizador Adam y la función de perdida binary_crossentropy.
87s 436ms/step - loss: 0.0649 - accuracy: 0.9752 - val_loss: 0.0831 - val_accuracy: 0.9690
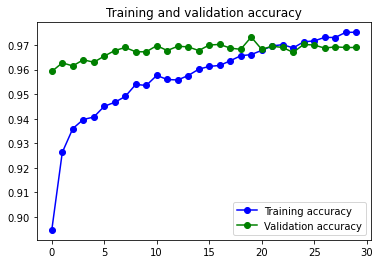
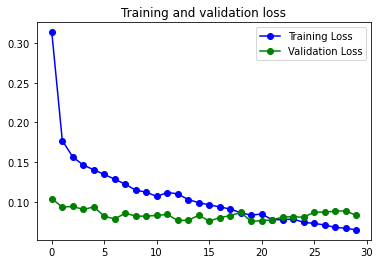
El resultado realmente es bastante bueno y no se aprecia overfitting, quizás porque lo he entrenado con los datos que han pasado por el proceso de Image Augmentation.
Transfer learning desde el modelo VGG16.
from keras.applications.vgg16 import VGG16
#https://storage.googleapis.com/tensorflow/keras-applications/vgg16/vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5
VGG16_pre_trained = VGG16(input_shape=(150, 150, 3),
include_top=False,
weights='imagenet')
También se trata de un modelo que ya esta en la librería keras, por el que el proceso de importación es el mismo. Pero en este caso no me descargo los datos, sino que le indico en la creación del modelo que los obtenga de imagenet. Es un standard de facto en los modelos de reconocimiento de imagenes. En este caso se podrián dejar las cpas como entrenables para que adaptaran su peso, pero no considero que sea necesario., por lo que igual que en el caso anterior las marcare como no entrenables.
VGG16_pre_trained = notrainlayers(VGG16_pre_trained) modelVGG = tf.keras.models.Sequential() modelVGG.add(VGG16_pre_trained) #Flatten the output layer to 1 dimension modelVGG.add(tf.keras.layers.Flatten()) #add a fullly connected layer woth 512 neurons the samen that with the others models. modelVGG.add(tf.keras.layers.Dense(512, activation='relu')) #add a final sigmoid layer for binary classification #flayersV = tf.keras.layers.Dense(1, activation='sigmoid')(flayers) modelVGG.add(tf.keras.layers.Dense(1, activation='sigmoid')) modelVGG.summary()
La forma de incorporar las capas también es diferente. He creado un modelo secuencial y he añadido el modelo pre entrenado, a partir de aquí se incorporan las capas como si se tratará de un modelo normal y corriente.
Model: "sequential_17"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
vgg16 (Functional) (None, 4, 4, 512) 14714688
flatten_32 (Flatten) (None, 8192) 0
dense_54 (Dense) (None, 512) 4194816
dense_55 (Dense) (None, 1) 513
=================================================================
Total params: 18,910,017
Trainable params: 4,195,329
Non-trainable params: 14,714,688
Como se puede ver la mayoría de parámetros no son entrenables.
174s 870ms/step - loss: 0.2018 - accuracy: 0.9140 - val_loss: 0.2243 - val_accuracy: 0.9052
El modelo funciona bastante bien, pero no tanto como el InceptionV3.
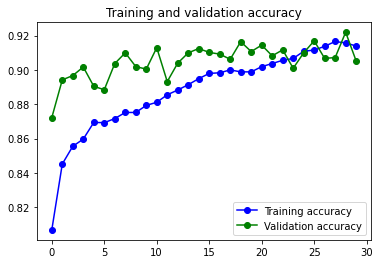
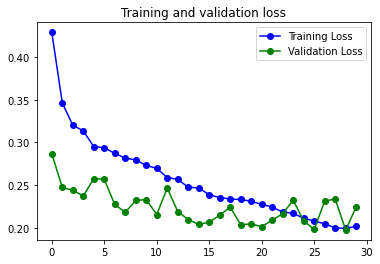
Resumen de lo visto por ahora.
Creo que con este segundo notebook queda cubierto el tema de clasificación de imágenes.
- He utilizado un dataset desde disco, en lugar de uno obtenido desde Tensorflow.
- Era un sistema de clasificación binario, en lugar de varias categorías.
- Hay dos ejemplos de cómo usar Transfer learning.
Dejo aquí el articulo anterior y creo que ya se puede cerrar el tema de redes convolucionales y clasificación de imágenes.
El siguiente noteboook será sobre Natural Language Processing. Mas concretamente la parte de análisis del sentimiento usando supervised learning.
Comments