
Pues ya está aquí la segunda entrega de esta serie de Machine Learning, que forma parte del «curso» práctico de IA sin prerrequisitos. Hoy toca un proyecto de Regresión que usamos como excusa para trabajar con los datos y dejarlos preparados para alimentar el modelo. Así que hoy lo que toca es trabajar bastante con pandas, y empezar a quedarnos con la idea de que buena parte del trabajo es decidir cómo modificamos los datos y con cuáles nos quedamos,
Tipo de proyecto: Machine Learning / Supervised Learning / Regresión.
Nuestro problema consistirá en crear un sistema que nos recomiende un precio para coches de segunda mano.
Solucionamos un primer problema de Regresión con Machine Learning.
Lo primero que vemos en el vídeo son los datos. Que como casi siempre los he obtenido de kaggle. Esta vez es un dataset que necesita de algunas modificaciones para poder usarse como entreno de un modelo. Por lo que buena parte del trabajo lo realizaremos con la librería Pandas. https://www.kaggle.com/datasets/datamarket/venta-de-coches
Aunque los datos los he bajado de Kaggle he llegado a ellos a través de Google Dataset Search. Una forma muy sencilla de encontrar datasets en diferentes origines, aunque en un 99% de las veces acabe llegando a Kaggle.
Desde Jupyter y con el entorno de Conda activado lo primero que se hace es cargar los datos con Pandas.
import pandas as pd
cars = pd.read_csv("data/coches-de-segunda-mano-sample.csv")
cars.head()
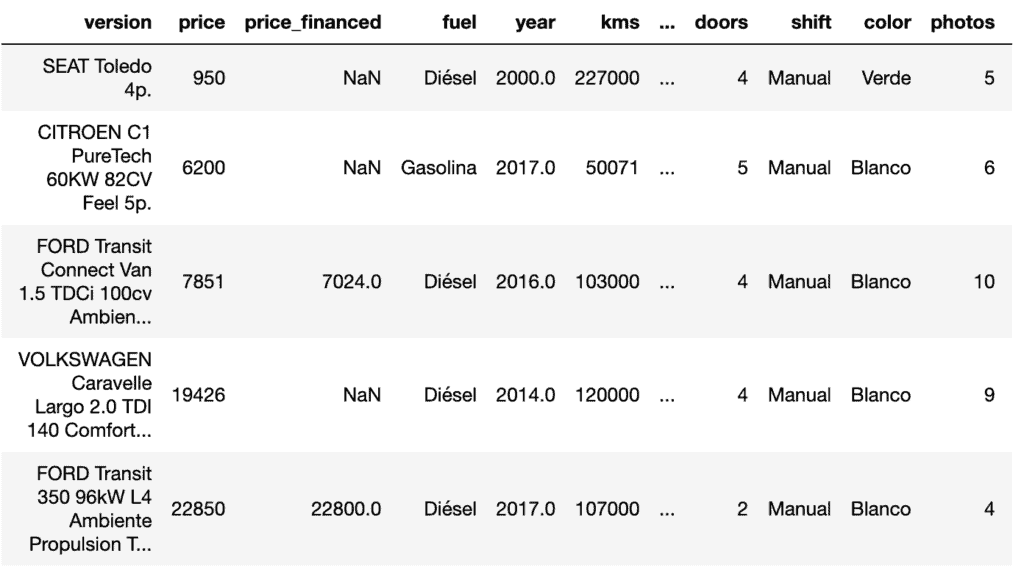
Al ver los registros nos damos cuenta que no aparecen todas las columnas, por el medio tenemos tres puntos suspensivos (…) que indica que hay unas columnas ocultas.
Para que se muestren se modifica la opción max_columns en display con Pandas.
pd.set_option("display.max_columns", 22)
Una de las primeras acciones a realizar es eliminar los valores vacíos. Hay varias opciones para ello.
- Podríamos eliminar la columna entera si no aporta demasiado y tiene muchos valores vacíos.
- Podemos eliminar los registros con valores vacíos, pero entonces hay que tener en cuenta, que campo tienen vacío. Si es un campo poco importante puede ser que sea preferible rellenarlo y no perder campos con un peso más importante en el registro.
- Podemos rellenar los valores vacíos. Ya sea obteniendo valores de registros con las mismas características o calculando una media. En el caso de que los valores no sean numéricos podemos llenarlos con una nueva categoría que indique que es un campo con valor desconocido.
La decisión de qué técnica usar depende de nosotros, de cómo valoremos los datos, y no pocas veces tendremos que dar marcha atrás o probar más de una opción para ver si afecta o no a las predicciones del modelo.
Para encontrar los valores vácios de una forma rápida se hace usando el comando dataset.isna().sum().
cars.isna().sum()
url 0 company 0 make 2 model 5 version 0 price 0 price_financed 26437 fuel 46 year 2
Nos devuelve la lista de columnas indicando cuántos valores vacíos hay en ellas.
En nuestro ejemplo se ha decidido eliminar totalmente la columna price_financed, junto con otras más, ya que no se prevé que tenga ninguna importancia en la predicción de la columna price, y tiene más de un 50% de registros sin valor. Además dejarla podría ser perjudicial, por que seguro que hay una dependencia lineal entre esta columna y price, pero la dirección contraria a la que queremos. Es decir, posiblemente sea una columna dependiente de nuestra columna dependiente.
Para eliminar las columnas se usa la función drops de pandas y se recoge el resultado en un nuevo dataset.
cars_ready = cars.drop(["price_financed", "url", "version"], axis=1) cars_ready
Para la columna power en el vídeo, por cuestión de mantenerlo lo más simple posible, se rellena con la media de la columna. Pero podría sacarse una media de potencia por marca, o buscar por el dataset si hay algún modelo parecido y sustituir la potencia.
cars_ready["power"].fillna(cars_ready["power"].mean(), inplace=True)
Se usa la opción inplace=True, para indicar que queremos modificar el dataframe donde se ejecuta, por lo que no debe recogerse el resultado en un nuevo dataframe.
La columna de color la rellenamos con un valor indicando que no tenía valor.
cars_ready["color"].fillna("desc", inplace=True)
Al rellenarlo con un valor específico conseguimos aislarlo ya que cuando convirtamos los campos de texto en categorías. Se creará una categoría de nombre desc y no tendrá una gran relación con el precio, mas que nada por que los registros que forman parte de ella han sido escogidos al «azar».
Cuando ya se han tratado todos los campos vacíos, llega el momento de ver cómo podemos transformar los campos de texto en categorías. La mayoría de modelos no se llevan bien con los campos de texto y suelen dar error en caso de que les pasemos un campo texto como feature. Para evitarlo tenemos que decidir qué hacer con ellos. Podemos eliminarlos en caso de que no sean útiles, o podemos convertirlos en categorías. Hay varias formas de hacerlo, pero en el ejemplo hemos usado la más sencilla y directa. Hemos usado la función dummies de pandas.
dummies = pd.get_dummies(cars_ready[["make", "model", "fuel", "shift"]]) dummies
Le hemos pasado 4 columnas que queremos convertir en categorías.
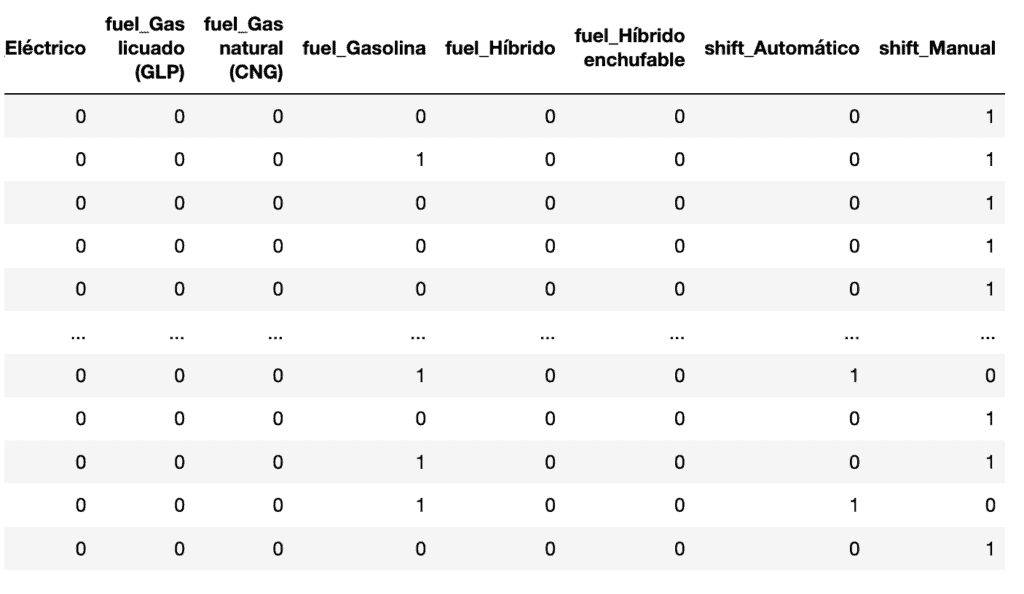
Como podemos ver en la imagen, ha convertido cada uno de los valores en las columnas indicadas en nuevas columnas, indicando con un 0 o u 1 la pertenencia, o no, del registro a esa categoria.
Las categorías nuevas se guardan en un dataframe que he llamado dummie. Este data frame debe concatenarse con el de origen, pero debemos eliminar también las columnas que se han utilizado para crear las categorías.
cars_ready = cars_ready.drop(["company", "color", "dealer", "province", "country", "publish_date", "insert_date"], axis=1) concat_cars = pd.concat([cars_ready, dummies], axis=1)
Cuando ya hemos trabajado con los datos eliminando los espacios en blanco y convietiendo en categorias los campos de tipo texto, podemos crear los juegos de datos necesarios para realizar el entreno.
Se necesita separar las features del target, es decir las variables independientes de la dependiente, y al mismo tiempo se necesitan dos juegos de datos, uno para entrenar el modelo y otro para testearlo.
X = concat_cars.drop("price", axis=1)
y= concat_cars["price"]
from sklearn.model_selection import train_test_split
X_entreno, X_test, y_entreno, y_test = train_test_split(X, y, test_size=0.2)
En la X tenemos las variables independientes y en y la variable dependiente, es decir, la variable de la que queremos encontrar en valor en nuestras predicciones.
Usamos train_test_split para que divida los datos con el porcentaje que le indicamos, que en este caso será un 20% de datos para test y un 80% de datos para entrenar el modelo.
Una vez ya tenemos nuestro juego de datos preparado hay que escoger que estimator de scikit vamos a usar. Aunque yo tengo tendencia a usar siempre un estimator basado en RandomForest, tanto sea para regresión como clasificación, hay veces que otros algoritmos pueden dar mejor resultado. Aparte tenemos que aprovechar dos ventajas que nos da scikit-learn:
- Su gráfico para escoger un estimator. Actua como guia rápida, bastante sencilla de usar.
- La facilidad en probar diferentes modelos.
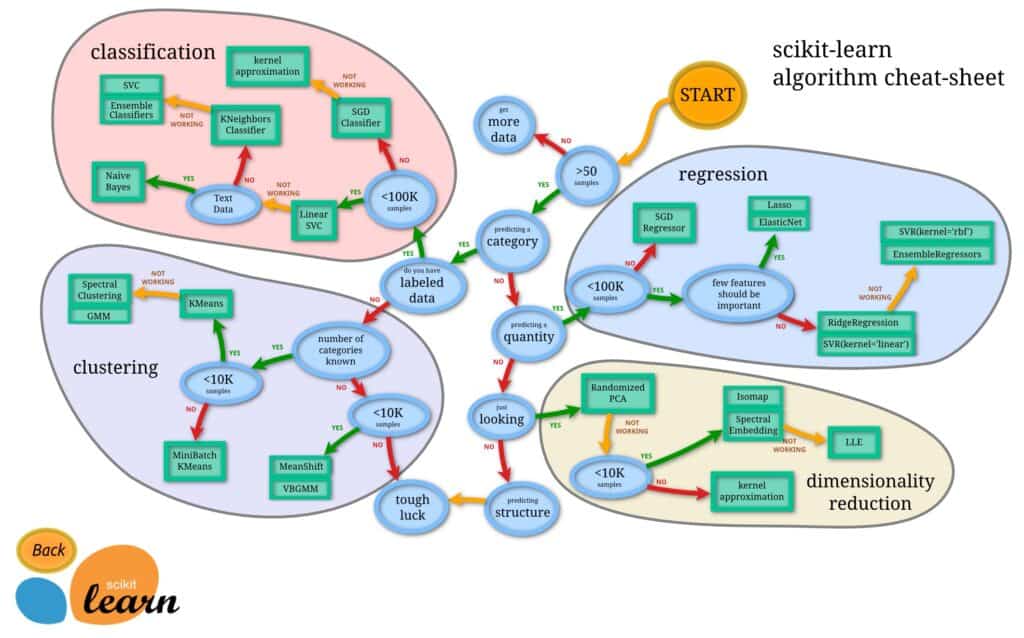
Siguiendo este gráfico podemos decidir que estimator se adapta mejor al problema que queremos resolver y a los datos que disponemos.
Bueno pues con nuestros datos he probado tres estimators diferentes:
Ridge Regression.
from sklearn import linear_model modelo = linear_model.Ridge() modelo.fit(X_entreno, y_entreno)
Un estimator basado en Ridge Regression suele usarse cuando el número de variables independientes es muy grande, puede llegar a ser mayor que el número de registros disponibles. Parece bastante claro que no es nuestro caso. Aunque el número de columnas que nos han quedado después de la transformación de los datos de texto en categorías usando dummies es mucho mayor que el que teníamos al principio.
Hemos llegado a el, por que en la fatídica pregunta «few features should be important» que nos encontramos en el diagrama que nos ofrecen la gente de scikit… hemos respondido que NO.
Aún así su score nos ha dado un resultado de 0.78. Nada mal por ser un primer intento, con un tratamiento de los datos no del todo «profesional» y sin tocar nada del modelo.
LASSO Model.
from sklearn import linear_model modelo = linear_model.Lasso() modelo.fit(X_entreno, y_entreno)
Se usa cuando, aunque tengamos muchos features, tan solo unos pocos de ellos son realmente importantes. En nuestro modelo la respuesta a esta pregunta sería diferente si la tenemos que responder con los datos de origen a los datos ya tratados. Se ha aumentado en mucho el número de columnas y por lo tanto se ha reducido su peso. No creo que Lasso sea el modelo que más se adapte a la nueva forma de los datos. Pero….. ¿y si hubiéramos transformado de una forma diferente las columnas?
La estrategia que hemos seguido es la de crear columnas nuevas por cada marca, y asignar un 0 o un 1 dependiendo de si el coche pertenece o no a esa marca. Otra estrategia podría haber sido convertir los valores texto en numericos. Seat = 3, Volkswagen = 5, Volvo = 1….. y dejar todos los valores en la misma columna. Así tendríamos una columna con todos los datos de marca y con un peso bastante grande sobre la variable dependiente.
¿Os fijais? Una decisión en cómo tratar los datos nos puede llevar a escoger un estimator u otro.
Bueno, con LASSO hemos obtenido un 0.76. Ni tan mal.
RandomForestRegressor
from sklearn.ensemble import RandomForestRegressor modelo = RandomForestRegressor() modelo.fit(X_entreno, y_entreno)
Un algoritmo basado en Random Forest sirve para casi todo y lo hace casi todo bien. Tenemos el RandomForestClassifier para clasificar y el RandomForestRegressor para problemas de regresión. En el vídeo me confundo y intento usar el Classifier en un problema de regresión 🙂
Funciona bien casi siempre, pero si tienes muchos datos mejor!
En nuestro modelo hemos conseguido un score del 0.92. Espectacular!!!!
¿Que hemos aprendido solucionando nuestro problema de regresión?
Lo más importante ha sido la transformación de los datos, y las decisiones que se han ido tomando para modelar los datos para que sean aptas para un Modelo de Machine Learning.
Hay dos transformaciones que se deben hacer: Eliminar los campos sin valor y transformar textos, o campos sin estructurar, en categorias.
Los campos vacíos pueden eliminarse de varias formas:
- Eliminando las columnas. Como en el caso de Price_financed. Una columna con el 50% de sus valores vacíos no tiene sentido, a no ser de que seamos capaces de rellenarlos de una forma coherente. Eliminar los registros en este caso tampoco sería una opción ya que el número de datos que perderiamos haría perder mucho valor a nuestro modelo.
- Eliminar los registros. En el caso de que sean unas pocas filas y los datos a vacíos no son muy importantes para nuestro modelo se pueden eliminar los registros. Se debe tener en cuenta que perdemos el peso de las otras columnas, pero si el número de registros a eliminar es muy pequeño es la mejor opción.
- Sustituir los valores vacíos. En este caso nos encontramos con dos casos toalmente diferentes.
- Sustitución de valores numéricos. Lo mejor es calcular una media del grupo más acotado posible. Es decir, si podemos sacar una media del precio del modelo será mejor que la media del precio de la marca y mucho mejor que una media general de todos los precios.
- Sustitución de categorías. Si no podemos adivinar a qué categoría pertenece, cosa que muchas veces puede hacerse mirando datos del mismo dataset, lo mejor es crear como mínimo una categoría nueva. La intención es intentar que esta nueva categoría no influya en el cálculo de la variable dependiente.
La sustitución de campos texto en categorías tambíen hay varias formas de atacar, solo hemos visto una, pero voy a indicar dos.
- Creación de categorías en columnas. Usando la función get_dummies de pandas se convierte automáticamente el contenido de la columna en nuevas columnas numéricas donde se indica la pertinencia o no del registro a esa columa. Por ejemplo, en nuestro modelo se ha creado una columna SEAT, que ha sido sacada del contenido de la columna Marca. Todos los coches que tenían el valor «SEAT» en la columna Marca, ahora tienen un «1» en la columna SEAT.
- Sustitución de los textos por valores numéricos. Mediante pandas decidimos sustituir todos los SEAT por 5’s los Volvo por 2… etc… Con lo que acabamos teniendo una columna numérica.
La decisión de cómo realizar la transformación a categorías puede, y debe, influir en el algoritmo que después usaremos. Podemos acabar con una columna que tenga mucho peso en el modelo, si hemos decidido no crear columnas nuevas por cada categoría. En este caso nos funcionará mejor un algoritmo basado en Lasso. En cambio si hemos decidido transformar en columnas nuevas todas las categorías podemos acabar con un dataset que se adapte mejor a un algoritmo de tipo Ridge Regression. En ambos caso… siempre hay que probar el RandomForest 🙂
Finalmente le hemos dado un vistazo al gráfico de SciKit-learn que nos ayuda a escoger un estimator y hemos probado tres de ellos. Ya hemos visto que hay que perderle el miedo a probar, no nos quita demasiado tiempo. Si podemos seleccionar el algoritmo con un poco de conocimiento mucho mejor, pero si tenemos dudas…. adelante! Probemos!
Continuaremos aprendiendo IA y ML.
Lo que nos queda!!!!! Esta es la segunda lección, y hemos visto un montón de cosas, pero estamos rascando….. y continuaremos rascando. Prefiero que demos un vistazo amplio por todas las ramas de la IA, antes de que estemos 4 horas hablando de cómo debemos evaluar el funcionamiento de un algoritmo LASSO.
Ya entraremos, si nos interesa mas adelante. Pero veamos todas las ramas de la IA, no tan solo el Machine Learning. Que seamos capaces de escoger que nos gusta y que nos apasiona.
Pero por ahora…. no tengo claro cómo voy a continuar. Pero que en algún momento veremos cosas de reinforcement learnig y deep learning esta más que claro!
Comments