
Si estás leyendo esto, es que realmente estás interesado en nuevas técnicas de Fine-Tuning de Grandes Modelos de Lenguaje. He sido totalmente incapaz de crear un título que sea medio entendible, y mucho menos atractivo, para alguien que no sepa lo que es el Fine-Tuning.
Vamos a ver si como mínimo consigo explicar lo que vamos a ver en el artículo, y así puedes decidir si realmente es lo que estás buscando.
Empezaré con una breve explicación de lo que es el Prompt-Tuning. Entiendo que a estas alturas ya tienes claro lo que es el Fine-Tuning. Una vez entendida la técnica y sus aplicaciones, pasaremos a estudiar el notebook que contiene el ejemplo.
En el notebook vamos a entrenar dos modelos diferentes, pero partiendo de un mismo modelo preentrenado. Así podremos ver una de las características más especiales de esta técnica de fine-tuneado. El ahorro de memoria al permitir tener varios modelos, con finalidades diferentes, en memoria, cargando tan solo un modelo preentrenado.
¿Esto es lo que estabas buscando? Pues vamos a por ello.
¿Qué es el Prompt Tuning?
Se trata de una técnica Aditiva de Fine-Tuning de Modelos. Esto quiere decir que NO VAMOS MODIFICAR NINGUN PESO DEL MODELO ORIGINAL. Te estarás preguntando ¿cómo vamos a realizar entonces el fine-tuning? Pues vamos a entrenar unas capas adicionales que se incorporan al modelo. Por eso se le llama técnica Aditiva.
Bien, si tenemos en cuenta que es una técnica Aditiva, y que su nombre es Prompt-Tuning parece claro que las capas que vamos a incorporar y entrenar tiene algo que ver con el prompt. ¡EXACTO! Así es.
Un Prompt no es nada más y nada menos que las instrucciones que le pasamos al modelo para que ejecute una acción. Nosotros las escribimos en nuestro idioma, es decir, lenguaje natural, pero el modelo recibe sus tokens en su idioma, en grandes modelos de lenguaje, solemos llamarlos embeddings, representaciones numéricas del texto que nosotros enviamos en el prompt.

Los embeddings de la derecha representan la frase ‘Yo soy tu Prompt’. Para realizar el entreno lo que hacemos es añadir unos espacios más a los embeddings de entrada del modelo, y serán esos embeddings los que verán modificados sus pesos mediante el entreno.

Es decir, estamos creando una especie de superprompt dejando que un modelo complemente parte del prompt con lo que ha aprendido. Pero esa parte del prompt no puede ser pasada a lenguaje natural, es como si nosotros hubiéramos aprendido a expresarnos en embeddings y a crear unos prompts increíblemente eficientes.
Todos los pesos del Modelo preentrenado están bloqueados y, por lo tanto, no pueden modificarse durante la fase de entreno.
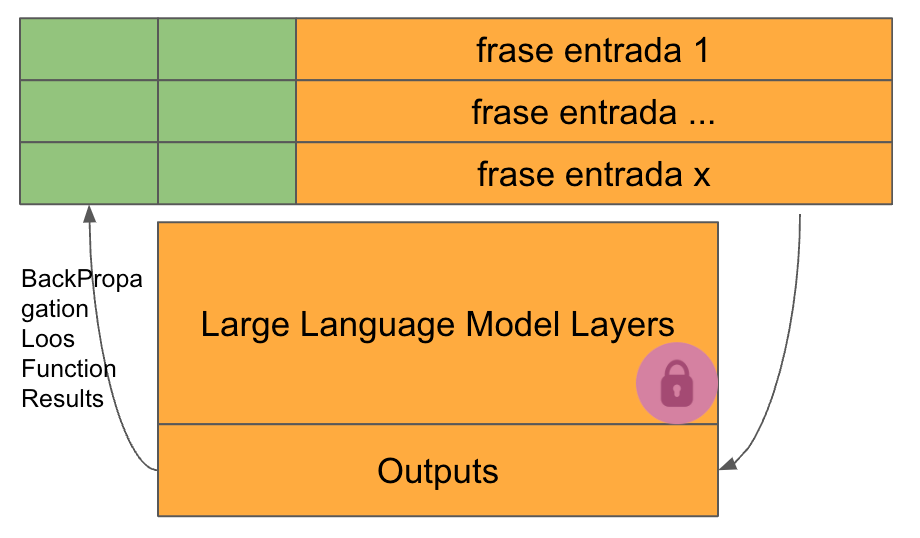
En cada ciclo de entreno los únicos pesos que pueden ser modificados para reducir el valor de la función de pérdida son los que se han incorporado al prompt. La primera consecuencia es que el número de parámetros a entrenar es muy pequeño. Pero encontramos una segunda consecuencia muy importante, y es que debido a que no tocamos los pesos del modelo preentrenado, este no varía su comportamiento, ni puede olvidar nada de lo previamente aprendido.
Nuestro Notebook de Ejemplo.
El Notebook está disponible en GitHub: https://github.com/peremartra/Large-Language-Model-Notebooks-Course/blob/main/5-Fine%20Tuning/Prompt_Tuning_PEFT.ipynb
Forma parte del curso de Grandes Modelos de Lenguaje, también disponible en GitHub: https://github.com/peremartra/Large-Language-Model-Notebooks-Course/blob/main/5-Fine%20Tuning/Prompt_Tuning_PEFT.ipynb
Como ya he dicho, vamos a entrenar dos modelos. Uno de ellos será un modelo especializado en crear prompts para grandes modelos de lenguaje y el otro se entrenará para crear frases de motivación. Para a ello vamos a usar dos Datasets y un solo modelo preentrenado.
Los Datasets:
- https://huggingface.co/datasets/fka/awesome-chatgpt-prompts
- https://huggingface.co/datasets/Abirate/english_quotes
El Modelo: Cualquiera de la familia Bloom, en el notebook he usado: bigscience/bloomz-560m y bigscience/bloom-1b1.
Lo primero que vamos a hacer es cargar algunas de las librerías a utilizar en el notebook. Atención, yo cargo las librerías necesarias en Colab, si preferís trabajar en vuestro entorno, quizás ya tengáis cargada alguna de ella, u os falte alguna otra.
!pip install peft !pip install datasets #necesary to load the Datasets. # !pip install transformers #If you don't have transformers library installed from transformers import AutoModelForCausalLM, AutoTokenizer
Ahora podemos cargar el Modelo y su tokenizador.
Cargar el modelo.
model_name = "bigscience/bloomz-560m" #model_name="bigscience/bloom-1b1" NUM_VIRTUAL_TOKENS = 4 NUM_EPOCHS = 5
Aunque yo he hecho pruebas con dos de los modelos de la familia Bloom, podríamos haber usado cualquiera que fuera compatible con el entreno Prompt Tuning para Casual Modeling Language de la librería PEFT. Los modelos se pueden consultar en el repositorio GitHub de la librería: https://github.com/huggingface/peft#models-support-matrix
La variable NUM_VIRTUAL_TOKENS, contiene el número de tokens que queremos añadir al prompt, y que, por lo tanto, serán entrenables. Podéis modificar el valor para probar como afecta al resultado, a más tokens, más parámetros se podrán entrenar.
Ahora vamos a cargar tokenizador y modelo. A mayor tamaño del modelo, mayor será el tiempo de descarga. Indico la variable trust_remote a True, para que el modelo pueda ejecutar código para su instalación, en caso de que lo necesite.
tokenizer = AutoTokenizer.from_pretrained(model_name)
foundational_model = AutoModelForCausalLM.from_pretrained(
model_name,
trust_remote_code=True
)
El tokenizador es el responsable de traducir de lenguaje natural a tokens entendibles por el Modelo, y viceversa. Traduce el prompt de entrada, y los outputs del modelo.
Cargar el tokenizador y el modelo es muy sencillo usando las clases que nos ofrece la librería Transformers de Hugging Face.
Con esto ya tenemos el modelo en memoria, podemos hacer una primera prueba sin realizar ningún tipo de fine-tuning y así podremos comprobar como varían los resultados después de los dos procesos de fine-tuning.
Una primera prueba con el modelo preentreado.
Para ejecutar la llamada al modelo voy a crear una función que reciba el modelo, el input del modelo y la longitud máxima de la respuesta.
#this function returns the outputs from the model received, and inputs.
def get_outputs(model, inputs, max_new_tokens=100):
outputs = model.generate(
input_ids=inputs["input_ids"],
attention_mask=inputs["attention_mask"],
max_new_tokens=max_new_tokens,
repetition_penalty=1.5, #Avoid repetition.
early_stopping=True, #The model can stop before reach the max_length
eos_token_id=tokenizer.eos_token_id
)
return outputs
Obtener una respuesta del modelo, va a ser tan sencillo como llamar a esta función y esperar a que el modelo nos devuelva el resultado. Como he decidido entrenar dos modelos diferentes voy a realizar dos pruebas.
input_prompt = tokenizer("I want you to act as a motivational coach. ", return_tensors="pt")
foundational_outputs_prompt = get_outputs(foundational_model, input_prompt, max_new_tokens=50)
print(tokenizer.batch_decode(foundational_outputs_prompt, skip_special_tokens=True))
["I want you to act as a motivational coach. Don't be afraid of being challenged."]
input_sentences = tokenizer("There two thing that matter:", return_tensors="pt")
foundational_outputs_sentence = get_outputs(foundational_model, input_sentences, max_new_tokens=50)
print(tokenizer.batch_decode(foundational_outputs_sentence, skip_special_tokens=True))
['There two thing that matter: the size and shape of a flower']
No se puede decir que ninguna dé las respuestas sean incorrectas. El modelo complementa la frase que le hemos pasado, pero él no sabe qué intención tenemos, ni como queremos que se comporte. Esto vamos a intentar solucionarlo en la fase de fine-tuning, donde vamos a entrenar cada modelo con frases específicas para que responda con una personalidad diferente después de cada fine-tunig.
Veamos si se consigue cambiar el comportamiento del modelo preentrenado en los dos procesos de fine-tuning.
Preparando los Datasets.
Vamos a cargar cada Dataset por separado, para mejorar el rendimiento tan solo voy a cargar un pequeño número de filas de cada uno de ellos.
from datasets import load_dataset
dataset_prompt = "fka/awesome-chatgpt-prompts"
#Create the Dataset to create prompts.
data_prompt = load_dataset(dataset_prompt)
data_prompt = data_prompt.map(lambda samples: tokenizer(samples["prompt"]), batched=True)
train_sample_prompt = data_prompt["train"].select(range(50))
train_sample_prompt = train_sample_prompt.remove_columns('act')
display(train_sample_prompt)
En este ejemplo estoy eliminando la columna ‘act’ del Dataset. Es una decisión de diseño, realmente creo que no aporta demasiado, pero podéis probar como afecta si mantenemos la columna. Es tan sencillo como comentar la línea que elimina la columna, el resto del notebook continúa funcionando.
Veamos el primer registro del Dataset:
{'act': ['Linux Terminal'], 'prompt': ['I want you to act as a linux terminal. I will type commands and you will reply with what the terminal should show. I want you to only reply with the terminal output inside one unique code block, and nothing else. do not write explanations. do not type commands unless I instruct you to do so. when i need to tell you something in english, i will do so by putting text inside curly brackets {like this}. my first command is pwd']}
Creo que Manteniendo tan solo la información de la columna Prompt podemos hacer el entreno. En realidad lo he probado y pienso que funciona mejor. Pero sacad vuestras propias conclusiones.
dataset_sentences = load_dataset("Abirate/english_quotes")
data_sentences = dataset_sentences.map(lambda samples: tokenizer(samples["quote"]), batched=True)
train_sample_sentences = data_sentences["train"].select(range(25))
train_sample_sentences = train_sample_sentences.remove_columns(['author', 'tags'])
display(train_sample_sentences)
Para el segundo Dataset he seguido exactamente la misma estrategia, elimino las columnas que me parecen menos relevantes.
Ahora tenemos los datos en dos Datasets: train_sample_sentences y train_sample_prompt. Como ya hemos cargado el modelo y el tokenizer, estamos listos para empezar con el proceso de fine-Tuning.
Fine-Tuning con PEFT.
Lo primero es crear un objeto con la configuración del entreno que queremos realizar. Vamos a utilizar el método PromptTuningConfig, pero este tiene diversas opciones y tenemos que indicar cuáles queremos usar.
from peft import get_peft_model, PromptTuningConfig, TaskType, PromptTuningInit
generation_config = PromptTuningConfig(
task_type=TaskType.CAUSAL_LM, #This type indicates the model will generate text.
prompt_tuning_init=PromptTuningInit.RANDOM, #The added virtual tokens are initializad with random numbers
num_virtual_tokens=NUM_VIRTUAL_TOKENS, #Number of virtual tokens to be added and trained.
tokenizer_name_or_path=model_name #The pre-trained model.
)
Mediante PrompTuningconfig creamos una variable que contiene la configuración que deberemos usar en la llamada a get_peft_model. Veamos los parámetros que le estamos pasando:
- task_type. Con el valor CAUSAL_LM estamos Indicando que queremos fine-tunear un modelo para generación de texto.
- prompt_tuning_info. Nos permite indicar un valor inicial para los vectores añadidos que pueden ser entrenados. En este caso le indico que se inicialicen con valores aleatorios. Pero también podríamos indicar que todos empezarán con un valor concreto, pudiendo indicar un texto. No he detectado diferencias significativas usando un método u otro. Para ello tendríamos que indicar los valores:
- prompt_tuning_info = PromptTuningInit.TEXT
- prompt_tunin_init_text = «Texto inicial aquí»
- num_virtual_tokes. El número de tokens a entrenar. Debe mantener una relación con los prompts que le vamos a enviar. Como más corto el prompt menos tokens virtuales a entrenar deberíamos configurar. No siempre aumentarlos conlleva un mejor rendimiento del modelo.
- tokenizer_name_or_path. el nombre del modelo.
Para crear el modelo tan solo tenemos que llamar a get_peft_model y pasarle el modelo preentrenado que hayamos seleccionado y la configuración que acabamos de crear.
Vamos a crear dos modelos usando la misma configuración y modelo preentrenado.
peft_model_prompt = get_peft_model(foundational_model, generation_config) print(peft_model_prompt.print_trainable_parameters())
trainable params: 4,096 || all params: 559,218,688 || trainable%: 0.0007324504863471229 None
peft_model_sentences = get_peft_model(foundational_model, generation_config) print(peft_model_sentences.print_trainable_parameters())
trainable params: 4,096 || all params: 559,218,688 || trainable%: 0.0007324504863471229 None
¿Qué os parece? Vamos a entrenar un modelo modificando el 0.0007% de sus pesos. ¡Esto es increíble! Lo és todavia más si tenemos en cuenta que en el paper «The Power of Scale for Parameter-Efficient Prompt Tuning» se pueden conseguir resultados equivalentes a los de un Fine-tuning completo.
Una vez ya tenemos el modelo, tenemos que crear la configuración del entreno. Lo conseguimos con la clase TrainingArguments, que voy a poner dentro de una función para poder usar argumentos diferentes en cada uno de los modelos.
from transformers import TrainingArguments
def create_training_arguments(path, learning_rate=0.0035, epochs=6):
training_args = TrainingArguments(
output_dir=path, # Where the model predictions and checkpoints will be written
use_cpu=True, # This is necessary for CPU clusters.
auto_find_batch_size=True, # Find a suitable batch size that will fit into memory automatically
learning_rate= learning_rate, # Higher learning rate than full fine-tuning
num_train_epochs=epochs
)
return training_args
En el primer parámetro vemos que le estamos indicando un directorio. Este directorio va a contener el Modelo fine-tuneado y es obligatorio pasárselo. Los otros parámetros son ya viejos conocidos. El learning_rate, que indica la variación máxima que pueden tener los pesos en cada paso, y num_train_epochs, que contiene el número de épocas que queremos dure el entreno.
El código siguiente lo único que hace es crear los directorios que contendrán los modelos en el caso de que no existan.
import os
working_dir = "./"
#Is best to store the models in separate folders.
#Create the name of the directories where to store the models.
output_directory_prompt = os.path.join(working_dir, "peft_outputs_prompt")
output_directory_sentences = os.path.join(working_dir, "peft_outputs_sentences")
#Just creating the directoris if not exist.
if not os.path.exists(working_dir):
os.mkdir(working_dir)
if not os.path.exists(output_directory_prompt):
os.mkdir(output_directory_prompt)
if not os.path.exists(output_directory_sentences):
os.mkdir(output_directory_sentences)
Ya podemos crear los argumentos de entreno de cada modelo.
training_args_prompt = create_training_arguments(output_directory_prompt, 0.003, NUM_EPOCHS) training_args_sentences = create_training_arguments(output_directory_sentences, 0.0035, NUM_EPOCHS)
Continuemos con el proceso de fine-tuning. Voy a crear una función que llamaremos para cada modelo que queramos fine-tunear.
from transformers import Trainer, DataCollatorForLanguageModeling
def create_trainer(model, training_args, train_dataset):
trainer = Trainer(
model=model, # We pass in the PEFT version of the foundation model, bloomz-560M
args=training_args, #The args for the training.
train_dataset=train_dataset, #The dataset used to tyrain the model.
data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=False) # mlm=False indicates not to use masked language modeling
)
return trainer
Creamos el objeto Trainer, y para ello le pasamos:
- El modelo PEFT que hemos obtenido de la llamada a get_peft_model.
- Los argumentos que hemos creado con TrainingArguments.
- El dataset que hemos preparado al inicio del notebook.
- El resultado de llamar a DataCollatorForLanguageModeling. Que prepara el Dataset para ser tratado en bloques por el modelo.
Ya lo tenemos todo listo para realizar el fine-tuning de los modelos:
trainer_prompt = create_trainer(peft_model_prompt, training_args_prompt, train_sample_prompt) trainer_prompt.train() trainer_sentences = create_trainer(peft_model_sentences, training_args_sentences, train_sample_sentences) trainer_sentences.train()
El proceso de entreno del modelo puede durar unos 10 / 15 minutos en Colab. En mi máquina, un macbook pro con un chip M1 pro dura unos 3 minutos por modelo. Como se puede entender el entreno realizado no ha sido muy exhaustivo, se han usado muy pocos datos y muy pocas épocas. Sentíos libres, yo diría que es, casi obligado, a modificar los parámetros para ejecutar un fine-tuneado con más datos y épocas para ver cómo varía la respuesta de nuestros modelos.
trainer_prompt.model.save_pretrained(output_directory_prompt) trainer_sentences.model.save_pretrained(output_directory_sentences)
Guardo los modelos, porque una de las características más importantes de este tipo de entreno es el poco espacio en disco y memoria que ocupan. Es verdad que deben trabajar conjuntamente con el modelo preentrenado, que debemos cargarlo en memoria. Pero podríamos tener n modelos fine-tuneados que usaran el mismo modelo preentrenado cargado en memoria. Con las otras técnicas de fine-tuning deberíamos tener n copias del modelo preentrenado, ya que sus pesos habrían sido modificados.
En mi disco duro, cada uno de los modelos que acabo de guardar ocupan 300KB. Comprobad cuanto ocupan en el vuestro, pero debería ser algo parecido.
Vamos a cargar cada uno de los modelos y a realizar la misma llamada que al modelo preentrenado, a ver si su respuesta es la misma o se ha modificado.
loaded_model_prompt_outputs = get_outputs(loaded_model_prompt, input_prompt) print(tokenizer.batch_decode(loaded_model_prompt_outputs, skip_special_tokens=True))
I want you to act as a motivational coach. You can use this method if you're not sure what your goals are.
Comparemos los dos resultados:
- Pretrained Model: I want you to act as a motivational coach. Don’t be afraid of being challenged.
- Fine Tuned Model: I want you to act as a motivational coach. You can use this method if you’re not sure what your goals are.
Está claro que la respuesta es diferente, y que, por lo tanto, hemos influenciado la respuesta del modelo con nuestro proceso de fine-tuning. Es verdad que no se parece demasiado a los prompts que le hemos pasado, pero sí que se parece más a unas instrucciones que la frase del modelo preentrenado.
Veamos el segundo modelo:
loaded_model_sentences_outputs = get_outputs(loaded_model_sentences, input_sentences) print(tokenizer.batch_decode(loaded_model_sentences_outputs, skip_special_tokens=True))
- Pretrained Model: There two thing that matter: the size and shape of a flower
- Fine Tuned Model: There two thing that matter: one is the weather and another, what you do.
Pues más o menos lo mismo que con el primer modelo. Lo importante es que tenemos en memoria dos modelos que se comportan de forma diferente, debido a su fine-tuneado, y que tan solo tenemos una copia del modelo pre-entrenado en memoria.
Conclusiones.
La técnica del PrompTuning es realmente impresionante. Los resultados que se obtienen son muy prometedores, y el ahorro tanto en entreno como en inferencia son abismales.
No dudéis en modificar todo lo que queráis del Notebook, miraros el paper The Power of Scale for Parameter-Efficient Prompt Tuning y decidid por vosotros mismos si un número mayor de tokens entrenables pueden ayudar en el fine-tuning.
¡Espero que os haya gustado! Como siempre os recomiendo que sigáis el repositorio de GitHub donde voy colgando las nuevas lecciones y notebooks del curso de Grandes Modelos de Lenguage.