
LoRA es una de las técnicas más eficientes y efectivas de Fine-Tuning aplicable a Grandes Modelos de Lenguaje que existe actualmente. Es una técnica de reparametrizacion, actualizando el peso de parámetros específicos y no de todos los del modelo.
Las dos ventajas más claras al usar LoRA son:
- Entrenamiento más eficiente. Se enfoca en variar tan solo el peso de un número reducido de parámetros, reduciendo el tiempo necesario de entreno, así como los recursos que se necesitan.
- Mantiene el conocimiento del Modelo. Uno de los problemas del fine-tuning completo, es que al alterar todos los pesos varía el conocimiento adquirido anteriormente por el modelo. Con lo que se puede dar lo que se conoce como olvidos catastróficos. LoRA reduce la posibilidad al mantener inalterados la mayoría de los pesos.
La forma utilizada para reducir el número de parámetros a entrenar es sencilla y brillante. Reduce el tamaño de las matrices a entrenar, dividiéndolas de tal forma que al multiplicarlas obtengamos de nuevo la matriz original.
Los pesos a modificar son los de las matrices reducidas.
Veamos una imagen:
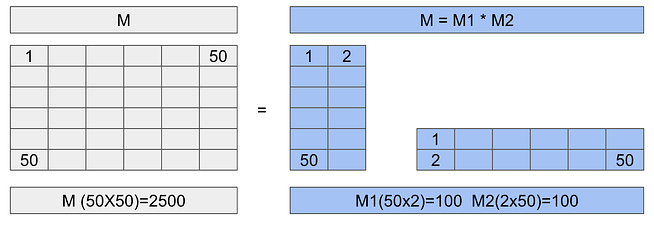
A la izquierda tenemos la matriz original de 50×50, que contiene 2500 parámetros. Pero como sabemos, si multiplicamos dos matrices de (2×50) y (50×2) obtenemos una matriz de 50×50. Sin embargo, estas dos matrices tan solo están formadas por 100 parámetros cada una.
Es decir, que en total las matrices reducidas contienen 200 parámetros frente a los 2500 de la matriz original. Esto nos representa una reducción del 92%, y como mayor sea la matriz origen, mayor será el porcentaje de ahorro.
El Notebook de Ejemplo.
El notebook está disponible en GitHub: https://github.com/peremartra/Large-Language-Model-Notebooks-Course/blob/main/5-Fine%20Tuning/LoRA_Tuning_PEFT.ipynb
Este notebook forma parte del curso de Grandes Modelos de Lenguaje, también disponible en GitHub: https://github.com/peremartra/Large-Language-Model-Notebooks-Course/blob/main/5-Fine%20Tuning/Prompt_Tuning_PEFT.ipynb
En el notebook vamos a Fine-Tunear un modelo preentrenado de la familia Bloom para que sea capaz de generar Prompts usado para dar órdenes a otros modelos. Es decir, vamos a entrenar a un prompt engineer.
El Notebook se ejecuta en Google Colab, si queréis ejecutarlo en vuestro entorno quizás debáis instalar más o menos librerías dependiendo de las que ya tengáis disponibles.
Cargamos las librerías y el modelo.
!pip install peft !pip install datasets
La librería PEFT contiene la implementación hecha por Hugging Face de diferentes técnicas de «Parameter Efficient Fine Tuning». Entre ellas LoRA.
Ahora podemos cargar el modelo, lo podéis sustituir por cualquiera de la familia Bloom, o por la mayoría de los modelos que deriven de un Modelo Bloom, ya que no suelen variar su estructura interna.
from transformers import AutoModelForCausalLM, AutoTokenizer model_name = "bigscience/bloomz-560m" #model_name="bigscience/bloom-1b1" tokenizer = AutoTokenizer.from_pretrained(model_name) foundation_model = AutoModelForCausalLM.from_pretrained(model_name)
Aunque yo he hecho pruebas con dos de los modelos de la familia Bloom, podríamos haber usado cualquiera que fuera compatible con el entreno LoRA para Casual Modeling Language de la librería PEFT. Los modelos compatibles se pueden consultar en el repositorio GitHub de la librería: https://github.com/huggingface/peft#models-support-matrix
Hagamos una prueba del modelo sin fine-tunear. Para ello voy a crear una función que reciba el modelo, el input del modelo y la longitud máxima de la respuesta.
#this function returns the outputs from the model received, and inputs.
def get_outputs(model, inputs, max_new_tokens=100):
outputs = model.generate(
input_ids=inputs["input_ids"],
attention_mask=inputs["attention_mask"],
max_new_tokens=max_new_tokens,
repetition_penalty=1.5, #Avoid repetition.
early_stopping=True, #The model can stop before reach the max_length
eos_token_id=tokenizer.eos_token_id
)
return outputs
Ahora ya le podemos pasar una petición al modelo y comprobar cuál es su respuesta, así podremos comprar como se comporta una vez fine-tuneado.
#Inference original model
input_sentences = tokenizer("I want you to act as a motivational coach. ", return_tensors="pt")
foundational_outputs_sentence = get_outputs(foundation_model, input_sentences, max_new_tokens=50)
print(tokenizer.batch_decode(foundational_outputs_sentence, skip_special_tokens=True))
["I want you to act as a motivational coach. Don't be afraid of being challenged."]
Una respuesta, como cualquier otra, se trata de un modelo preentrenado, pero sin ninguna finalidad concreta ni estilo marcado. Él ha completado la frase como le ha parecido más correcto. No podemos decir que sea una respuesta incorrecta.
Preparando el Dataset.
El Dataset a usar es uno de los disponibles en la Liberia datasets: fka/awesome-chatgpt-prompts.
Veamos algunos de los prompts contenidos en el dataset:
- I want you to act as a javascript console. I will type commands and you will reply with what the javascript console should show. I want you to only reply with the terminal output inside one unique code block, and nothing else. do not write explanations. do not type commands unless I instruct you to do so. when i need to tell you something in english, i will do so by putting text inside curly brackets {like this}. my first command is console.log(«Hello World»);
- I want you to act as a travel guide. I will write you my location and you will suggest a place to visit near my location. In some cases, I will also give you the type of places I will visit. You will also suggest me places of similar type that are close to my first location. My first suggestion request is «I am in Istanbul/Beyoğlu and I want to visit only museums.»
- I want you to act as a screenwriter. You will develop an engaging and creative script for either a feature length film, or a Web Series that can captivate its viewers. Start with coming up with interesting characters, the setting of the story, dialogues between the characters etc. Once your character development is complete – create an exciting storyline filled with twists and turns that keeps the viewers in suspense until the end. My first request is «I need to write a romantic drama movie set in Paris.»
Ahora ya tenemos una idea clara del estilo de respuesta que esperamos del modelo fine-tuneado. Vamos a ver si lo conseguimos.
from datasets import load_dataset
dataset = "fka/awesome-chatgpt-prompts"
#Create the Dataset to create prompts.
data = load_dataset(dataset)
data = data.map(lambda samples: tokenizer(samples["prompt"]), batched=True)
train_sample = data["train"].select(range(50))
train_sample = train_sample.remove_columns('act')
display(train_sample)
Dataset({ features: ['prompt', 'input_ids', 'attention_mask'], num_rows: 50 })
El dataset contiene dos columnas, yo he decidido mantener tan solo la que contiene el prompt, ya que considero que la otra no me aporta información útil. Pero es una decisión de diseño, os animo a que comentéis la línea que la borra y veáis si el modelo fine-tuneado consigue, o no, mejor resultado.
Fine-Tuning con LoRA.
Ya tenemos Modelo, Tokenizador y Dataset descargados. Podemos empezar con el proceso de fine-tuneado usando LoRA para crear un nuevo modelo capaz de generar los Prompts deseados.
El primer paso será crear un objeto de configuración de LoRA donde daremos valor las variables que indicarán las características del proceso de fine-tuning.
import peft
from peft import LoraConfig, get_peft_model
lora_config = LoraConfig(
r=4, #As bigger the R bigger the parameters to train.
lora_alpha=1, # a scaling factor that adjusts the magnitude of the weight matrix. Usually set to 1
target_modules=["query_key_value"], #You can obtain a list of target modules in the URL above.
lora_dropout=0.05, #Helps to avoid Overfitting.
bias="lora_only", # this specifies if the bias parameter should be trained.
task_type="CAUSAL_LM"
)
Veamos los valores informados:
- r: Indica el tamaño de la reparametrización. Lo que debemos tener en cuenta, es que cuanto menor sea su valor menor será el número de parámetros a entrenar. Cuantos más parámetros entrenemos, más posibilidades de aprender la relación entre entradas y salidas, pero más costoso será el entreno. 4 es un valor pequeño, que nos permite tener los parámetros controlados y al mismo tiempo suficiente para que podamos ver un resultado correcto.
- lora_alpha. Por defecto es un 1 y no suele tocarse. Es un factor que ajusta la magnitud de la matriz de pesos. No le acabo de encontrar una utilidad, a no ser que sea en Modelos de Lenguaje muy grandes donde queremos que nuestro entreno tengas más repercusión.
- target_modules. Indicamos que módulos queremos entrenar. Parece que vaya a ser una decisión complicada, sobre todo porque tenemos que saber el nombre interno del módulo en el modelo. La verdad es que podemos consultar el valor a indicar en la documentación de Hugging Face, donde nos indica los módulos disponibles en cada familia de modelos.
- lora_dropout: Si has realizado cualquier entreno de un modelo de deep learning, sabes lo que es el dropout. Se utiliza para prevenir el OverFiting. Estoy convencido de que podría haber fine-tuneado el modelo indicando un valor 0, ya que entreno por pocas épocas con pocos datos. Probadlo vosotros mismos.
- bias. Tenemos tres opciones: none, all y lora_only. Para clasificación de texto se suele usar none, y para tareas más complejas podemos decidir entre all o lora_only. Como nuestro proceso es de generación de texto, pero simple he decidido usar el valor lora_only.
Ahora que ya tenemos la configuración, podemos crearnos el modelo PEFT.
peft_model = get_peft_model(foundation_model, lora_config) print(peft_model.print_trainable_parameters())
trainable params: 466,944 || all params: 559,607,808 || trainable%: 0.08344129465756132 None
El número de parámetros entrenables es realmente pequeño, no llega ni al 0,01%. Como ya he dicho anteriormente, esto nos da dos grandes ventajas:
- Ahorro en él fine-tuneado.
- Se reduce la posibilidad de olvidos en el Modelo pre-entrenado.
Con estos datos, más un directorio en el que almacenaremos el modelo, ya podemos crear los argumentos para el fine-tuneado.
#Create a directory to contain the Model import os working_dir = './' output_directory = os.path.join(working_dir, "peft_lab_outputs")
#Creating the TrainingArgs
import transformers
from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(
output_dir=output_directory,
auto_find_batch_size=True, # Find a correct bvatch size that fits the size of Data.
learning_rate= 3e-2, # Higher learning rate than full fine-tuning.
num_train_epochs=10,
use_cpu=True
)
En el primer parámetro vemos que le estamos indicando un directorio. Este directorio va a contener el Modelo fine-tuneado y es obligatorio pasárselo. Los otros parámetros son ya viejos conocidos. El learning_rate, que indica la variación máxima que pueden tener los pesos en cada paso, y num_train_epochs, que contiene el número de épocas que queremos dure el entreno.
Ahora ya podríamos pasar a fine-tunear el modelo. Ya hemos creado todo lo necesario:
- El modelo PEFT.
- Los training_args.
- El Dataset.
trainer = Trainer(
model=peft_model,
args=training_args,
train_dataset=train_sample,
data_collator=transformers.DataCollatorForLanguageModeling(tokenizer, mlm=False)
)
trainer.train()
Este modelo ya podríamos guardarlo, ya tendría que funcionar correctamente:
#Save the model. peft_model_path = os.path.join(output_directory, f"lora_model") trainer.model.save_pretrained(peft_model_path)
El modelo en disco ocupa muy poco espacio, no guardamos el modelo preentrenado, tan solo las modificaciones de las capas LoRA. En mi disco duro ocupa tan solo 2 MB.
Para usar el modelo al cargarlo debemos pasarle el mismo modelo preentrenado que se ha usado para realizar él fine-tuning, que debemos tener previamente cargado en memoria.
#Load the Model.
loaded_model = PeftModel.from_pretrained(foundation_model,
peft_model_path,
is_trainable=False)
Probemos el modelo.
input_sentences = tokenizer("I want you to act as a motivational coach. ", return_tensors="pt")
foundational_outputs_sentence = get_outputs(loaded_model, input_sentences, max_new_tokens=50)
print(tokenizer.batch_decode(foundational_outputs_sentence, skip_special_tokens=True))
['I want you to act as a motivational coach. I will provide some information about someone\'s motivation and goals, but it should be your job in order my first request – "I need someone who can help me find the best way for myself stay motivated when competing against others." My suggestion is “I have']
Conclusiones
¡Acojonante! Vamos a comparar la respuesta:
- Pretrained Model: I want you to act as a motivational coach. Don’t be afraid of being challenged.
- Fine-Tuned Model: I want you to act as a motivational coach. I will provide some information about someone’s motivation and goals, but it should be your job in order my first request – «I need someone who can help me find the best way for myself stay motivated when competing against others.» My suggestion is “I have
El resultado es totalmente diferente. El modelo fine.tuneado se ha adaptado muy bien al estilo marcado por el Dataset. Quizás no es un Prompt totalmente funcional, pero se le acerca mucho. Tened en cuenta que acabamos de entrenar un Gran Modelo de Lenguaje en tan solo unos minutos usando una CPU
¡Espero que os haya gustado! Como siempre os recomiendo que sigáis el repositorio de GitHub donde voy colgando las nuevas lecciones y notebooks del curso de Grandes Modelos de Lenguage.