Una de las técnicas primordiales, en la creación de Small Language Models es el Pruning, pero para ejecutar un proceso de pruning exitoso es imprescindible conocer la estructura de los modelos objetivo.
En este artículo se explica como realizar un pruning sobre las capas MLP con estructura GLU (Gated Linear Units), es decir gran parte de los modelos actuales: Llama 3.2, Gemma, Mistral y QWen son tan solo algunas de las familias de modelos a los que se les puede aplicar el código de pruning que se presenta en el artículo.
Al realizar el pruning respetando la estructura Gated Linear Unit se consigue una reducción del peso del modelo, mientras se mantiene su capacidad de generar outputs coherentes y una sorprendente accuracy en el test BoolQ.
Introducción.
A medida que los grandes modelos de lenguaje han ido aumentado su tamaño para ganar en capacidades ha surgido una necesidad de reducir su tamaño, pero como es normal, no se quiere perder las capacidades. Para conseguir modelos de menor tamaño sque sean capaces de realizar las mismas tareas que los modelos grandes en los que se han basado se suelen utilizar diferentes técnicas, como: quantizació y pruning para la reducción de tamaño y knowledge distillation o transfer learning para que recuperen las capacidades perdidas con la reducción de tamaño.
El pruning posiblemente sea la técnica más eficiente en la reducción de tamaño de modelos, pero también es mucho más complicada de aplicar, ya que no tan solo tienes que decidir que parte del modelo va a ser objeto de pruning, sino seleccionar adecuadamente de esa parte cual es la que se puede remover afectando menos a las capacidades del modelo.
Que es el Pruning y como afecta al modelo.
Como ya he explicado anteriormente el pruning consiste en eliminar partes del modelo que creemos son las que menos aportan al resultado final del modelo. By carefully selecting these less critical components, pruning aims to create a more efficient model with fewer parameters and reduced computational requirements, without sacrificing its core capabilities.
El principal problema es decidir qué partes del modelo són las que vamos a eliminar, ya que no todas las secciones de un modelo afectan por igual, ya que cada una tiene una utilidad diferente.
Creo que la mejor forma de explicarlo va a ser usando la estructura del modelo que se puede encontrar en el notebook de ejemplo que acompaña al articulo: Llama 3.2-1B.
LlamaForCausalLM(
(model): LlamaModel(
(embed_tokens): Embedding(128256, 2048)
(layers): ModuleList(
(0-15): 16 x LlamaDecoderLayer(
(self_attn): LlamaSdpaAttention(
(q_proj): Linear(in_features=2048, out_features=2048, bias=False)
(k_proj): Linear(in_features=2048, out_features=512, bias=False)
(v_proj): Linear(in_features=2048, out_features=512, bias=False)
(o_proj): Linear(in_features=2048, out_features=2048, bias=False)
(rotary_emb): LlamaRotaryEmbedding()
)
(mlp): LlamaMLP(
(gate_proj): Linear(in_features=2048, out_features=8192, bias=False)
(up_proj): Linear(in_features=2048, out_features=8192, bias=False)
(down_proj): Linear(in_features=8192, out_features=2048, bias=False)
(act_fn): SiLU()
)
(input_layernorm): LlamaRMSNorm((2048,), eps=1e-05)
(post_attention_layernorm): LlamaRMSNorm((2048,), eps=1e-05)
)
)
(norm): LlamaRMSNorm((2048,), eps=1e-05)
(rotary_emb): LlamaRotaryEmbedding()
)
(lm_head): Linear(in_features=2048, out_features=128256, bias=False)
)
Mirando la estructura se pueden ver tres grandes bloques que pueden ser objetivos del Pruning. Los embeddings, el mecanismo de self attention y las capas MLP. Para decidir en cuál de ellas tenemos que centrar nuestro proceso de pruning es importante entender las posibles ganancias y las posibles afectaciones que puede tener sobre el modelo.
Así que lo primero es ver cuanto ocupa cada una de estas secciones dentro del modelo y así tener una idea de cual puede ser la ganancia en peso final.
- Embeddings y output layer (embed_tokens, lm_head). 128256 * 2048 262M * 2 524M Parámetros.
- Mecanismo de atención (self_attn): Está formado por 16 capas, cada una contiene cuatro capas más de proyección. Por capa tenemos 2048×(2048+512+512+2048) ≈ 10.5M Parameters. Es decir 10.5 x 16 = 168M Parámetros.
- MLP Layers (mlp). Igualmente formado por 16 capas, que como siguen la estructura GLU cada una tiene una capa gate_proj, up_proj y down_proj. Cada capa ocupa 2048 × 8192 + 2048 × 8192 + 8192 × 2048 ≈ 50M parameters. Que al multiplicarlo por 16 nos indica que está ocupando unos 805M parámetros.
Como se puede ver las capas MLP representan más del 40% del tamaño del modelo, por lo que parecen claras candidatas a ser pruneadas. Pero antes de tomar esta decisión es importante entender que aporta cada sección al comportamiento del modelo.
Las capas de embeddings se encarga de transformar las entradas al modelo en vector denso representations that the model can process effectively. Por lo tanto, prunear esta capa puede llevar a perder capacidad en capturar correctamente el significado semántico de los datos de entrada. Si quieres crear un modelo muy específico que utilice tan solo una parte muy concreta de su vocabulario de entrada, por ejemplo un modelo de análisis financiero o médico, se podría realizar un pruning de esta capa.
El mecanismo de atención permite al modelo focalizarse en las partes más relevantes de los datos de entrada al procesar los tokens. Computa la importancia de la relación entre pares de tokens en la secuencia de entrada, permitiendo que el modelo sea capaz de capturar el contexto y poner foco en la información más importante. Realizar el proceso de pruning en esta sección puede reducir la capacidad del modelo en tareas que requieran un entendimiento amplio del contexto de entrada, como puede ser la creación de resúmenes o tareas de traducción. También tiene un efecto significativo a la capacidad de generar texto de forma coherente.
Las capas MLP acompañan al mecanismo de atención y se ocupan de incrementar la capacidad del modelo de entender patrones complejos, mediante una serie de expansiones y contracciones de los datos. Puede limitar la respuesta del modelo ante datos no vistos o tareas no previstas en el entrenamiento. Es decir, pierde la capacidad de generalización y de dar respuestas coherentes, aunque no conozca los datos de entrada.
Una vez ya has decidido que sección del modelo va a ser la que vas a atacar, hay que decidir si se va a realizar widt o depth pruning. En el primero eliminaremos neurones, y en el segundo capas enteras.
Como puedes ver, el pruning de un modelo es un proceso bastante complicado, en el que se tiene que tomar muchas decisiones, y no tienes que evaluar tan solo las habilidades del modelo resultante, sino su capacidad de ser entrenado. Porque estos modelos se crean con la intención de ser entrenados, normalmente en tareas específicas, para que puedan ser más eficaces y eficientes que el modelo base utilizado en la tarea para la que han sido creados.
Características de Gated Linear Units.
La arquitectura Gated Linear Unit (GLU) es ampliamente usada en los Grandes Modelos de Lenguaje más modernos como LLama. GLU introduce un mecanismo de compuerta a nivel de elemento que permite al modelo filtrar y controlar selectivamente el flujo de información. Esta arquitectura consta de capas emparejadas, típicamente gate_proj, up_proj y down_proj (puedes ver estas capas en la estructura del modelo arriba), que trabajan juntas para realizar expansiones y contracciones de los datos que pasan por ellas.
Este mecanismo permite al modelo procesar patrones más complejos mientras mantiene la eficiencia. Sin embargo, también implica que las capas dentro de una estructura GLU están estrechamente acopladas, por lo que la poda de estas capas requiere un análisis cuidadoso.
Cualquier operación en una capa (por ejemplo, eliminar neuronas) debe reflejarse en sus capas emparejadas correspondientes. Por ejemplo, si se elimina una neurona de gate_proj, la misma neurona debe eliminarse de up_proj, y además es necesario ajustar el tamaño de la capa down_proj. Pero, aún más importante: al calcular la importancia de las neuronas para decidir cuáles conservar, también es necesario considerar el par de neuronas en ambas capas.
Si se altera el equilibrio entre estas capas, puede dar lugar a un rendimiento degradado o incluso al fallo completo del modelo, aunque tan solo se elimine un pequeño porcentaje de neuronas.
Un ejemplo con Llama 3.2.
El ejemplo se va a ver en un modelo de Llama, pero el código se ha probado también con modelos Gemma y QWen y ha funcionado perfectamente.
El código entero lo puedes encontrar en mi repositorio de Github, en el artículo voy a mostrar tan solo aquel código que hace referencia al proceso de pruning, obviando algunas funciones de soporte. En el notebook también se puede encontrar el código para evaluar los modelos y subirlos al Hub de Hugging Face.
La primera acción que he realizado con el modelo original en memoria ha sido ejecutar un pequeño prompt y guardarme el resultado, lo que me permitia comprobar de una forma muy sencilla, grafica y rapida si el modelo generado con el proceso de pruning era coherente, o si por el contrario habia perdido toda capacidad de generar un texto entendible. Os aseguro que en el primer intento, donde no respetaba la estructura GLU del modelo el texto devuelto no dejaba lugar a dudas de que el proceso de pruning tenia un error de base.
El prompt original es: “París es la capital de”, veamos la respuesta del modelo original y la que me devolvió mi primer intento de pruning.
Modelo base:
Paris is the capital of France and one of the most visited cities in the world. It is a city of art, culture, fashion, and gastronomy. The city has a rich history and is home to many famous landmarks, including the E
Primer intento, con un 20% de pruning:
Paris is the capital of of France. This is the the the the main the area of. This is the the the the the the the the the the the the the the the the city of the the France of the of the of the of
Esta claro que algo no funcionó en ese primer intento, puede parecer una tontería, pero una comprobación empírica de este tipo puede ayudarte a ahorrarte unas cuantas horas.
Empecemos viendo la función responsable de calcular la importancia de los neurones, y que por lo tanto decidirá que neurones se quedan en el modelo y cuales són eliminados.
def compute_neuron_pair_importance(gate_weight, up_weight): """ compute neuron pair importance scores (Maximum Absolute Weight) Args: - gate_weight: Weight matrix from the gate_proj layer. - up_weight: Weight matrix from the up_weight layer. Returns: - importance_scores: Importance scores for each neuron pair. """ gate_max_abs = torch.max(gate_weight, dim=1).values + torch.abs(torch.min(gate_weight, dim=1).values) up_max_abs = torch.max(up_weight, dim=1).values + torch.abs(torch.min(up_weight, dim=1).values) importance_scores = gate_max_abs + up_max_abs return importance_scores
La función recibe los pesos de una capa de tipo gate_proj y otra up_proj, que como ya he explicado trabajan en pares y por lo tanto se debe calcular conjuntamente el peso de los neurones.
El cálculo es muy sencillo se calcula el valor absoluto de los pesos de cada neuron, se tiene en cuenta tanto el valor positivo como el negativo por que en teoría, los neurones con los valores más extremos afectan más a la salida del modelo porque alteran más los valores que pasan a través de ellos.
Aquí tengo que agradecer a MariusZ su contribución que incorporó los valores mínimos al cálculo, el método funcionaba correctamente sin ellos, pero su inclusión ha mejorado el resultado.
Lo calcula por cada capa por separado, pero devuelve el valor conjunto.
La siguiente función es la responsable de crear las nuevas capas y incoporarlas al modelo en sustitución de las originales.
#Prunes a specific percentatge of neurons from the MLP (feed forward layers).
def prune_neuron_pairs(mlp, prune_percent):
"""
Reduces the dimensions of the **gate_proj**,**up_proj**, **down_proj**
layers removing the least important neurons.
Args:
- mlp: Layers to prune.
- prune_percent: Percentage of neurons to prune.
Returns:
- new_gate_proj, new_up_proj, new_down_proj: New pruned layers.
- k: New intermediate size.
"""
# Extract the weights from the MLP layers
# these weights are used to calculate each neuron's
# importance score in the next step.
gate_weight = mlp.gate_proj.weight.data.float()
up_weight = mlp.up_proj.weight.data.float()
#Compute importance stores. Neurons with higher importance scores
# are considered more important and less likely to be pruned.
importance_scores = compute_neuron_pair_importance(gate_weight, up_weight)
#Store the original number of neurons in the intermediate layer.
original_intermediate_size = gate_weight.size(0)
#Computes the number of neurons to prune.
num_neuron_pairs_to_prune = min(int(prune_percent * original_intermediate_size), original_intermediate_size - 1)
#Calculate the number of neurons to keep. The new intermediate size.
k = original_intermediate_size - num_neuron_pairs_to_prune
#Just check that there is no big error calculating k. We can't prune all the neurons.
if k <= 0:
raise ValueError(f"Invalid number of neuron pairs to keep: {k}. Adjust the prune_percent.")
#Select the neuros to keep, by obtaining the indices to keep.
_, indices_to_keep = torch.topk(importance_scores, k, largest=True, sorted=True)
indices_to_keep = indices_to_keep.sort().values
#create the new layers
new_gate_proj = nn.Linear(mlp.gate_proj.in_features, k, bias=False).to(device)
new_up_proj = nn.Linear(mlp.up_proj.in_features, k, bias=False).to(device)
new_down_proj = nn.Linear(k, mlp.down_proj.out_features, bias=False).to(device)
#copy weights to the new layers.
new_gate_proj.weight.data = mlp.gate_proj.weight.data[indices_to_keep, :]
new_up_proj.weight.data = mlp.up_proj.weight.data[indices_to_keep, :]
new_down_proj.weight.data = mlp.down_proj.weight.data[:, indices_to_keep]
#return new layers and intermediate size.
return new_gate_proj, new_up_proj, new_down_proj, k
Esta función es un poco más compleja, recibe una capa del bloque mlp y el porcentaje de pruning a aplicar. Mediante una llamada a la función compute_neuron_pair_importance decide que neurones quedarse.
Vamos por partes:
# Extract the weights from the MLP layers
# these weights are used to calculate each neuron's
# importance score in the next step.
gate_weight = mlp.gate_proj.weight.data.float()
up_weight = mlp.up_proj.weight.data.float()
Con estas dos líneas, de arriba, recuperamos los pesos de las capas actuales.
importance_scores = compute_neuron_pair_importance(gate_weight, up_weight)
Ahora se obtiene un tensor que contiene los scores de importancia calculados para cada neurona. Estos scores reflejan la contribución de cada neurona al resultado final, indicando cuáles deberíamos mantener.
#Store the original number of neurons in the intermediate layer.
original_intermediate_size = gate_weight.size(0)
#Computes the number of neurons to prune.
num_neuron_pairs_to_prune = min(int(prune_percent * original_intermediate_size), original_intermediate_size - 1)
#Calculate the number of neurons to keep. The new intermediate size.
k = original_intermediate_size - num_neuron_pairs_to_prune
Se calcula el número total de neurones a mantener, usando el porcentaje que recibimos como parámetro, y el tamaño original de las capas, como són capas de igual tamaño no hace falta almacenar el tamaño de ambas. Finalmente se calcula el nuevo tamaño de las capas intermedias.
#Select the neuros to keep, by obtaining the indices to keep.
_, indices_to_keep = torch.topk(importance_scores, k, largest=True, sorted=True)
indices_to_keep = indices_to_keep.sort().values
Estas líneas són cruciales, en ellas se usa torch para recuperar los neurones con mayor importancia, pero también se orden de mayor a menor importancia. Torch devuelve los datos en orden decreciente y se necesitan en orden creciente, que es lo que se consigue con el método sort.
Con los índices calculados se crean las nuevas capas.
#create the new layers
new_gate_proj = nn.Linear(mlp.gate_proj.in_features, k, bias=False).to(device)
new_up_proj = nn.Linear(mlp.up_proj.in_features, k, bias=False).to(device)
new_down_proj = nn.Linear(k, mlp.down_proj.out_features, bias=False).to(device)
#copy weights to the new layers.
new_gate_proj.weight.data = mlp.gate_proj.weight.data[indices_to_keep, :]
new_up_proj.weight.data = mlp.up_proj.weight.data[indices_to_keep, :]
new_down_proj.weight.data = mlp.down_proj.weight.data[:, indices_to_keep]
Primero, se crean tres capas nuevas con dimensiones ajustadas según los índices seleccionados. En new_gate_proj y new_up_proj, se conservan las dimensiones de entrada y se reducen las de salida, mientras que en new_down_proj ocurre lo contrario: se ajustan las dimensiones de entrada y se mantienen las de salida.
Estas capas se inicializan sin pesos, y en las últimas líneas se transfieren los pesos relevantes desde las capas originales a las nuevas, asegurando que solo se conserven los relacionados con las neuronas seleccionadas.
#return new layers and intermediate size.
return new_gate_proj, new_up_proj, new_down_proj, k
Finalmente se devuelven las capas nuevas.
Veamos ahora la función que se encarga de iterar sobre todas las capas y construir el modelo modificado.
#Iterates throught the model layers and applies pruning.
def update_model(model, prune_percent):
"""
It modifies each mlp layer present in model, to retain only the most
important neurons. Creating new smaller versions of each layer pruned.
Args:
- model: Model to prune.
- prune_percent: Percentage of neurons to prune.
Returns:
- model: New pruned model.
"""
new_intermediate_size = None
#loop for each model layer.
for idx, layer in enumerate(model.model.layers):
#Since each layer is a LlamaDecoderLayer it contains multiple components
# Attention, MLP and Layer norms. We're targetting MLP component
# by accesing layer.mlp.
mlp = layer.mlp
#Call the prune_neiron_pairs with the layers and receiving the pruned.
new_gate_proj, new_up_proj, new_down_proj, new_size = prune_neuron_pairs(mlp, prune_percent)
#Replace the Origiginal Layers with Pruned Layers.
mlp.gate_proj = new_gate_proj
mlp.up_proj = new_up_proj
mlp.down_proj = new_down_proj
#new_intermediate_size only needs to be set once
if new_intermediate_size is None:
new_intermediate_size = new_size
#Update the model config file.
model.config.intermediate_size = new_intermediate_size
return model
Se puede decir que no tiene secreto, recibe el modelo y el porcentaje de pruning a aplicar. Itera por cada una de las capas del capas del modelo recuperando de cada capa la sección mlp. Para cada una de las capas llama a la función prune_neuron_pairs y sustituye las capas del modelo por las devueltas por la función.
#Call the prune_neiron_pairs with the layers and receiving the pruned.
new_gate_proj, new_up_proj, new_down_proj, new_size = prune_neuron_pairs(mlp, prune_percent)
#Replace the Origiginal Layers with Pruned Layers.
mlp.gate_proj = new_gate_proj
mlp.up_proj = new_up_proj
mlp.down_proj = new_down_proj
Finalmente también se modifica la variable new_intermediate_size del fichero de configuración del modelo.
#Update the model config file. model.config.intermediate_size = new_intermediate_size
Si no modificamos este fichero el modelo no podrá ser utilizado después de guardarlo, ya sea en Hugging Face o localmente. Muchas librerías, como Transformers de Hugging Face utilizan model.config para interpretar la arquitectura del modelo. Si no coincide con la estructura real pueden fallar las operaciones que se realicen a través de ellas, ya sea fine-tuning o inferencia.
Estudiando los resultados.
Con este código he creado varios modelos y los tenéis disponibles en el HUB de Hugging Face. Tres modelos creados a partir de Llama3.2-1b a los que se les ha eliminado el 20%, 40% y 60% de los neurones de las capas MLP. Un modelo creado a partir de Gemma-2-2B pruneado al 40%. Os los podéis descargar y aparte de usarlos, podéis estudiar su arquitectura y cómo ha variado con el modelo en el que están basados.
Estudiemos qué cambios se han producido en la arquitectura al aplicar un pruning del 20% al modelo Llama3.2-b.
La arquitectura después de realizar el prunning es:
LlamaForCausalLM( (model): LlamaModel( (embed_tokens): Embedding(128256, 2048) (layers): ModuleList( (0-15): 16 x LlamaDecoderLayer( (self_attn): LlamaSdpaAttention( (q_proj): Linear(in_features=2048, out_features=2048, bias=False) (k_proj): Linear(in_features=2048, out_features=512, bias=False) (v_proj): Linear(in_features=2048, out_features=512, bias=False) (o_proj): Linear(in_features=2048, out_features=2048, bias=False) (rotary_emb): LlamaRotaryEmbedding() ) (mlp): LlamaMLP( (gate_proj): Linear(in_features=2048, out_features=6554, bias=False) (up_proj): Linear(in_features=2048, out_features=6554, bias=False) (down_proj): Linear(in_features=6554, out_features=2048, bias=False) (act_fn): SiLU() ) (input_layernorm): LlamaRMSNorm((2048,), eps=1e-05) (post_attention_layernorm): LlamaRMSNorm((2048,), eps=1e-05) ) ) (norm): LlamaRMSNorm((2048,), eps=1e-05) (rotary_emb): LlamaRotaryEmbedding() ) (lm_head): Linear(in_features=2048, out_features=128256, bias=False) )
La estructura del modelo permanece inalterada salvo por el tamaño de las capas intermedias en las capas MLP. Como podéis ver las capas gate_proj y up_proj han pasado de tener 8192 features a 6554, y la capa down_proj ha realizado el mismo cambio pero en las features de entrada.
El cambio está totalmente en línea con lo que hace el código que es modificar estas capas manteniendo los neurones que són más importantes para la ejecución del código. Si le quitamos un 20% a 8192 nos dan 6553,6, por lo se comprueba que el porcentaje de neurones eliminados es el correcto.
Veamos como se ha comportado el modelo pruneado con el prompt de prueba:
Paris is the capital of France. It is also one of the most beautiful cities in the world. There is so much to see and do in Paris that it is impossible to cover it all in one day. However, there are some things you
No es la misma respuesta que la obtenida con el modelo original, pero mantiene la coherencia, lo que nos da una indicación que el Modelo buena parte de sus capacidades intactas, y lo que es más importante, que podría recuperar las pérdidas mediante un proceso de Knowledge distillation o Fine-Tuning.
Pero aparte de esta comprobación, también he evaluado algunos rankings más comunes, veamos cómo afecta al modelo diferentes grados de pruning en sus capacidades.

Como se puede observar, el efecto de la poda ha sido algo asimétrico. Las tareas evaluadas mediante la prueba BoolQ no han experimentado una degradación significativa, tan solo una caída del 2 % aproximadamente en un modelo que perdió el 35 % de su peso.
En contraste, el impacto en la prueba Lambada ha sido notable, con una caída en la precisión de más del 50 %. Esto indica que el modelo conserva gran parte de su capacidad de comprensión, pero tiene dificultades con pruebas que requieren una generación más abierta.
BoolQ simplemente presenta al modelo un texto y una pregunta a la que debe responder con Sí/No. Es una prueba enfocada en medir la capacidad del modelo para entender relaciones dentro del texto de entrada.
Lambada, por otro lado, le pide al modelo que adivine la última palabra de un párrafo, una tarea compleja donde la palabra final pone a prueba la habilidad del modelo en modelado del lenguaje avanzado.
Los resultados del modelo podado al 20 % en el Hugging Face Open LLM Leaderboard son quizás aún más sorprendentes, ya que supera tanto a su modelo base como al ampliamente utilizado TinyLlama-1.1V-v1.1.
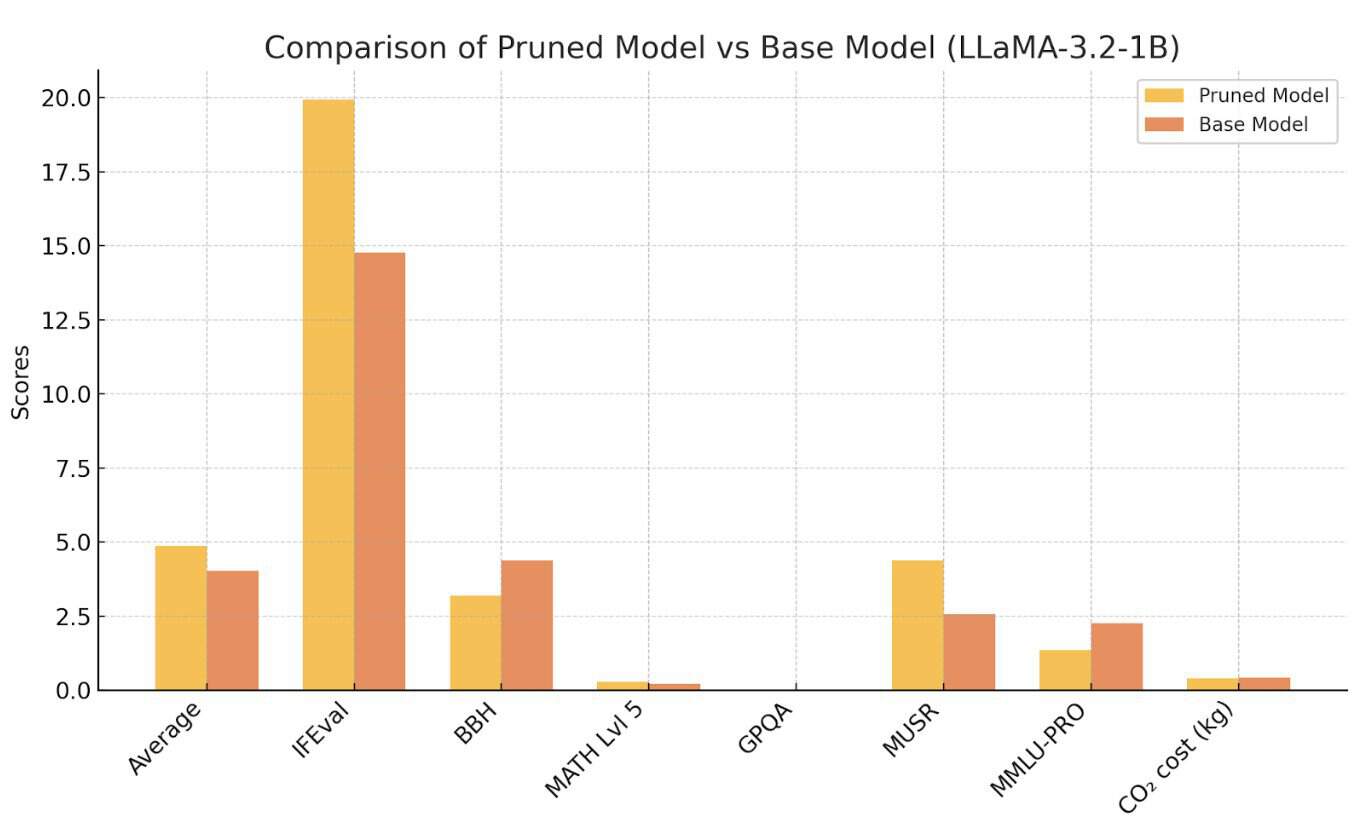
Veamoslo en este gráfico.
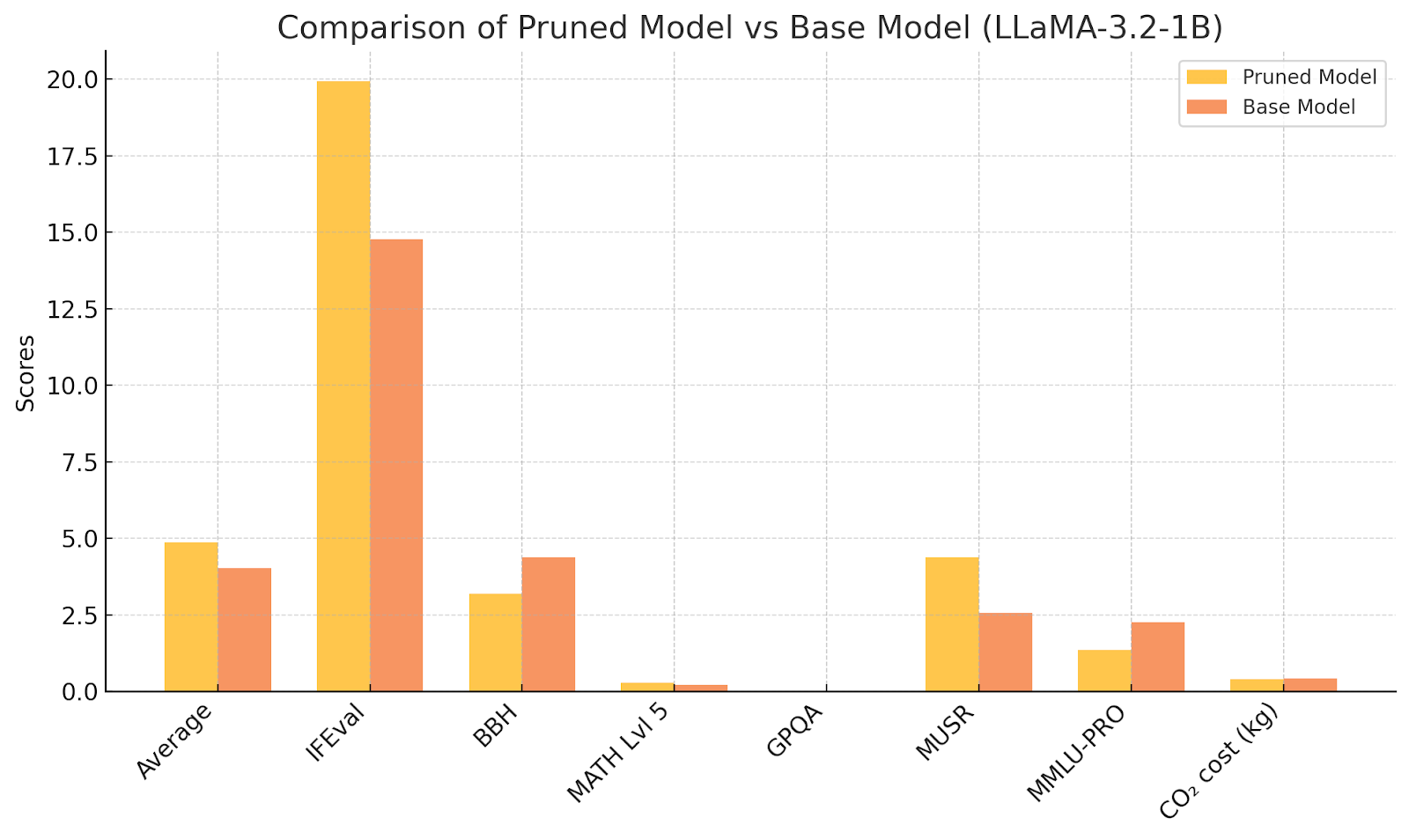
Al analizar este gráfico, podemos extraer las siguientes conclusiones: el modelo podado supera al modelo base en promedio (4.86 frente a 4.03). Esto sugiere que el proceso de poda ha logrado retener o incluso mejorar el rendimiento en áreas clave mientras reduce la redundancia.
Fortalezas del Modelo Podado:
- IFEval: Una mejora significativa (19.94 frente a 14.78) sugiere que la poda redujo el sobreajuste o mejoró la capacidad del modelo para extraer información de manera eficiente.
- MUSR: Un mejor rendimiento (4.39 frente a 2.56) indica que el modelo podado maneja mejor tareas que requieren razonamiento sobre contextos largos o comprensión narrativa, posiblemente debido a pesos más enfocados.
Debilidades del Modelo Podado:
- BBH: Una disminución en el razonamiento bajo incertidumbre (3.19 frente a 4.37) puede indicar que la poda redujo la capacidad del modelo para manejar escenarios ambiguos o de múltiples interpretaciones.
- MMLU-PRO: Una caída en las tareas específicas de dominios profesionales (1.36 frente a 2.26) podría deberse a la eliminación de pesos cruciales para retener conocimientos detallados en áreas específicas.
Eficiencia Energética:
El modelo podado es ligeramente más eficiente en términos de energía (0.4 kg frente a 0.42 kg de CO₂), alineándose con el objetivo de reducir la sobrecarga computacional mientras mantiene un rendimiento competitivo.
Haria falta un estudio mucho más completo de los resultados del modelo en los diferentes rankings, pero con estos resultados parece claro que estamos ante un modelo bastante prometedor que podría mejorar mucho con un buen proceso de knowledge distillation o fine-tuning. Lo más importante es que estos resultados son consistentes con el procedimiento de pruning realizado sobre las capas MLP.
These results are consistent with the functionality of the MLP layers that were pruned.
Conclusiones.
El proceso de pruning de los modelos ha sido un éxito, esta forma de tratar las capas GLU nos permite realizar un pruning que mantiene gran parte de la capacidad del modelo, reduciendo su tamaño y consumo de forma considerable.
Hay que recordar que los resultados de los test se han obtenido con el modelo pruneado sin hacerle pasar por un proceso de recuperación de capacidades, como Knowled Distillation o Fine-Tuning, que suele ser lo normal en modelos que han sufrido un proceso de pruning.
Lineas de evolución.
Hay muchas formas de pruning que se pueden probar, quizás la más inmediata sea la de realizar un depth pruning eliminando las capas que menos aportan al modelo.
Otra línea de investigación necesaria sería someter a estos modelos a un proceso de Knowdledge distillation y ver si conservan las capacidades de aprender nuevas cosas y por lo tanto puede acercar su rendimiento al del modelo base en los test que más rendimiento ha perdido.
La creación de Modelos más ligeros que incluso pueden llegar a superar los modelos en los que se han basado es un campo que cada vez está atrayendo más atención, ya que muchas empresas quieren realizar tareas específicas que los Grandes Modelos pueden hacer sin problemas y con una gran calidad, pero no quieren, o pueden, mantener la infraestructura que estos demanda.
Este articulo forma parte del curso sobre Grandes Modelos de Lenguaje que antengo en Github:
https://github.com/peremartra/Large-Language-Model-Notebooks-Course
Soy autor del libro: Large Language Models Projects: Apply and Implement Strategies for Large Language Models (Apress, 2024). Que puedes encontar en Amazon y en Springer Link. Si te ha gustado el contenido del articulo y te gusta el curso en GitHub te gustará el libro!
Una GAN, como ya sabemos, nos permite generar imágenes similares a las del Dataset con el que ha sido entrenada. Read more

Antes de listar los cursos, dejadme decir una cosa: no hay que ser un experto matemático para aprender o trabajar Read more
Este es el segundo artículo del Tutorial de Redes Generativas Adversarias. En el primero se vio como crear una DCGAN Read more

LoRA es una de las técnicas más eficientes y efectivas de Fine-Tuning aplicable a Grandes Modelos de Lenguaje que existe Read more