Lo más normal es que cuando empezamos a trabajar con Tensorflow utilicemos el formato secuencial para crear Modelos usando la librería Keras. Con los modelos secuenciales podemos solucionar multitud de problemas en todos los campos del deep Learning, tanto sean de reconocimiento o clasificación de imágenes, Natural Language Processing, Forecasting de series…. son unos modelos lo suficientemente potentes como para ser usados en la mayoría de los problemas.
Pero hay veces que necesitamos ir un poco mas lejos en el uso de Keras con TensorFlow y podemos usar el API para la creación de modelos, que nos abre un mundo muy amplio, con muchas más posibilidades, que no teníamos al usar modelos secuenciales.
En este artículo vamos a ver la creación de un Modelo capaz de predecir dos variables diferentes usando los mismos datos, y el mismo proceso de aprendizaje, compartiendo gran parte de las capas del modelo.
Es decir, vamos a crear un modelo Multi Salida con dos ramas de capas. Tal como podemos ver en la imagen:
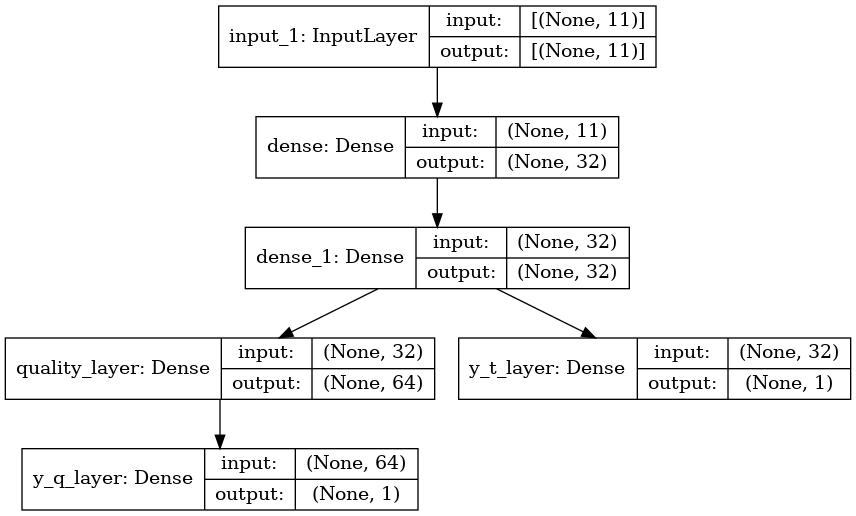
El modelo está formado por una capa de entrada, seguida por dos capas densas que son compartidas. Estas tres capas son la parte común del modelo. A partir de aquí, el modelo, se divide en dos ramas diferentes. En una de las ramas encontramos la capa de salida de la variable de clasificación. La otra rama está compuesta por una capa Densa y la capa de salida que predice la variable re regresión.
El código completo se puede encontrar en Kaggle: https://www.kaggle.com/code/peremartramanonellas/guide-multiple-outputs-with-keras-functional-api. En un Notebook qué se puede ejecutar y que utiliza un Dataset para predecir el tipo de vino como variable de clasificación y la calidad del vino como variable de regresión.
En este artículo vamos a ver tan solo como generar y ejecutar el modelo. El tratamiento de datos y la posterior evaluación del modelo, así como ideas de cómo mejorarlo, se pueden encontrar en el notebook de Kaggle.
El problema a solucionar.
He usado un Dataset de Kaggle que contiene información sobre vinos. Son datos en formato tabular, con 11 columnas que se pueden considerar features y dos que serán nuestras labels.
Como primer label he seleccionado la calidad del vino (quality), que va de 0 a 9 y he decidido tratarla como si fuera una variable de regresión y no una de clasificación, ya que es una variable en la que el incremento es importante y significa que el vino es mejor.
El segundo label es el tipo de vino (type), que indica si el vino es blanco o negro. Esta es claramente una variable de clasificación. Así que tenemos dos variables de diferente tipo a predecir en un solo modelo.
type | fixed acidity | volatile acidity | citric acid | residual sugar | chlorides | free sulfur dioxide | total sulfur dioxide | density | pH | sulphates | alcohol | quality | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 7.0 | 0.270 | 0.36 | 20.7 | 0.045 | 45.0 | 170.0 | 1.00100 | 3.00 | 0.45 | 8.8 | 6 |
| 1 | 0 | 6.3 | 0.300 | 0.34 | 1.6 | 0.049 | 14.0 | 132.0 | 0.99400 | 3.30 | 0.49 | 9.5 | 6 |
| 2 | 0 | 8.1 | 0.280 | 0.40 | 6.9 | 0.050 | 30.0 | 97.0 | 0.99510 | 3.26 | 0.44 | 10.1 | 6 |
| 3 | 0 | 7.2 | 0.230 | 0.32 | 8.5 | 0.058 | 47.0 | 186.0 | 0.99560 | 3.19 | 0.40 | 9.9 | 6 |
| 4 | 0 | 7.2 | 0.230 | 0.32 | 8.5 | 0.058 | 47.0 | 186.0 | 0.99560 | 3.19 | 0.40 | 9.9 | 6 |
| … | … | … | … | … | … | … | … | … | … | … | … | … | … |
| 6492 | 1 | 6.2 | 0.600 | 0.08 | 2.0 | 0.090 | 32.0 | 44.0 | 0.99490 | 3.45 | 0.58 | 10.5 | 5 |
| 6493 | 1 | 5.9 | 0.550 | 0.10 | 2.2 | 0.062 | 39.0 | 51.0 | 0.99512 | 3.52 | NaN | 11.2 | 6 |
| 6494 | 1 | 6.3 | 0.510 | 0.13 | 2.3 | 0.076 | 29.0 | 40.0 | 0.99574 | 3.42 | 0.75 | 11.0 | 6 |
| 6495 | 1 | 5.9 | 0.645 | 0.12 | 2.0 | 0.075 | 32.0 | 44.0 | 0.99547 | 3.57 | 0.71 | 10.2 | 5 |
| 6496 | 1 | 6.0 | 0.310 | 0.47 | 3.6 | 0.067 | 18.0 | 42.0 | 0.99549 | 3.39 | 0.66 | 11.0 | 6 |
Visto el Dataset pasamos a la construcción del modelo.
#Empezamos con una capa de entrada de tipo Input.
inputs = tf.keras.layers.Input(shape=(11,))
#Añadimos dos capas densas, que serán comunes para todo el modelo.
#La primera capa a la derecha recibe la capa (inputs). Mientras que la segunda
#recibe el conjunto de capas (x).
x = Dense(units=32, activation='relu')(inputs)
x = Dense(units=32, activation='relu')(x)
#Añadimos la capa de salida para la variable de clasificación.
#Como podéis ver recibe el conjunto de capas (x). Que contiene
#la capa de entrada y las capas densas.
y_t_layer = Dense(units = 1, activation='sigmoid', name='y_t_layer')(x)
#Aquí el modelo empieza la segunda rama. Con una capa densa que recibe el conjunto de capas (x)
#Con esto ya tenemos que a partir de la última capa que forma el conjunto de capas (x)
#se ha añadido una capa de salida y ahora esta capa densa.
quality_layer=Dense(units=64, name='quality_layer', activation='relu')(x)
#La capa de salida para la variable que predice la calidad del vino. Se añade déspues del grupo
#de capas(quality_layer) que contiene todas las capas de (x) mas la densa especifica de esta rama.
y_q_layer = Dense(units=1, name='y_q_layer')(quality_layer)
#TPOara crear el modelo tenemos que indicar las entradas y salidas.
#En este modelo tenemos tan solo una entrada, pero con el API podemos definir modelos multientrada.
#El nombre de los outputs es el mismo que el de las variables y los nombres internos de las capas.
model = Model(inputs=inputs, outputs=[y_q_layer, y_t_layer])
#He probado con dos optimizadores. Sin jugar demasiado me ha funcionado mejor Adam.
optimizer = tf.keras.optimizers.RMSprop(learning_rate=0.0001)
#optimizer = tf.keras.optimizers.Adam()
#Al compilar el modelo se le tiene que pasar dos diccionarios que contenga
#las funciones de loss y métricas de las variables a predecir. El nombre
# de las variables del diccionario debe coincidir con el nombre interno de las capas.
#To compile the model we use two dictionaries, to indicate the loss functions and metrics
#for each output layer. Note that the name of the layer must be the same than the
#internal name of the layer.
model.compile(optimizer=optimizer,
loss = {'y_t_layer' : 'binary_crossentropy',
'y_q_layer' : 'mse'
},
metrics = {'y_t_layer' : 'accuracy',
'y_q_layer': tf.keras.metrics.RootMeanSquaredError()
}
)
Como se puede ver, crear un modelo de este tipo no es nada complicado y nos abre un mundo de posibilidades nuevas si lo comparamos con los modelos secuenciales.
Se pueden encontrar todas las explicaciones en los comentarios del código. Pero me gustaría remarcar un par de cosas.
Suelo emplear el mismo nombre para el nombre interno de las capas y las variables que lo contienen. No tan solo para que código quede más claro. Cuando indicamos la función de loss y las métricas debemos utilizar el nombre interno de la capa para relacionaros. Al indicar los outputs debemos indicar el nombre de las variables que contienen las capas. Prefiero tener siempre el mismo y me ahorro confusiones.
Podemos usar diferentes funciones de perdida y métricas para cada una de los outputs del modelo. Se indican en dos listas, una para las funciones de perdida, y otra para las métricas, que se le pasan a la función compile del modelo.
model.compile(optimizer=optimizer,
loss = {'y_t_layer' : 'binary_crossentropy',
'y_q_layer' : 'mse'
},
metrics = {'y_t_layer' : 'accuracy',
'y_q_layer': tf.keras.metrics.RootMeanSquaredError()
}
)¿Para qué podemos usar los modelos Multi Output?
No pretendo dar una respuesta completa, ya que se trata tan solo de mi visión, y Data Scientists con más experiencia pueden encontrarles más utilidades.
Este tipo de modelo es muy útil en entornos donde se deba realizar entrenos periódicos con gran volumen de datos para predecir más de una variable. El tiempo ahorrado si lo comparamos con entrenar dos o tres modelos diferentes puede ser muy significativo, no tan solo en tiempo, sino en coste.
También pueden ahorrar mucho tiempo y proceso en entornos donde se deban ejecutar una gran cantidad de predicciones de forma repetitiva y el resultado de estas sea de más de una variable.
Como contrapartida cuestan más de tunear, ya que por ejemplo es más complicado dar con un learning rate que pueda ser óptimo para todas las variables.
Conclusión.
Un tipo de modelo que es sencillo de crear y puede ahorrar mucho tiempo de proceso.
Espero ir publicando, a partir de ahora, muchas más técnicas un poco más avanzadas de Tensorflow, así que si os interesa el tema podéis suscribiros al blog, o seguirme en mi perfil de Kaggle.

Comments