
En este tercer post de donde explico los pasos que hago para preparar la certificación de Tensorflow Developer le toca al NLP.
En esta occasion he preparado dos notebooks, uno para binary classification y otro para Multi Classification. ¿Podría haberlo hecho en uno? Creo que sí! Pero para el examen me viene bien tenerlo separado. He estado probando multitud de modelos, creo que más o menos unos 10 en cada notebook, y tenerlos todos en un solo notebook era muy incomodo.
Los notebooks los podéis encontrar en el repositorio de Github preparado a tal fin.
Puntos Cubiertos de NLP del examen TensorFlow Developer.
(4) Natural language processing (NLP)
You need to understand how to use neural networks to solve natural language processing problems
using TensorFlow. You need to know how to:
❏ Build natural language processing systems using TensorFlow.
❏ Prepare text to use in TensorFlow models.
❏ Build models that identify the category of a piece of text using binary categorization
❏ Build models that identify the category of a piece of text using multi-class categorization
❏ Use word embeddings in your TensorFlow model.
❏ Use LSTMs in your model to classify text for either binary or multi-class categorization.
❏ Add RNN and GRU layers to your model.
❏ Use RNNS, LSTMs, GRUs and CNNs in models that work with text.
❏ Train LSTMs on existing text to generate text (such as songs and poetry)
No esta mal, esta todo cubierto, menos la predicción de texto, que lo dejo para un notebook siguiente.
Puntos claves de los notebooks.
Las funciones de soporte son las que ya he usado para los notebooks de reconocimiento de imagen. Las podéis ver todas en github, o pasaros por los artículos anteriores (los dejo al final de este) donde están explicadas.
Lo principal en NLP es preparar los datos. No podemos pasarle los textos directamente al modelo. Para esto he preparado varias funciones.
#clear the text
import re
def cleanText(text):
whitespace = re.compile(r"\s+")
web_address = re.compile(r"(?i)http(s):\/\/[a-z0-9.~_\-\/]+")
user = re.compile(r"(?i)@[a-z0-9_]+")
text = whitespace.sub(' ', text)
text = web_address.sub('', text)
text = user.sub('', text)
text = re.sub(r"\[[^()]*\]", "", text)
text = re.sub("\d+", "", text)
text = re.sub(r'[^\w\s]','',text)
text = re.sub(r"(?:@\S*|#\S*|http(?=.*://)\S*)", "", text)
return text.lower()
Lo primero va a ser limpiar las frases que recupero del Dataset. Para esos esta pequeña función en Python lo que hace es eliminar los caracteres especiales y pasar la frase a minúsculas. Vale, es posible que pierda algo de expresividad, pero si ya es complicado interpretar el sentimiento en texto plano, si tenemos que empezar a diferenciar entre mayusculas y minúsculas y tener en cuenta corchetes o paréntesis, la cosa se va a complicar demasiado. No hay que perder de vista que estoy preparandome para un examen que dura 5 horas en el que hay cuatro modelos a solucionar. Tampoco pueden ser problemas super complicados.
# Initialize the Tokenizer class
tokenizer = Tokenizer(num_words = 14000, oov_token='<OOV>')
# Generate the word index dictionary for the training sentences
tokenizer.fit_on_texts(list(x_train))
word_index = tokenizer.word_index
print(f'number of words in word_index: {len(word_index)}')
# Generate and pad the training sequences
sequences = tokenizer.texts_to_sequences(x_train)
padded = pad_sequences(sequences,maxlen=max_length, truncating=trunc_type)
# Generate and pad the test sequences
validation_sequences = tokenizer.texts_to_sequences(x_val)
validation_padded = pad_sequences(validation_sequences,
maxlen=max_length, truncating=trunc_type)
y_train = np.array(y_train)
y_val = np.array(y_val)
Primero creo el tokenizer. Cómo primer parámetro recibe el número máximo de palabras que queremos que contenga. Como más palabras mas complicado y lento va a ser el aprendizaje. En el segundo parámetro recibe la cadena de texto a usar cuando tenga que sustituir una palabra que no esta en el diccionario. Se suele usar OOV que en inglés significa: Out Of Vocabulary.
Con el tokenizer y su función fit_on_texts generamos la lista de palabras, para ellos le pasamos todo el texto de nuestro juego de training. Atención! Tan solo las de training. No pasemos el dataset entero, hay que quitar antes las frases que queremos usar en el proceso de validación. Porque sino estaremos falseando los datos.
La tokenización usada ha sido a nivel de palabra, que se podía hacer por sub-palabras (subword) o letras. Pero en la descripción de los temas que entran en el examen dejan muy claro que hay que saber usar Word tokenization.
Un ejemplo:
# Generate the word index dictionary tokenizer.fit_on_texts(["Mi hamster me mima", "Mi gato me araña"])
Genera el diccionario:
number of words in word_index: 7
word_index: {‘<OOV>’: 1, ‘mi’: 2, ‘me’: 3, ‘hamster’: 4, ‘mima’: 5, ‘gato’: 6, ‘araña’: 7}
Una vez el diccionario ya esta creado toca paddear las frases. Sustituye las palabras por el valor numerico asignado en el diccionario, y las rellena con 0’s o recorta dependiendo de la longitud maxima que le hemos indicado a la función pad_sequences.
Continuo con el ejemplo:
sequences = tokenizer.texts_to_sequences(["Mi perro me ladra", "Mi gato me sigue"]) padded = pad_sequences(sequences, padding='post', maxlen=7)
sample headline: Mi perro me ladra padded sequence: [2 6 3 1 0 0 0]
si veis ha creado la frase sustituyendo las palabras por sus valores en el diccionario, no ha encontrado ladra y le puesto un 1, que es el OOV, y ha rellenado con 0s por detrás hasta la longitud máxima.
Bueno, pues este proceso de pasar de frases a algo que un modelo de deeplearning puede entender es el principal y diferencial en problemas de NLP.
Los modelos usados.
No puedo ponerlos todos, he usado una barbaridad de modelos diferentes. Se pueden ver en el repositorio de github, con sus gráficos u números. En los dos casos, clasificación binaria y clasificación múltiple, el problema más grande es el de Overfitting y se ha solucionado de una manera bastante parecida.
Los dos mejores modelos del Notebook de clasificación binaria de sentimientos en Lenguaje
Dataset usado: https://www.kaggle.com/competitions/nlp-getting-started/data?select=train.csv
Notebook en Github: https://github.com/oopere/TensorFlowCertification/blob/main/NLPBinary.ipynb
Es un dataset muy simple con muy pocos datos, por lo que complicado obtener un modelo sin Overfitting.
El mejor resultado lo he conseguido con un modelo creado con Transfer learning a partir del un modelo universal sentence encoder que viene con Keras. Pero se sale del propósito del examen, aunque esta en el notebook en github.
El modelo que mejor ha funcionado ha sido uno en el que he usado diversas capas de Dropout para evitar el Overfitting.
tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim, input_length=max_length),
tf.keras.layers.SpatialDropout1D(0.4),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(64, dropout = 0.8, return_sequences=True)),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(32, dropout = 0.5, return_sequences=True)),
tf.keras.layers.Bidirectional(tf.keras.layers.GRU(8,return_sequences=False)),
tf.keras.layers.Dropout(0.4),
tf.keras.layers.Dense(1, activation='sigmoid')]),
Justo después del Embedding he usado una capa SpatialDropout y tiene buena parte de la culpa de que este sea el mejor modelo de los probados. SpatialDropout aplica el Dropout a toda una capa del mapa de features. Al aplicarlo casi al principio se consigue reducir la correlación entre features vecinas.
Muy importante para el éxito ha sido usar el parámetro dropout dentro de la capa Bidireccional LSTM.
Finalmente aplico un Dropout normal antes de la capa de clasificicación.
Ya lo veis, tres métodos diferentes de dropout para mirar de reducir el Overfitting…. y ha funcionado, no perfectamente, pero no del todo mal.
También hay que tener en cuenta que en el examen el tipo de entreno esta muy limitado, por lo que modelos que combinan capas bidireccionales con dropouts recursivos que necesiten de horas de entreno para cada época están totalmente descartados.
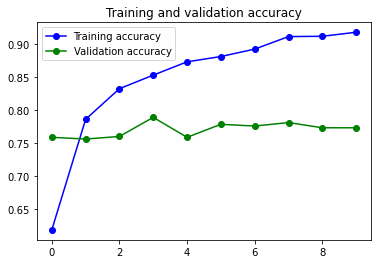
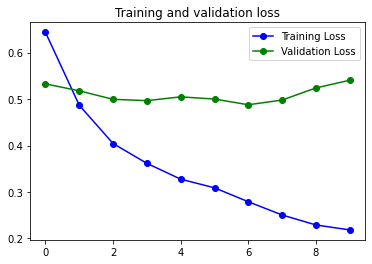
14s 67ms/step - loss: 0.2182 - accuracy: 0.9174 - val_loss: 0.5407 - val_accuracy: 0.7727
El segundo modelo que mejor ha funcionado es un modelo increiblemente sencillo.
tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim, input_length=max_length),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(6, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')]),
El modelo es muy sencillo, y no usa capas LSTM ni Bidireccionales. Es decir que no se tiene en cuenta la posición de las palabras en el texto para analizar su sentimiento. Este modelo posiblemente ha funcionado bastante bien por las características del Dataset. Con mas datos hubieran funcionado mejor otros modelos más complejos.
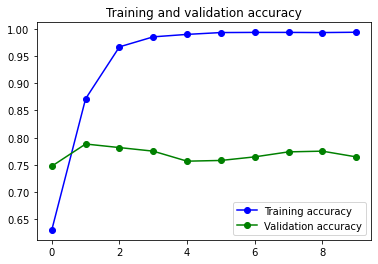
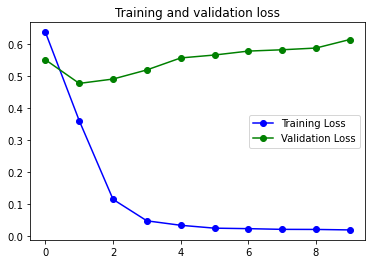
2s 10ms/step - loss: 0.0200 - accuracy: 0.9937 - val_loss: 0.6146 - val_accuracy: 0.7648
El tiempo de entreno es realmente bueno. Tengo que decir, que lo he entrenado en mi máquina, un Mac M1 Pro de 16 núcleos de GPU que realmente es un máquina impresionante, y tarda menos que los entrenos realizados en la versión de pago de Google Colab.
Los mejores modelos en el notebook de clasificación múltiple de NLP.
Dataset: https://www.kaggle.com/competitions/sentiment-analysis-on-movie-reviews/data
Notebook de clasificación múltiple de sentimientos en github: https://github.com/oopere/TensorFlowCertification/blob/main/NLPMulti.ipynb
tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim, input_length=max_length),
tf.keras.layers.SpatialDropout1D(0.4),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(64, dropout = 0.8, return_sequences=True)),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(32, dropout = 0.5, return_sequences=False)),
tf.keras.layers.Dropout(0.4),
tf.keras.layers.Dense(5,activation='softmax')]),
El modelo que mejor ha funcionado ha sido el mismo que en el problema de clasificación binaria, pero eliminando la capa de GRU. Hay que tener en cuenta que tan solo estoy entrenando 10 épocas. Así que no tan solo hay que mirar el resultado final, sino cómo evoluciona la curva, y realmente parece que este modelo tan solo tiene que disponer de mas tiempo de ejecución para mejorar.
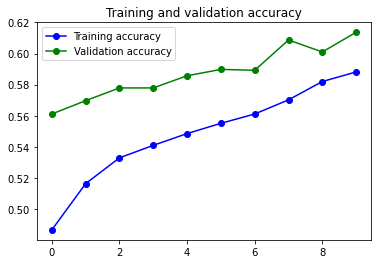
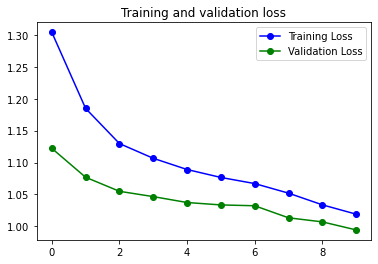
9s 107ms/step - loss: 0.8181 - accuracy: 0.6642 - val_loss: 0.8873 - val_accuracy: 0.6510
Aunque el resultado final no sea espectacular esta claro que la curva de accuraccy va subiendo y la de loss aun esta bajando, por lo que tan solo haría falta entrenar más el modelo para obtener mejores números.
El segundo mejor modelo, es exactamente él mismo, pero con la capa de GRU.
tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim, input_length=max_length),
tf.keras.layers.SpatialDropout1D(0.4),
#tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(32, dropout = 0.8, recurrent_dropout=0.8, return_sequences=True)),
#tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(16,dropout = 0.5,recurrent_dropout=0.5,return_sequences=True)),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(64, dropout = 0.8, return_sequences=True)),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(32, dropout = 0.5, return_sequences=True)),
tf.keras.layers.Bidirectional(tf.keras.layers.GRU(8,return_sequences=False)),
tf.keras.layers.Dropout(0.4),
tf.keras.layers.Dense(5,activation='softmax')]),

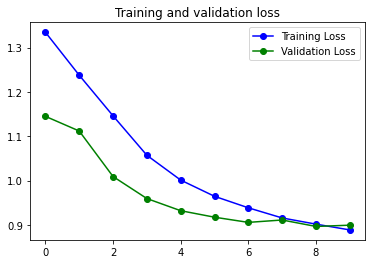
38s 137ms/step - loss: 0.8886 - accuracy: 0.6414 - val_loss: 0.8992 - val_accuracy: 0.6456
Aunque el resultado final no sea tan bueno como el del modelo al que he eliminado la capa de GRU, la curva es casi mejor…. el overfitting es inexistente. Por lo que quizás este tendría que ser el mejor modelo. Es curioso coo una capa de GRU es capaz de producir esta reducción del Overfitting. Una capa de GRU es muy similar a una LSTM pero suele funcionar mejor con Datasets pequeños.
Acabando.
Bueno, creo que el analisis de sentimiento den texto, tanto clasificaciones binarias como multiples, esta bastante bien cubierto.
Tengo ejemplos de cómo tratar los datos, un monton de modelos, dos ejemplos diferentes de Transfer Learning. Los Datasets del examen no puden ser muy grandes ni muy complejos, y yo he usado dos datasets pequeños…. lo veo bien!
En el próximo Notebook voy a tratar el tema de generación de texto predictivo. Os dejo las entradas anterioreS:
Comments