En este artículo vamos a combinar dos de las tecnologías más en moda actualmente, las bases de datos vectoriales y los grandes modelos de lenguaje.
Esta combinación suele usarse para poder usar documentación propia, o quizás bases de datos de conocimiento empresariales, que el modelo de lenguaje no tiene aprendida, y queremos que sea tenida en cuenta en la respuesta que genera el modelo.
Justamente este es el caso de uso que vamos a ver. Los pasos a seguir serán:
- Crearemos la base de datos de Vectores usando ChromaDB.
- Almacenaremos información en ella.
- Recuperaremos la información realizando una consulta.
- Generaremos un prompt extendido usando esta información.
- Cargaremos un modelo desde Hugging Face.
- Pasaremos el prompt al Modelo.
- Este nos devolverá la respuesta teniendo en cuenta la información pasada.
Este proceso se conoce como enriquecimiento de prompts con contexto propio. Es una forma de que el modelo trabaje con nuestra información sin tener que ejecutar un Fine-tunning del mismo
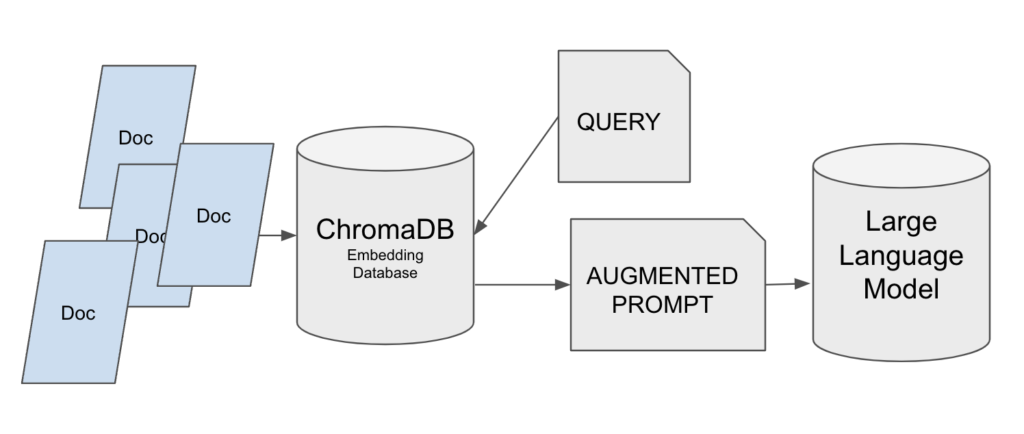
Pero antes de empezar vamos a ver una breve introducción a cómo funcionan las bases de datos Vectoriales.
Bases de datos Vectoriales, ¿cómo funcionan?
Lo primero es que, como su nombre indica, contienen Vectores, y nosotros tenemos que transformar el texto que tenemos en información que pueda ser contenida en estas herramientas. Es decir, pasar nuestro texto a vectores.
Hay varios enfoques diferentes, pero en resumen todos convierten una secuencia de texto, que pueden ser palabras, silabas o frases en vectores.
Estos son vectores multidimensionales, y como no puede ser de otra forma se puede calcular la diferencia existente entre un vector u otro, o se puede buscar que vectores están más cerca de uno en concreto.
Con esta información ya podemos adivinar, grosso modo, como funciona:
- Convertimos el texto en Vectores y lo guardamos.
- Convertimos el texto a buscar en Vectores y comparamos.
- Nos devuelve los vectores más cercanos.
- Se convierten estos vectores en texto.
¡Olvidemos las búsquedas de texto! Todo son comparaciones de Vectores.
Como ya habréis adivinado, el proceso de convertir texto a vectores debe ser el mismo para el texto almacenado que para el texto a buscar, si no, la comparación no tendría sentido.
Este tipo de bases de datos están tomando cada vez más importancia, ya que no tan solo son idóneas para casos como el nuestro en el que buscaremos noticias relacionadas, sino que pueden ser usadas para cualquier sistema de recomendación.
Los vectores son meros números, con lo que no tienen que originarse siempre a partir de texto. Podríamos guardar películas transformadas en vectores, junto a sus metadatos, y buscar las más parecidas. O incluso identificar un patrón que nos permita recomendar una película teniendo en cuenta las visualizaciones del usuario. Esperad… no vaya a ser que Netflix también las esté usando para su sistema de recomendación. ¿Nos jugamos algo?
¿Qué tecnología usaremos?
En cuanto a base de datos he seleccionado ChromaDB. Es una de las últimas bases de datos en aparecer y se ha popularizado muy rápidamente. ¡Ya veréis que su uso es extremadamente sencillo! Realmente no vamos a enterarnos de nada, casi todo lo hace ella. Es Open Source y puede integrarse con LangChain, cosa importante, ya que en futuros artículos usaremos LangChain para ir construyendo soluciones cada vez más complejas.
El modelo lo vamos a obtener de Hugging Face. Concretamente, he usado dolly-v2-3b. Este es la versión más pequeña del modelo Dolly. Recomiendo siempre usar la versión small de los modelos.
Personalmente, a mí me gusta probar diferentes modelos cada vez que tengo la oportunidad, y en Hugging Face podemos encontrar infinidad de ellos.
Si queréis probar alguno diferente podéis usar el buscador de modelo de Hugging Face y fijaros en que esté entrenado para text-generation.
Al usar un modelo de Hugging Face vamos a necesitar la librería Transformers y varias de sus herramientas.
Empezamos con el proyecto.
El código lo podéis encontrar en un Notebook en Kaggle, donde lo podéis copiar, ejecutar y jugar con él. También está disponible en GitHub, en un repositorio donde guardo todos los notebooks del curso de Grandes Modelos de Lenguaje junto a sus artículos en la revista Towards.ai.
https://www.kaggle.com/code/peremartramanonellas/use-private-data-with-llm-using-vector-database
https://github.com/peremartra/Large-Language-Model-Notebooks-Course
Si estáis interesados en ir siguiendo el curso completo lo mejor es que os suscribáis al Repositorio de Github, así recibiréis las notificaciones de nuevas lecciones o modificaciones de las actuales.
Importamos las librerías necesarias.
Para empezar vamos a necesitar instalar unos cuantos packages de python,
- sentence-transformers: Esta librería es necesaria para transformar las sentencias en vectores de longitud fija, es decir, para el embedding.
- xformers: Este paquete provee de diversas librerías y utilidades que facilitan el trabajo con modelos de la librería transformers. Aunque no vayamos a usarla directamente, si no la instalamos recibiremos un mensaje de error al intentar trabajar con el modelo.
- chromadb: Nuestra base de datos de vectores. Es sencilla de usar, Open Source, rápida. Posiblemente, la base de datos de vectores más usada para guardar embeddings.
!pip install sentence-transformers !pip install xformers !pip install chromadb
Las siguientes librerías estoy seguro de que las conocéis: Numpy y Pandas. Posiblemente, las dos librerías de python más utilizadas en Data Science. Numpy es una librería muy potente de cálculo. Pandas es la librería más empleada para manipulación de datos.
import numpy as np import pandas as pd
Cargar el Dataset.
He preparado el notebook para que pueda funcionar con tres Datasets diferentes disponibles en Kaggle. Todos los Datasets contienen noticias, pero en formatos diferentes. Dos de ellos contienen tan solo un resumen de la noticia, mientras que el tercero dispone del texto completo.
https://www.kaggle.com/datasets/kotartemiy/topic-labeled-news-dataset
https://www.kaggle.com/datasets/gpreda/bbc-news
https://www.kaggle.com/datasets/deepanshudalal09/mit-ai-news-published-till-2023
El único motivo de haber preparado el Notebook para trabajar con tres Datasets diferentes es permitir que se pueda jugar con ellos de una forma sencilla y se vea cómo reacciona la solución a diferentes inputs. No dudéis en probar tantos Datasets como queráis.
Como en Kaggle, o Colab, trabajamos con recursos limitados, he puesto un límite al número de noticias a cargar. Es límite lo contiene la variable MAX_NEWS.
El nombre del campo que contiene la noticia lo he puesto en la variable DOCUMENT, y lo que podrían ser considerados como metadata, o categorías, en la variable TOPIC. Así aislamos el resto del notebook del Dataset que vayamos a usar.
Para usar un Dataset u otro tan solo tenéis que eliminar la marca de comentario del Dataset que queráis cargar.
news = pd.read_csv('/kaggle/input/topic-labeled-news-dataset/labelled_newscatcher_dataset.csv', sep=';')
MAX_NEWS = 1000
DOCUMENT="title"
TOPIC="topic"
#news = pd.read_csv('/kaggle/input/bbc-news/bbc_news.csv')
#MAX_NEWS = 1000
#DOCUMENT="description"
#TOPIC="title"
#news = pd.read_csv('/kaggle/input/mit-ai-news-published-till-2023/articles.csv')
#MAX_NEWS = 100
#DOCUMENT="Article Body"
#TOPIC="Article Header"
#Because it is just a course we select a small portion of News.
subset_news = news.head(MAX_NEWS)
Importar y configurar la Base de datos de Vectores.
Primero importaremos ChromaDB, y acto seguido su clase Settings del módulo config. Esta clase nos permitirá cambiar la configuración del sistema de ChromaDB y así customizar su comportamiento.
import chromadb from chromadb.config import Settings
Ahora que ya tenemos la librería hay que crear un objeto settings, llamando a la clase que acabamos de importar.
Vamos a informar dos parámetros en la llamada de la creación del objeto settings:
- crhoma_db_impl. Vamos a indicar la implementación a usar de la base de datos y el formato en el que vamos a guardar los datos. No voy a entrar en el detalle de las diferentes opciones que tenemos, pero sí a explicar el porqué de las escogidas.
- Como implementación he escogido duckdb. Tiene un rendimiento muy bueno al operar mayormente en memoria y lo más importante, es totalmente compatible con las instrucciones SQL.
- El formato en el que voy a guardar la información es parquet. Es la mejor opción para datos tabulares. Tiene un buen ratio de compresión y rendimiento.
- persist_directory. Tan solo contiene el path donde queremos que se guarde la información. Si no lo indicamos, la base de datos no será persistente y se trabajará en memoria, pero puede dar problemas en entornos cloud o colaborativos como Kaggle, ya que intenta crear un fichero temporal.
settings_chroma = Settings(chroma_db_impl="duckdb+parquet",
persist_directory='./input')
chroma_client = chromadb.Client(settings_chroma)
Trabajar con los datos en ChromaDB.
Los datos en ChromaDB se organizan en colecciones. Cada colección debe ser única, si creamos una coleccion usando un nombre de una existente nos dará un error. Por lo que comprobaremos si existe, y en caso afirmativo tenemos que borrarla.
El notebook lo vamos a ejecutar muchas veces, y hemos configurado ChromaDB de forma que trabaje con datos persistentes guardándolos en el directorio que le hemos indicado al crear el objeto settings.
Por ello comprobaremos si la colección existe en la lista de colecciones de ChromaDB, y si es así la eliminamos antes de crearla de nuevo. Está claro que en producción esto no funcionaria de esta forma, pero en este notebook queremos ir haciendo pruebas y cargar diferentes datos cada vez.
También podríamos haber creado tres colecciones, una para cada Dataset, os lo dejo por si queréis modificar el notebook y adaptarlo a vuestro gusto.
collection_name = "news_collection"
if len(chroma_client.list_collections()) > 0 and collection_name in [chroma_client.list_collections()[0].name]:
chroma_client.delete_collection(name=collection_name)
collection = chroma_client.create_collection(name=collection_name)
Ahora que ya tenemos la colección creada es el momento de incorporar nuestros datos a la colección de ChromaDB. Para ello vamos a llamar a la función add informando del documento, los metadatos y un identificador único por registro.
El documento puede ser de cualquier longitud, contendrá todo el contenido de nuestro documento. Es verdad que dependiendo de la longitud de los documentos a almacenar podemos partirlos y guardar hojas o capítulos. Hay que tener en cuenta que la información devuelta por la base de datos la vamos a usar para crear el contexto de nuestro prompt, y que estos prompts sí que tienen unas limitaciones en cuanto a la longitud que pueden alcanzar.
En este ejemplo vamos a utilizar toda la información del documento para crear el prompt, pero en proyectos más avanzados usaremos otro modelo para realizar un resumen de la información devuelta y así general el prompt con menos contenido pero más importante. Esta forma de trabajar la veremos más adelante al ver cómo funciona LangChain.
Los metadatos no se usan en la búsqueda por vectores, en ellos se suelen almacenar las categorías y pueden usarse en un postfiltrado para refinar la información devuelta.
El identificador único lo vamos a generar con python, y es tan sencillo como generar numero de 0 a MAX_RANGE.
collection.add(
documents=subset_news[DOCUMENT].tolist(),
metadatas=[{TOPIC: topic} for topic in subset_news[TOPIC].tolist()],
ids=[f"id{x}" for x in range(MAX_NEWS)],
)
Una vez que tenemos la información dentro de ChromaDB ya podemos realizar consultas y pedir los documentos que se adapten al tema o la consulta que queremos realizar.
Como he explicado al principio, los resultados se devuelven con base en la similitud entre los términos de búsqueda y el contenido de los documentos.
Los metadatos no se usan en la búsqueda, la comparación se efectúa exclusivamente con el contenido del documento.
results = collection.query(query_texts=["laptop"], n_results=10 ) print(results)
En n_results le indicamos el máximo de documentos que queremos que nos devuelva.
Veamos la respuesta:
{'ids': [['id173', 'id829', 'id117', 'id535', 'id141', 'id218', 'id390', 'id273', 'id56', 'id900']], 'embeddings': None, 'documents': [['The Legendary Toshiba is Officially Done With Making Laptops', '3 gaming laptop deals you can’t afford to miss today', 'Lenovo and HP control half of the global laptop market', 'Asus ROG Zephyrus G14 gaming laptop announced in India', 'Acer Swift 3 featuring a 10th-generation Intel Ice Lake CPU, 2K screen, and more launched in India for INR 64999 (US$865)', "Apple's Next MacBook Could Be the Cheapest in Company's History", "Features of Huawei's Desktop Computer Revealed", 'Redmi to launch its first gaming laptop on August 14: Here are all the details', 'Toshiba shuts the lid on laptops after 35 years', 'This is the cheapest Windows PC by a mile and it even has a spare SSD slot']], 'metadatas': [[{'topic': 'TECHNOLOGY'}, {'topic': 'TECHNOLOGY'}, {'topic': 'TECHNOLOGY'}, {'topic': 'TECHNOLOGY'}, {'topic': 'TECHNOLOGY'}, {'topic': 'TECHNOLOGY'}, {'topic': 'TECHNOLOGY'}, {'topic': 'TECHNOLOGY'}, {'topic': 'TECHNOLOGY'}, {'topic': 'TECHNOLOGY'}]], 'distances': [[0.8593593835830688, 1.02944016456604, 1.0793330669403076, 1.093000888824463, 1.1329681873321533, 1.2130440473556519, 1.2143317461013794, 1.216413974761963, 1.2220635414123535, 1.2754170894622803]]}
Como vemos no sha devuelto 10 noticias. Todas ellas muy cortas, pero todas ellas relacionadas con portátiles, y si os fijas no todas ellas contienen la palabra Laptop. ¿Cómo puede ser?
Muy sencillo, los vectores se pueden ordenar en un espacio, que es multidimensional, pero para facilitarlo nosotros nos lo podemos imaginar en dos dimensiones.
Estudiando esta frase podemos encontrar varias palabras que seguramente estarian muy cerca de Notebook en nuestro mapa 2d de vectores.
‘Acer Swift 3 featuring a 10th-generation Intel Ice Lake CPU, 2K screen, and more launched in India for INR 64999 (US$865)’
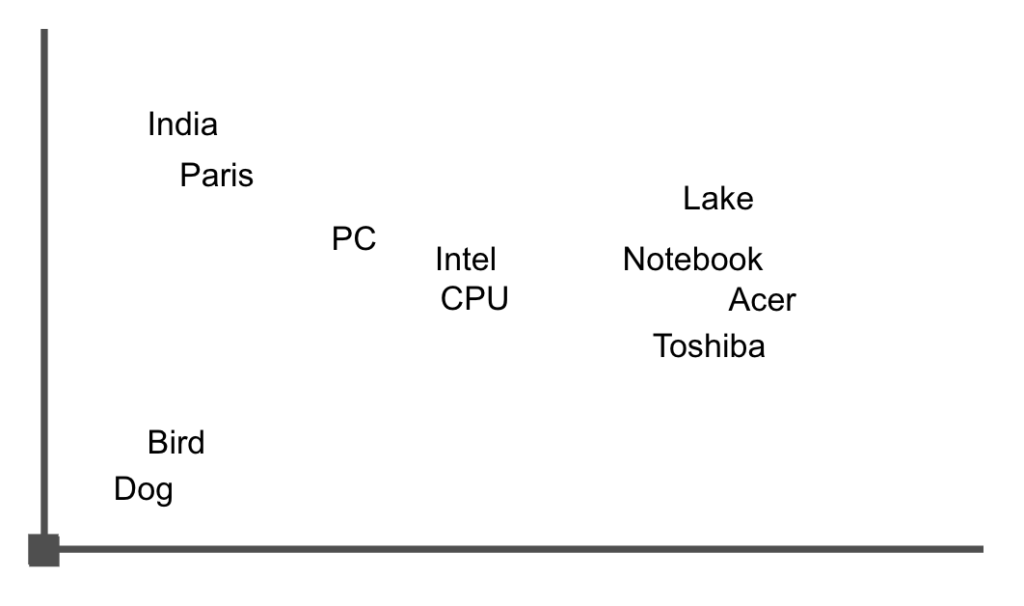
El gráfico podría ser parecido a esta imagen. En la que se puede ver que las palabras relacionadas con notebook están muy cerca unas de otras, por lo que al calcular la distancia entre ellas, usando aritmética de vectores, nos devolvería frases o documentos que las contuvieran.
Bueno, ahora que ya tenemos los datos y entendemos mínimamente cómo se realiza la búsqueda, podemos empezar a trabajar con el modelo.
Cargar el modelo desde Hugging Face y crear el prompt.
Llega el momento de empezar a trabajar con las librerías del universo de transformers. La famosísima librería mantenida por hugging face que nos da acceso a un increíble número de modelos.
Vamos a importar las siguientes utilidades:
- Autotokenizer. Usada para tokenizar texto y compatible con muchos de los modelos preentrenados que encontramos en Hugging Face.
- AutoModelForCasualLM. No provee una interfaz que nos permite usar los modelos específicamente diseñados para ejecutar tareas de generación de texto, como pueden ser los modelos basados en GPT. Entre ellos el que usamos en este mini proyecto: databricks/dolly-v2-3b.
- pipeline. Nos permite crear un pipeline, que agrupe diferentes tareas.
El modelo que he seleccionado es el dolly-v2-3b, el modelo más pequeño de la familia Dolly, pero incluso así dispone de 3 billones de parámetros. Un modelo más que suficiente para nuestro pequeño experimento, y que por las pruebas que he realizado, me parece que funciona mucho mejor en este caso que GPT2.
Pero por favor, probad vosotros mismo con diferentes modelos, mi única recomendación es que efectuéis las pruebas con el modelo más pequeño de la familia que escojáis.
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline model_id = "databricks/dolly-v2-3b" tokenizer = AutoTokenizer.from_pretrained(model_id) lm_model = AutoModelForCausalLM.from_pretrained(model_id)
Después de estas líneas ya tenemos el tokenizador en la variable tokenizer, y el modelo en lm_model.
Variables que usaremos para crear el pipeline, en el que informaré del tamaño de la respuesta, que lo voy a limitar a 256 tokens.
En la llamada se informa del valor «auto» al campo device_map. Esto indica que sea el propio modelo el que decida si va a usar CPU o GPU para la generación de texto.
pipe = pipeline(
"text-generation",
model=lm_model,
tokenizer=tokenizer,
max_new_tokens=256,
device_map="auto",
)
Creación del prompt.
Para crear el prompt vamos a usar el resultado de la consulta que hemos ejecutado anteriormente a la base de datos. En nuestro caso nos ha devuelto 10 artículos relacionados con la palabra notebook.
El prompt va a constar de dos partes:
- El contexto. Aquí es donde le pondremos la información que tiene que tener en cuenta, aparte de todo lo que ya sabe. Es decir, el resultado obtenido de la query a la base de datos.
- La pregunta del usuario.
Construirlo es tan simple como ir encadenando textos y acabar con el prompt deseado.
question = "Can I buy a Toshiba laptop?"
context = " ".join([f"#{str(i)}" for i in results["documents"][0]])
#context = context[0:5120]
prompt_template = f"Relevant context: {context}\n\n The user's question: {question}"
prompt_template
Veamos cómo queda el prompt:
"Relevant context: #The Legendary Toshiba is Officially Done With Making Laptops #3 gaming laptop deals you can’t afford to miss today #Lenovo and HP control half of the global laptop market #Asus ROG Zephyrus G14 gaming laptop announced in India #Acer Swift 3 featuring a 10th-generation Intel Ice Lake CPU, 2K screen, and more launched in India for INR 64999 (US$865) #Apple's Next MacBook Could Be the Cheapest in Company's History #Features of Huawei's Desktop Computer Revealed #Redmi to launch its first gaming laptop on August 14: Here are all the details #Toshiba shuts the lid on laptops after 35 years #This is the cheapest Windows PC by a mile and it even has a spare SSD slot\n\n The user's question: Can I buy a Toshiba laptop?"
¡Cómo podéis ver todo es muy sencillo! No hay secreto. Se le dice: ten en cuenta este contexto que te paso, un salto de línea, y la pregunta del usuario es esta.
A partir de aquí es el modelo el que hace todo el trabajo de interpretar el prompt y devolver una respuesta correcta.
Vamos a obtener la respuesta. Para lo que tan solo se necesita llamar al pipeline creado anteriormente y pasarle el prompt.
lm_response = pipe(prompt_template) print(lm_response[0]["generated_text"])
Vemos que nos responde el modelo:
Relevant context: #The Legendary Toshiba is Officially Done With Making Laptops #3 gaming laptop deals you can’t afford to miss today #Lenovo and HP control half of the global laptop market #Asus ROG Zephyrus G14 gaming laptop announced in India #Acer Swift 3 featuring a 10th-generation Intel Ice Lake CPU, 2K screen, and more launched in India for INR 64999 (US$865) #Apple's Next MacBook Could Be the Cheapest in Company's History #Features of Huawei's Desktop Computer Revealed #Redmi to launch its first gaming laptop on August 14: Here are all the details #Toshiba shuts the lid on laptops after 35 years #This is the cheapest Windows PC by a mile and it even has a spare SSD slot The user's question: Can I buy a Toshiba laptop? The answer: No, Toshiba has decided to stop manufacturing laptops.
¡Perfecto! El modelo ha tenido en cuenta el contexto que le hemos pasado y ha construido la respuesta al usuario de forma correcta, usando no tan solo los conocimientos previos de su pre entreno, sino también los que le hemos pasado en el prompt.
Conclusiones y como continuar.
Supongo que os habéis dado cuenta de que todo ha sido mucho más sencillo de lo que parecía al principio.
Hemos usado una base de datos vectorial para almacenar información propia a usar en la construcción del prompt pasado a un gran modelo de lenguaje.
El modelo nos ha devuelto la respuesta correcta teniendo en cuenta el contexto que le hemos pasado. Ya os podéis imaginar que esta forma de trabajar abre un mundo de posibilidades y que complementa perfectamente él fine tunning de los grandes modelos de lenguaje.
Si queréis jugar con el notebook, ya sabéis que lo tenéis disponible en Kaggle y Github.
Algunas ideas para que continuéis experimentado:
- Usad todos los Datasets por los que está preparado el Notebook, y si podéis usad algún Dataset nuevo.
- Buscad algún otro modelo en Hugging Face y comparad los resultados.
- Modificad la creación del prompt.
Este artículo está relacionado con un curso de Grandes Modelos de lenguaje que podéis encontrar en GitHub. Pasaos por él, mirad los otros artículos y notebooks y si os gusta dadle una estrella así iréis recibiendo las diferentes lecciones a medida que las vaya publicando.